 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Uncertainty and Class Imbalance in Facial Expression Recognition
Dec 15, 2022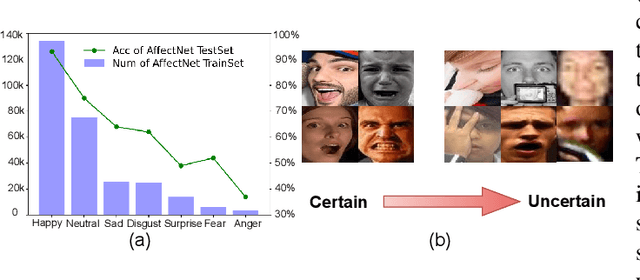
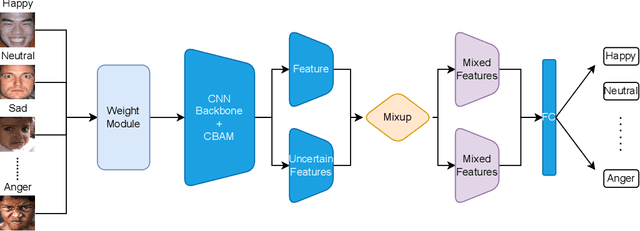
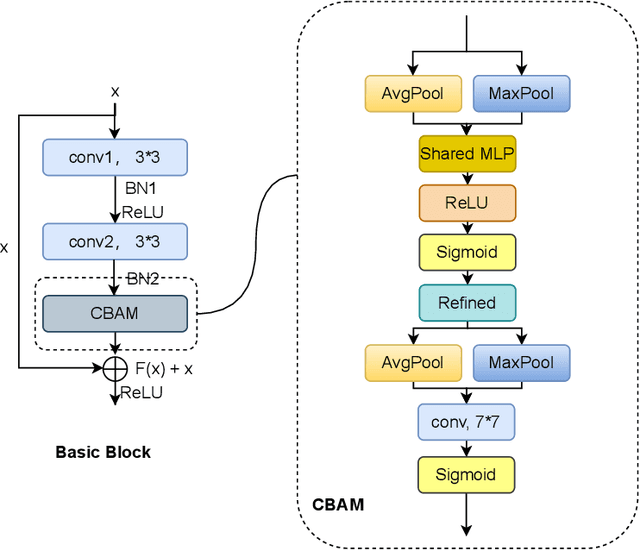
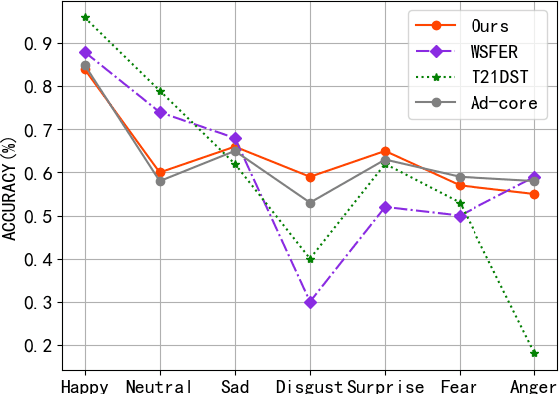
Recognition of facial expression is a challenge when it comes to computer vision. The primary reasons are class imbalance due to data collection and uncertainty due to inherent noise such as fuzzy facial expressions and inconsistent labels. However, current research has focused either on the problem of class imbalance or on the problem of uncertainty, ignoring the intersection of how to address these two problems. Therefore, in this paper, we propose a framework based on Resnet and Attention to solve the above problems. We design weight for each class. Through the penalty mechanism, our model will pay more attention to the learning of small samples during training, and the resulting decrease in model accuracy can be improved by a Convolutional Block Attention Module (CBAM). Meanwhile, our backbone network will also learn an uncertain feature for each sample. By mixing uncertain features between samples, the model can better learn those features that can be used for classification, thus suppressing uncertainty. Experiments show that our method surpasses most basic methods in terms of accuracy on facial expression data sets (e.g., AffectNet, RAF-DB), and it also solves the problem of class imbalance well.
