 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaDecorator: Generating Immersive Virtual Tours through Multimodality
Jan 27, 2025



MetaDecorator, is a framework that empowers users to personalize virtual spaces. By leveraging text-driven prompts and image synthesis techniques, MetaDecorator adorns static panoramas captured by 360{\deg} imaging devices, transforming them into uniquely styled and visually appealing environments. This significantly enhances the realism and engagement of virtual tours compared to traditional offerings. Beyond the core framework, we also discuss the integration of Large Language Models (LLMs) and haptics in the VR application to provide a more immersive experience.
MADRL-Based Rate Adaptation for 360$\degree$ Video Streaming with Multi-Viewpoint Prediction
May 13, 2024Over the last few years, 360$\degree$ video traffic on the network has grown significantly. A key challenge of 360$\degree$ video playback is ensuring a high quality of experience (QoE) with limited network bandwidth. Currently, most studies focus on tile-based adaptive bitrate (ABR) streaming based on single viewport prediction to reduce bandwidth consumption. However, the performance of models for single-viewpoint prediction is severely limited by the inherent uncertainty in head movement, which can not cope with the sudden movement of users very well. This paper first presents a multimodal spatial-temporal attention transformer to generate multiple viewpoint trajectories with their probabilities given a historical trajectory. The proposed method models viewpoint prediction as a classification problem and uses attention mechanisms to capture the spatial and temporal characteristics of input video frames and viewpoint trajectories for multi-viewpoint prediction. After that, a multi-agent deep reinforcement learning (MADRL)-based ABR algorithm utilizing multi-viewpoint prediction for 360$\degree$ video streaming is proposed for maximizing different QoE objectives under various network conditions. We formulate the ABR problem as a decentralized partially observable Markov decision process (Dec-POMDP) problem and present a MAPPO algorithm based on centralized training and decentralized execution (CTDE) framework to solve the problem. The experimental results show that our proposed method improves the defined QoE metric by up to 85.5\% compared to existing ABR methods.
Bringing Robots Home: The Rise of AI Robots in Consumer Electronics
Mar 21, 2024On March 18, 2024, NVIDIA unveiled Project GR00T, a general-purpose multimodal generative AI model designed specifically for training humanoid robots. Preceding this event, Tesla's unveiling of the Optimus Gen 2 humanoid robot on December 12, 2023, underscored the profound impact robotics is poised to have on reshaping various facets of our daily lives. While robots have long dominated industrial settings, their presence within our homes is a burgeoning phenomenon. This can be attributed, in part, to the complexities of domestic environments and the challenges of creating robots that can seamlessly integrate into our daily routines.
Human-Centric Resource Allocation for the Metaverse With Multiaccess Edge Computing
Dec 23, 2023Multi-access edge computing (MEC) is a promising solution to the computation-intensive, low-latency rendering tasks of the metaverse. However, how to optimally allocate limited communication and computation resources at the edge to a large number of users in the metaverse is quite challenging. In this paper, we propose an adaptive edge resource allocation method based on multi-agent soft actor-critic with graph convolutional networks (SAC-GCN). Specifically, SAC-GCN models the multi-user metaverse environment as a graph where each agent is denoted by a node. Each agent learns the interplay between agents by graph convolutional networks with self-attention mechanism to further determine the resource usage for one user in the metaverse. The effectiveness of SAC-GCN is demonstrated through the analysis of user experience, balance of resource allocation, and resource utilization rate by taking a virtual city park metaverse as an example. Experimental results indicate that SAC-GCN outperforms other resource allocation methods in improving overall user experience, balancing resource allocation, and increasing resource utilization rate by at least 27%, 11%, and 8%, respectively.
