 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUET -- Dual User Embedding Transformers for Offsite Conversion Prediction
Jun 08, 2026Offsite conversion rate (OCVR) prediction is an important ranking problem in computational recommendation systems. This task presents a modeling challenge: click signals are abundant and exhibit short temporal horizons, whereas conversion signals are inherently sparse, long-delayed, and frequently unattributed. Despite these statistical disparities, both signal types must inform models that operate within strict serving-latency constraints. Prior pre-training approaches address this heterogeneity with a single, undifferentiated encoder applied uniformly across both data streams. We propose DUET (Dual User Embedding Transformers), a framework that explicitly partitions user behavioral data into two domain-coherent streams -- clicks and conversions -- and pre-trains dedicated transformer encoders with architectures tailored to each stream's statistical characteristics: multi-layer self-attention for the dense click stream and interleaved cross- and self-attention for the sparse conversion stream. The resulting complementary embeddings are jointly consumed by a downstream ranker without exceeding serving-latency budgets. Evaluation demonstrates up to 0.38% normalized entropy (NE) reduction relative to the strongest baseline, and A/B test shows consistent improvements in OCVR prediction accuracy.
SGUQ: Staged Graph Convolution Neural Network for Alzheimer's Disease Diagnosis using Multi-Omics Data
Oct 14, 2024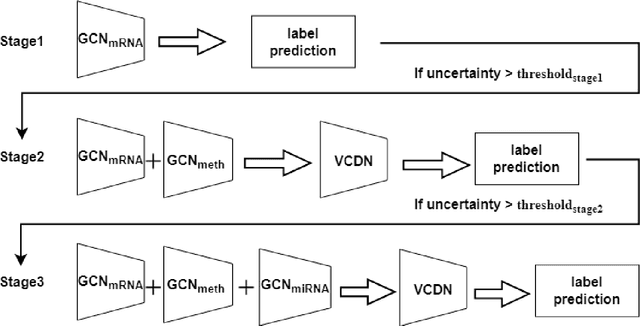

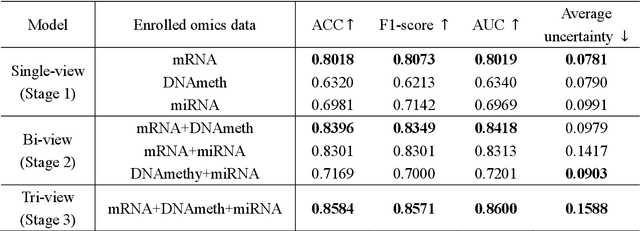
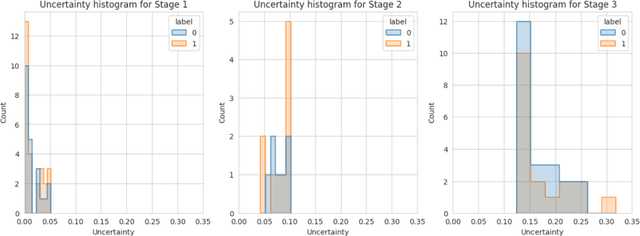
Alzheimer's disease (AD) is a chronic neurodegenerative disorder and the leading cause of dementia, significantly impacting cost, mortality, and burden worldwide. The advent of high-throughput omics technologies, such as genomics, transcriptomics, proteomics, and epigenomics, has revolutionized the molecular understanding of AD. Conventional AI approaches typically require the completion of all omics data at the outset to achieve optimal AD diagnosis, which are inefficient and may be unnecessary. To reduce the clinical cost and improve the accuracy of AD diagnosis using multi-omics data, we propose a novel staged graph convolutional network with uncertainty quantification (SGUQ). SGUQ begins with mRNA and progressively incorporates DNA methylation and miRNA data only when necessary, reducing overall costs and exposure to harmful tests. Experimental results indicate that 46.23% of the samples can be reliably predicted using only single-modal omics data (mRNA), while an additional 16.04% of the samples can achieve reliable predictions when combining two omics data types (mRNA + DNA methylation). In addition, the proposed staged SGUQ achieved an accuracy of 0.858 on ROSMAP dataset, which outperformed existing methods significantly. The proposed SGUQ can not only be applied to AD diagnosis using multi-omics data but also has the potential for clinical decision-making using multi-viewed data. Our implementation is publicly available at https://github.com/chenzhao2023/multiomicsuncertainty.