CycleGAN with Dual Adversarial Loss for Bone-Conducted Speech Enhancement
Nov 02, 2021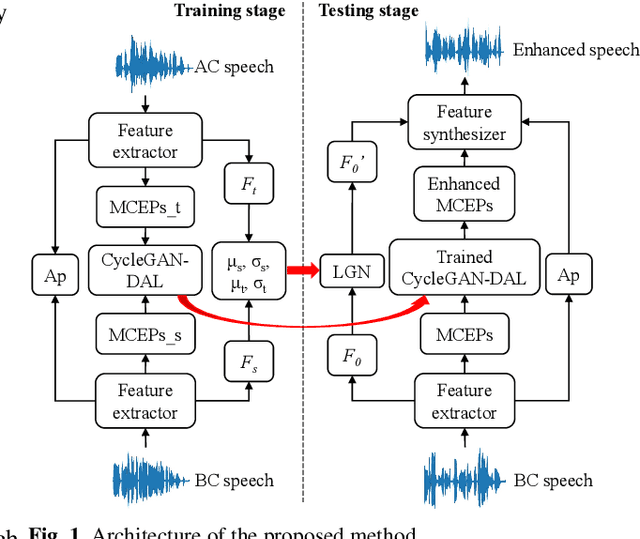
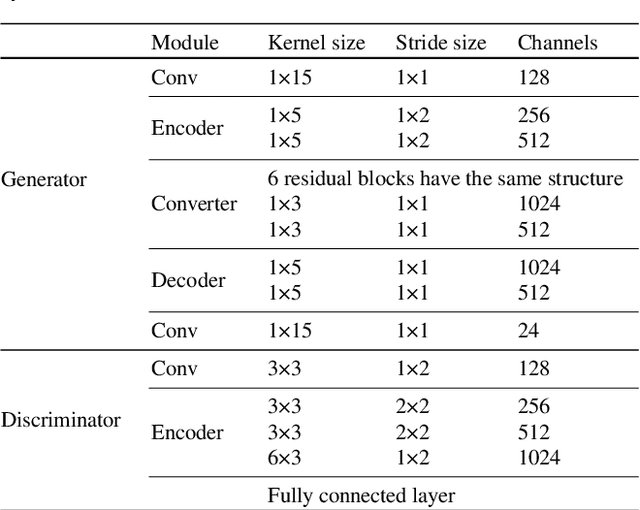
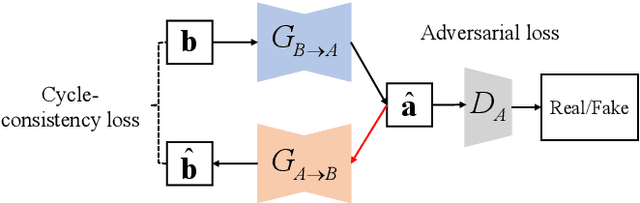

Compared with air-conducted speech, bone-conducted speech has the unique advantage of shielding background noise. Enhancement of bone-conducted speech helps to improve its quality and intelligibility. In this paper, a novel CycleGAN with dual adversarial loss (CycleGAN-DAL) is proposed for bone-conducted speech enhancement. The proposed method uses an adversarial loss and a cycle-consistent loss simultaneously to learn forward and cyclic mapping, in which the adversarial loss is replaced with the classification adversarial loss and the defect adversarial loss to consolidate the forward mapping. Compared with conventional baseline methods, it can learn feature mapping between bone-conducted speech and target speech without additional air-conducted speech assistance. Moreover, the proposed method also avoids the oversmooth problem which is occurred commonly in conventional statistical based models. Experimental results show that the proposed method outperforms baseline methods such as CycleGAN, GMM, and BLSTM. Keywords: Bone-conducted speech enhancement, dual adversarial loss, Parallel CycleGAN, high frequency speech reconstruction
Attention-Guided Generative Adversarial Network for Whisper to Normal Speech Conversion
Nov 02, 2021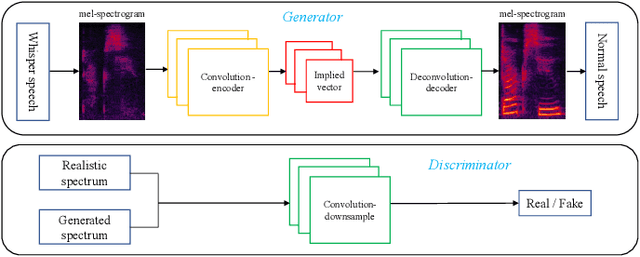
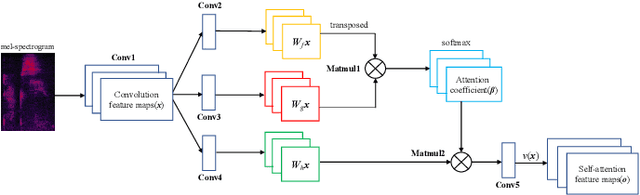
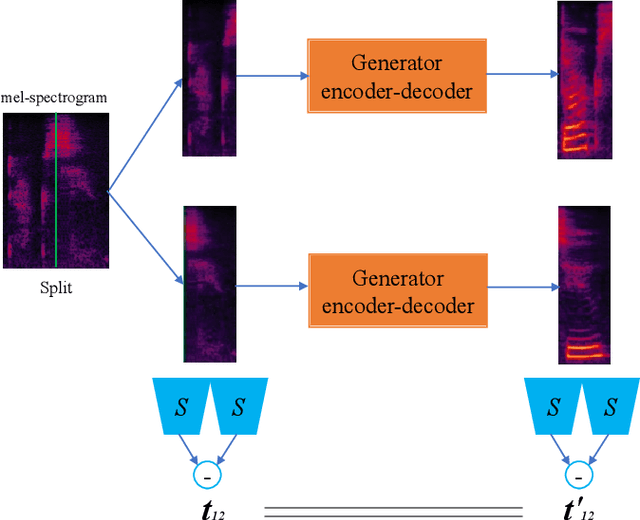
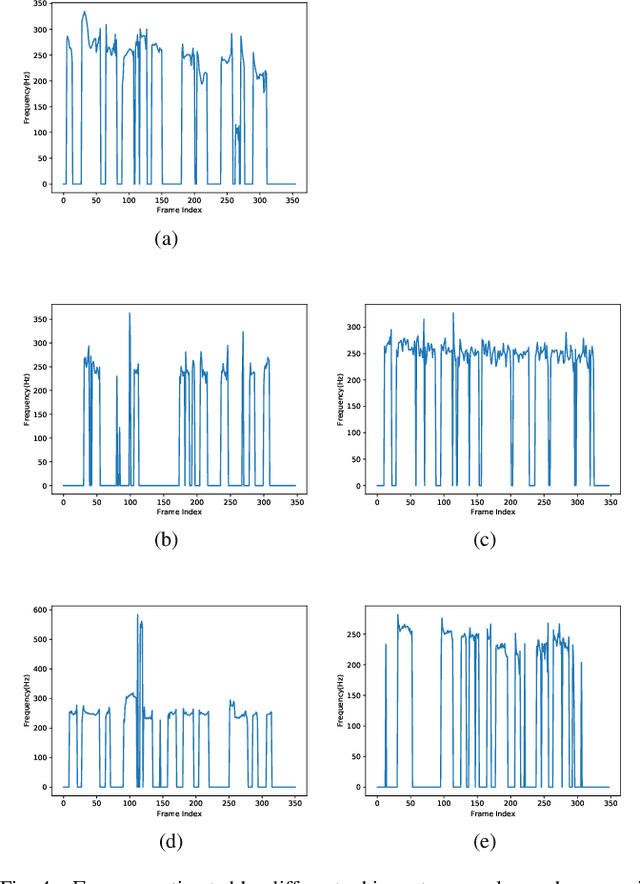
Whispered speech is a special way of pronunciation without using vocal cord vibration. A whispered speech does not contain a fundamental frequency, and its energy is about 20dB lower than that of a normal speech. Converting a whispered speech into a normal speech can improve speech quality and intelligibility. In this paper, a novel attention-guided generative adversarial