A Deep Reinforcement Learning Framework for Optimizing Congestion Control in Data Centers
Jan 29, 2023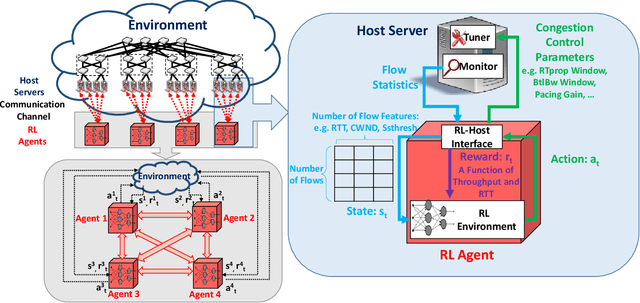
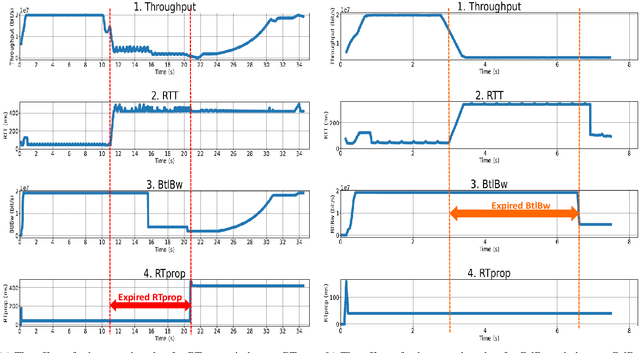
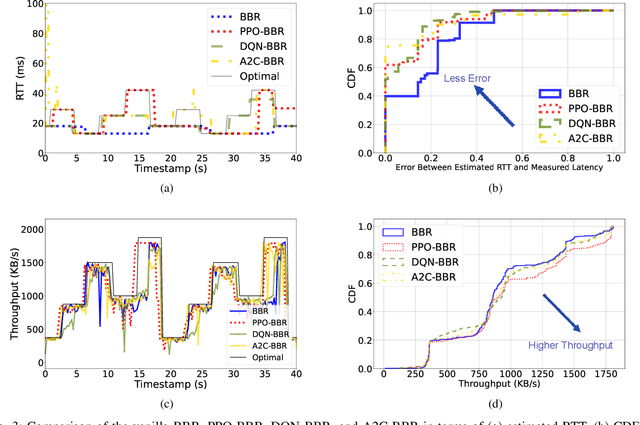
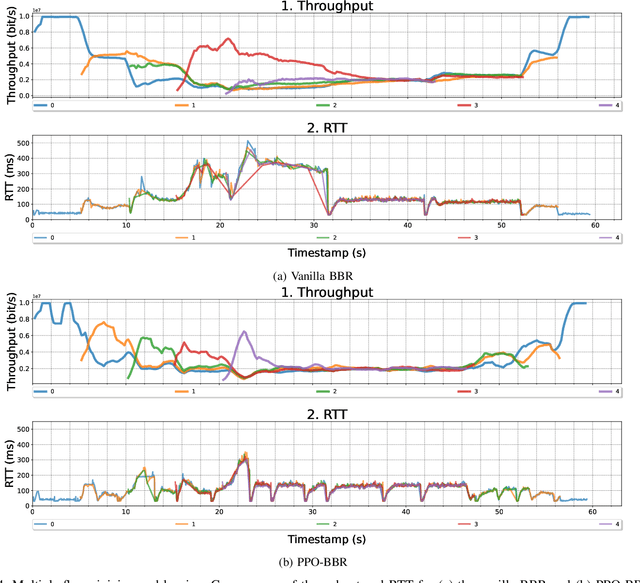
Various congestion control protocols have been designed to achieve high performance in different network environments. Modern online learning solutions that delegate the congestion control actions to a machine cannot properly converge in the stringent time scales of data centers. We leverage multiagent reinforcement learning to design a system for dynamic tuning of congestion control parameters at end-hosts in a data center. The system includes agents at the end-hosts to monitor and report the network and traffic states, and agents to run the reinforcement learning algorithm given the states. Based on the state of the environment, the system generates congestion control parameters that optimize network performance metrics such as throughput and latency. As a case study, we examine BBR, an example of a prominent recently-developed congestion control protocol. Our experiments demonstrate that the proposed system has the potential to mitigate the problems of static parameters.