Advancing Biomedical Text Mining with Community Challenges
Mar 07, 2024The field of biomedical research has witnessed a significant increase in the accumulation of vast amounts of textual data from various sources such as scientific literatures, electronic health records, clinical trial reports, and social media. However, manually processing and analyzing these extensive and complex resources is time-consuming and inefficient. To address this challenge, biomedical text mining, also known as biomedical natural language processing, has garnered great attention. Community challenge evaluation competitions have played an important role in promoting technology innovation and interdisciplinary collaboration in biomedical text mining research. These challenges provide platforms for researchers to develop state-of-the-art solutions for data mining and information processing in biomedical research. In this article, we review the recent advances in community challenges specific to Chinese biomedical text mining. Firstly, we collect the information of these evaluation tasks, such as data sources and task types. Secondly, we conduct systematic summary and comparative analysis, including named entity recognition, entity normalization, attribute extraction, relation extraction, event extraction, text classification, text similarity, knowledge graph construction, question answering, text generation, and large language model evaluation. Then, we summarize the potential clinical applications of these community challenge tasks from translational informatics perspective. Finally, we discuss the contributions and limitations of these community challenges, while highlighting future directions in the era of large language models.
Combating Uncertainty and Class Imbalance in Facial Expression Recognition
Dec 15, 2022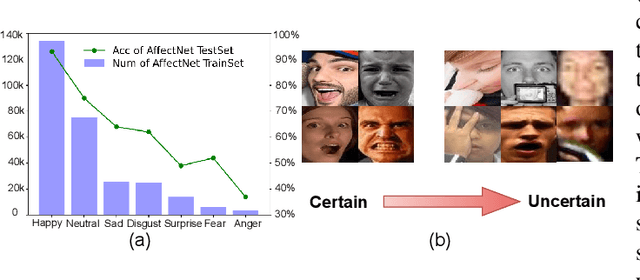
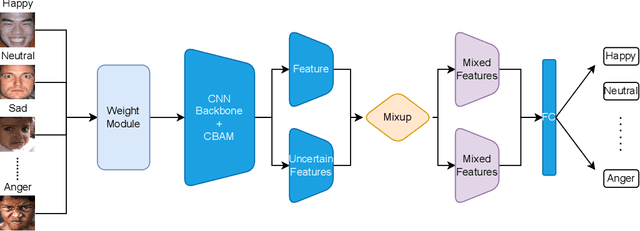
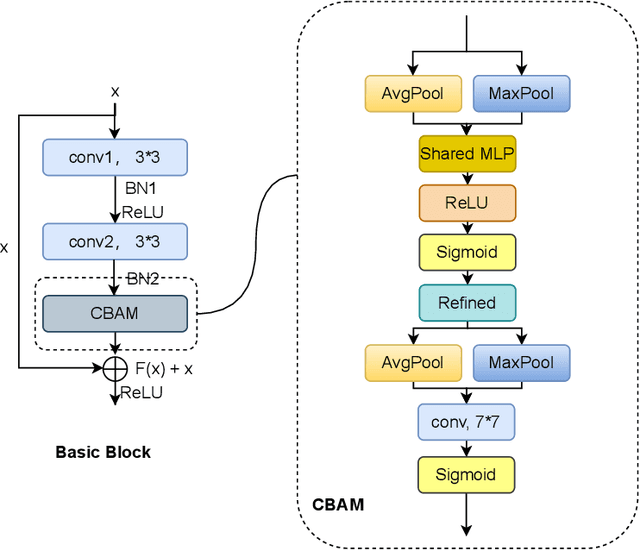
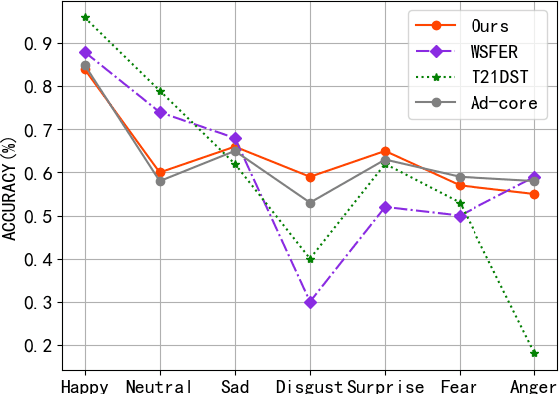
Recognition of facial expression is a challenge when it comes to computer vision. The primary reasons are class imbalance due to data collection and uncertainty due to inherent noise such as fuzzy facial expressions and inconsistent labels. However, current research has focused either on the problem of class imbalance or on the problem of uncertainty, ignoring the intersection of how to address these two problems. Therefore, in this paper, we propose a framework based on Resnet and Attention to solve the above problems. We design weight for each class. Through the penalty mechanism, our model will pay more attention to the learning of small samples during training, and the resulting decrease in model accuracy can be improved by a Convolutional Block Attention Module (CBAM). Meanwhile, our backbone network will also learn an uncertain feature for each sample. By mixing uncertain features between samples, the model can better learn those features that can be used for classification, thus suppressing uncertainty. Experiments show that our method surpasses most basic methods in terms of accuracy on facial expression data sets (e.g., AffectNet, RAF-DB), and it also solves the problem of class imbalance well.