network model incorporating an autoencoder, a Siamese neural network, and an identity mapping loss function for whisper to normal speech conversion (AGAN-W2SC) is proposed. The proposed method avoids the challenge of estimating the fundamental frequency of the normal voiced speech converted from a whispered speech. Specifically, the proposed model is more amendable to practical applications because it does not need to align speech features for training. Experimental results demonstrate that the proposed AGAN-W2SC can obtain improved speech quality and intelligibility compared with dynamic-time-warping-based methods.
Multistage Model for Robust Face Alignment Using Deep Neural Networks
Feb 04, 2020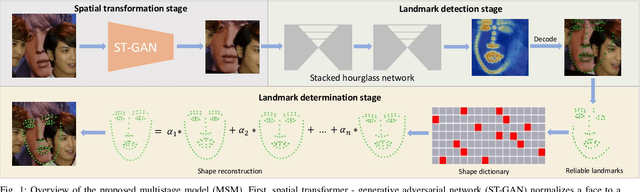

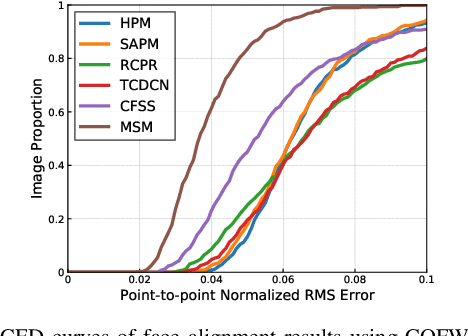

An ability to generalize unconstrained conditions such as severe occlusions and large pose variations remains a challenging goal to achieve in face alignment. In this paper, a multistage model based on deep neural networks is proposed which takes advantage of spatial transformer networks, hourglass networks and exemplar-based shape constraints. First, a spatial transformer - generative adversarial network which consists of convolutional layers and residual units is utilized to solve the initialization issues caused by face detectors, such as rotation and scale variations, to obtain improved face bounding boxes for face alignment. Then, stacked hourglass network is employed to obtain preliminary locations of landmarks as well as their corresponding scores. In addition, an exemplar-based shape dictionary is designed to determine landmarks with low scores based on those with high scores. By incorporating face shape constraints, misaligned landmarks caused by occlusions or cluttered backgrounds can be considerably improved. Extensive experiments based on challenging benchmark datasets are performed to demonstrate the superior performance of the proposed method over other state-of-the-art methods.