 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Biomedical Text Mining with Community Challenges
Mar 07, 2024The field of biomedical research has witnessed a significant increase in the accumulation of vast amounts of textual data from various sources such as scientific literatures, electronic health records, clinical trial reports, and social media. However, manually processing and analyzing these extensive and complex resources is time-consuming and inefficient. To address this challenge, biomedical text mining, also known as biomedical natural language processing, has garnered great attention. Community challenge evaluation competitions have played an important role in promoting technology innovation and interdisciplinary collaboration in biomedical text mining research. These challenges provide platforms for researchers to develop state-of-the-art solutions for data mining and information processing in biomedical research. In this article, we review the recent advances in community challenges specific to Chinese biomedical text mining. Firstly, we collect the information of these evaluation tasks, such as data sources and task types. Secondly, we conduct systematic summary and comparative analysis, including named entity recognition, entity normalization, attribute extraction, relation extraction, event extraction, text classification, text similarity, knowledge graph construction, question answering, text generation, and large language model evaluation. Then, we summarize the potential clinical applications of these community challenge tasks from translational informatics perspective. Finally, we discuss the contributions and limitations of these community challenges, while highlighting future directions in the era of large language models.
CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark
Jul 06, 2021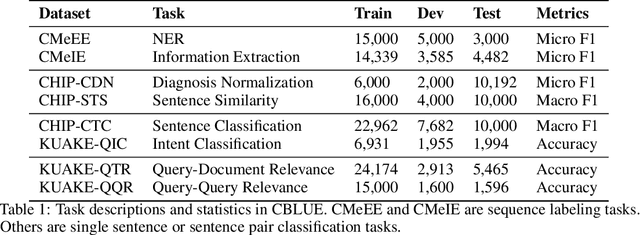
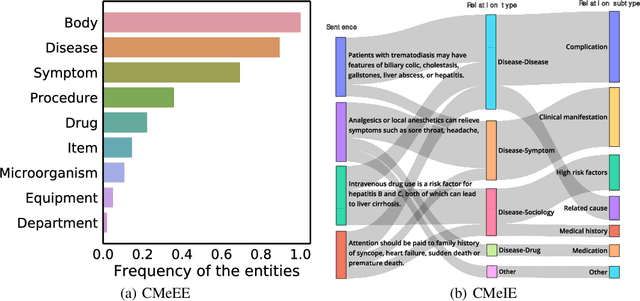
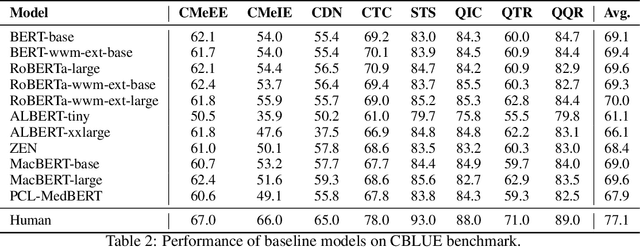
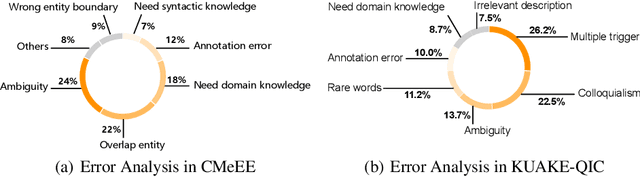
Artificial Intelligence (AI), along with the recent progress in biomedical language understanding, is gradually changing medical practice. With the development of biomedical language understanding benchmarks, AI applications are widely used in the medical field. However, most benchmarks are limited to English, which makes it challenging to replicate many of the successes in English for other languages. To facilitate research in this direction, we collect real-world biomedical data and present the first Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark: a collection of natural language understanding tasks including named entity recognition, information extraction, clinical diagnosis normalization, single-sentence/sentence-pair classification, and an associated online platform for model evaluation, comparison, and analysis. To establish evaluation on these tasks, we report empirical results with the current 11 pre-trained Chinese models, and experimental results show that state-of-the-art neural models perform by far worse than the human ceiling. Our benchmark is released at \url{https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414&lang=en-us}.