Multi-Scale Feature Fusion Transformer Network for End-to-End Single Channel Speech Separation
Dec 14, 2022Recently studies on time-domain audio separation networks (TasNets) have made a great stride in speech separation. One of the most representative TasNets is a network with a dual-path segmentation approach. However, the original model called DPRNN used a fixed feature dimension and unchanged segment size throughout all layers of the network. In this paper, we propose a multi-scale feature fusion transformer network (MSFFT-Net) based on the conventional dual-path structure for single-channel speech separation. Unlike the conventional dual-path structure where only one processing path exists, adopting several iterative blocks with alternative intra-chunk and inter-chunk operations to capture local and global context information, the proposed MSFFT-Net has multiple parallel processing paths where the feature information can be exchanged between multiple parallel processing paths. Experiments show that our proposed networks based on multi-scale feature fusion structure have achieved better results than the original dual-path model on the benchmark dataset-WSJ0-2mix, where the SI-SNRi score of MSFFT-3P is 20.7dB (1.47% improvement), and MSFFT-2P is 21.0dB (3.45% improvement), which achieves SOTA on WSJ0-2mix without any data augmentation method.
CycleGAN with Dual Adversarial Loss for Bone-Conducted Speech Enhancement
Nov 02, 2021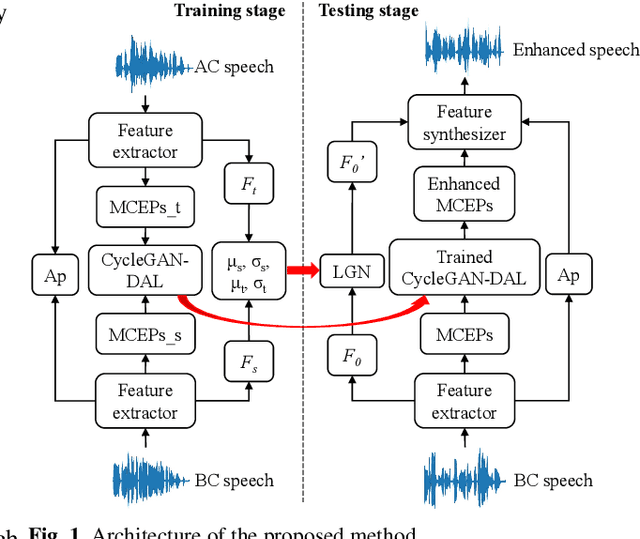
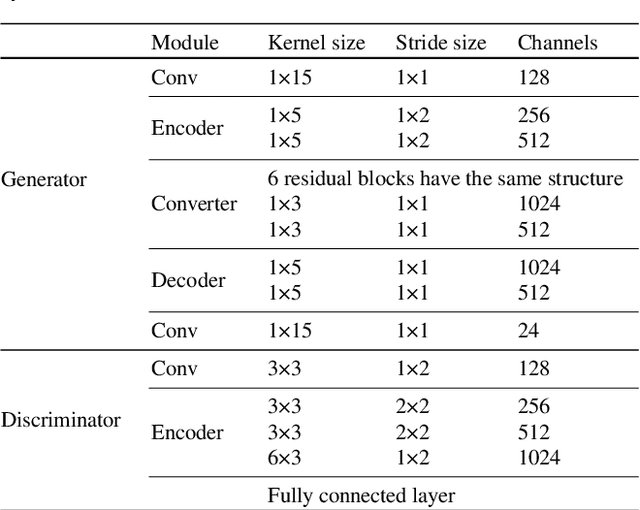
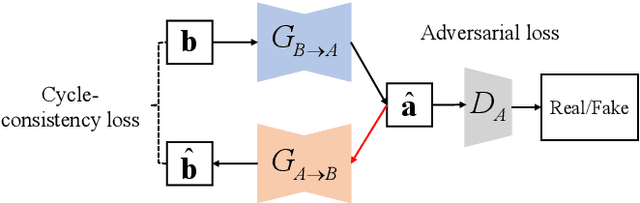