Development of an automatic 3D human head scanning-printing system
Dec 26, 2022Three-dimensional (3D) technologies have been developing rapidly recent years, and have influenced industrial, medical, cultural, and many other fields. In this paper, we introduce an automatic 3D human head scanning-printing system, which provides a complete pipeline to scan, reconstruct, select, and finally print out physical 3D human heads. To enhance the accuracy of our system, we developed a consumer-grade composite sensor (including a gyroscope, an accelerometer, a digital compass, and a Kinect v2 depth sensor) as our sensing device. This sensing device is then mounted on a robot, which automatically rotates around the human subject with approximate 1-meter radius, to capture the full-view information. The data streams are further processed and fused into a 3D model of the subject using a tablet located on the robot. In addition, an automatic selection method, based on our specific system configurations, is proposed to select the head portion. We evaluated the accuracy of the proposed system by comparing our generated 3D head models, from both standard human head model and real human subjects, with the ones reconstructed from FastSCAN and Cyberware commercial laser scanning systems through computing and visualizing Hausdorff distances. Computational cost is also provided to further assess our proposed system.
Learning to Estimate 3D Human Pose from Point Cloud
Dec 25, 20223D pose estimation is a challenging problem in computer vision. Most of the existing neural-network-based approaches address color or depth images through convolution networks (CNNs). In this paper, we study the task of 3D human pose estimation from depth images. Different from the existing CNN-based human pose estimation method, we propose a deep human pose network for 3D pose estimation by taking the point cloud data as input data to model the surface of complex human structures. We first cast the 3D human pose estimation from 2D depth images to 3D point clouds and directly predict the 3D joint position. Our experiments on two public datasets show that our approach achieves higher accuracy than previous state-of-art methods. The reported results on both ITOP and EVAL datasets demonstrate the effectiveness of our method on the targeted tasks.
Sitting Posture Recognition Using a Spiking Neural Network
Dec 25, 2022



To increase the quality of citizens' lives, we designed a personalized smart chair system to recognize sitting behaviors. The system can receive surface pressure data from the designed sensor and provide feedback for guiding the user towards proper sitting postures. We used a liquid state machine and a logistic regression classifier to construct a spiking neural network for classifying 15 sitting postures. To allow this system to read our pressure data into the spiking neurons, we designed an algorithm to encode map-like data into cosine-rank sparsity data. The experimental results consisting of 15 sitting postures from 19 participants show that the prediction precision of our SNN is 88.52%.
Development of a Self-Calibrated Motion Capture System by Nonlinear Trilateration of Multiple Kinects v2
Dec 25, 2022In this paper, a Kinect-based distributed and real-time motion capture system is developed. A trigonometric method is applied to calculate the relative position of Kinect v2 sensors with a calibration wand and register the sensors' positions automatically. By combining results from multiple sensors with a nonlinear least square method, the accuracy of the motion capture is optimized. Moreover, to exclude inaccurate results from sensors, a computational geometry is applied in the occlusion approach, which discovers occluded joint data. The synchronization approach is based on an NTP protocol that synchronizes the time between the clocks of a server and clients dynamically, ensuring that the proposed system is a real-time system. Experiments for validating the proposed system are conducted from the perspective of calibration, occlusion, accuracy, and efficiency. Furthermore, to demonstrate the practical performance of our system, a comparison of previously developed motion capture systems (the linear trilateration approach and the geometric trilateration approach) with the benchmark OptiTrack system is conducted, therein showing that the accuracy of our proposed system is $38.3\%$ and 24.1% better than the two aforementioned trilateration systems, respectively.
EVM-CNN: Real-Time Contactless Heart Rate Estimation from Facial Video
Dec 25, 2022With the increase in health consciousness, noninvasive body monitoring has aroused interest among researchers. As one of the most important pieces of physiological information, researchers have remotely estimated the heart rate (HR) from facial videos in recent years. Although progress has been made over the past few years, there are still some limitations, like the processing time increasing with accuracy and the lack of comprehensive and challenging datasets for use and comparison. Recently, it was shown that HR information can be extracted from facial videos by spatial decomposition and temporal filtering. Inspired by this, a new framework is introduced in this paper to remotely estimate the HR under realistic conditions by combining spatial and temporal filtering and a convolutional neural network. Our proposed approach shows better performance compared with the benchmark on the MMSE-HR dataset in terms of both the average HR estimation and short-time HR estimation. High consistency in short-time HR estimation is observed between our method and the ground truth.