Compared with air-conducted speech, bone-conducted speech has the unique advantage of shielding background noise. Enhancement of bone-conducted speech helps to improve its quality and intelligibility. In this paper, a novel CycleGAN with dual adversarial loss (CycleGAN-DAL) is proposed for bone-conducted speech enhancement. The proposed method uses an adversarial loss and a cycle-consistent loss simultaneously to learn forward and cyclic mapping, in which the adversarial loss is replaced with the classification adversarial loss and the defect adversarial loss to consolidate the forward mapping. Compared with conventional baseline methods, it can learn feature mapping between bone-conducted speech and target speech without additional air-conducted speech assistance. Moreover, the proposed method also avoids the oversmooth problem which is occurred commonly in conventional statistical based models. Experimental results show that the proposed method outperforms baseline methods such as CycleGAN, GMM, and BLSTM. Keywords: Bone-conducted speech enhancement, dual adversarial loss, Parallel CycleGAN, high frequency speech reconstruction
Attention-Guided Generative Adversarial Network for Whisper to Normal Speech Conversion
Nov 02, 2021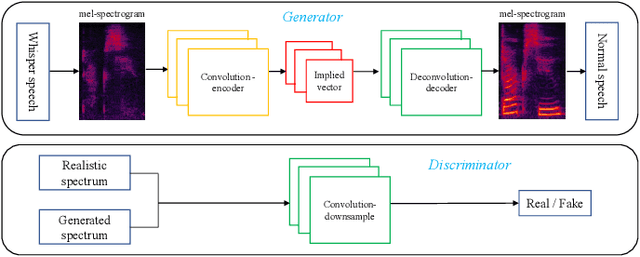
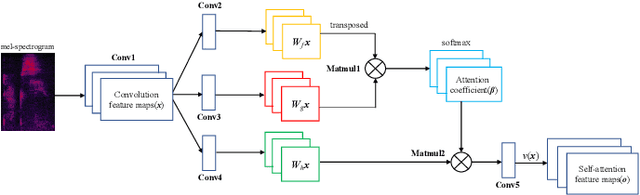
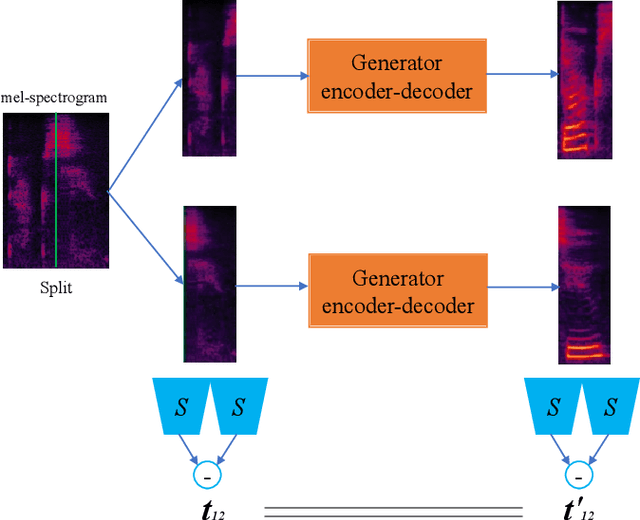
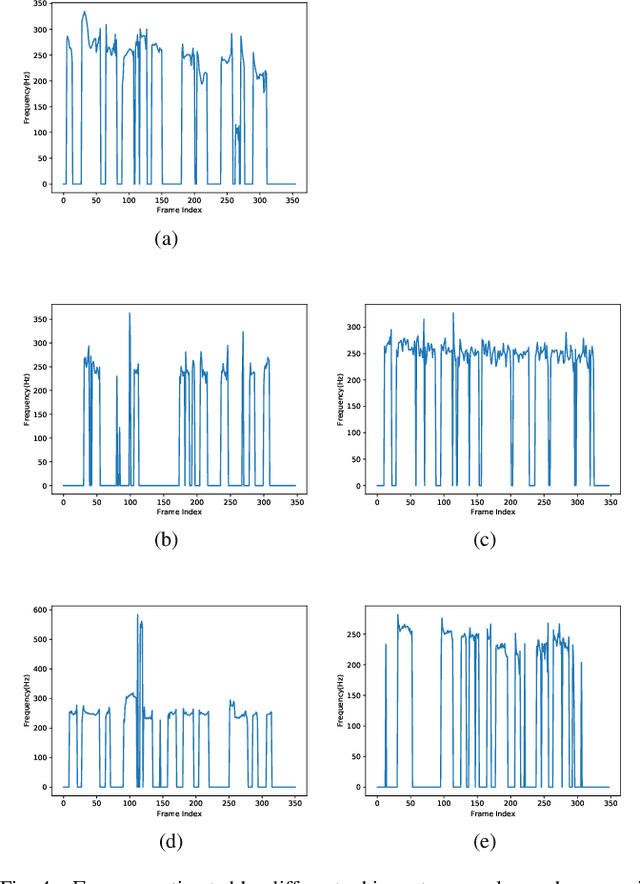
Whispered speech is a special way of pronunciation without using vocal cord vibration. A whispered speech does not contain a fundamental frequency, and its energy is about 20dB lower than that of a normal speech. Converting a whispered speech into a normal speech can improve speech quality and intelligibility. In this paper, a novel attention-guided generative adversarial network model incorporating an autoencoder, a Siamese neural network, and an identity mapping loss function for whisper to normal speech conversion (AGAN-W2SC) is proposed. The proposed method avoids the challenge of estimating the fundamental frequency of the normal voiced speech converted from a whispered speech. Specifically, the proposed model is more amendable to practical applications because it does not need to align speech features for training. Experimental results demonstrate that the proposed AGAN-W2SC can obtain improved speech quality and intelligibility compared with dynamic-time-warping-based methods.
Multistage Model for Robust Face Alignment Using Deep Neural Networks
Feb 04, 2020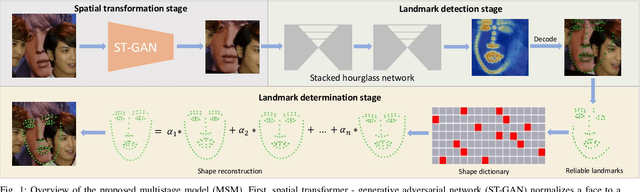

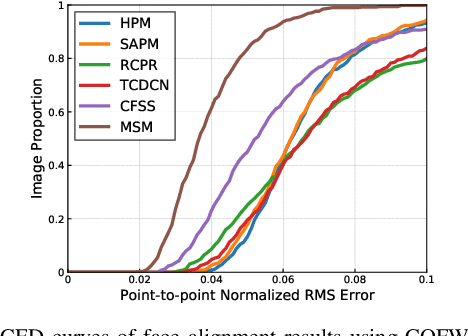

An ability to generalize unconstrained conditions such as severe occlusions and large pose variations remains a challenging goal to achieve in face alignment. In this paper, a multistage model based on deep neural networks is proposed which takes advantage of spatial transformer networks, hourglass networks and exemplar-based shape constraints. First, a spatial transformer - generative adversarial network which consists of convolutional layers and residual units is utilized to solve the initialization issues caused by face detectors, such as rotation and scale variations, to obtain improved face bounding boxes for face alignment. Then, stacked hourglass network is employed to obtain preliminary locations of landmarks as well as their corresponding scores. In addition, an exemplar-based shape dictionary is designed to determine landmarks with low scores based on those with high scores. By incorporating face shape constraints, misaligned landmarks caused by occlusions or cluttered backgrounds can be considerably improved. Extensive experiments based on challenging benchmark datasets are performed to demonstrate the superior performance of the proposed method over other state-of-the-art methods.