 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Demo Prompting: Leveraging Generated Outputs as Demonstrations for Enhanced Batch Prompting
Paper and Code
Oct 02, 2024
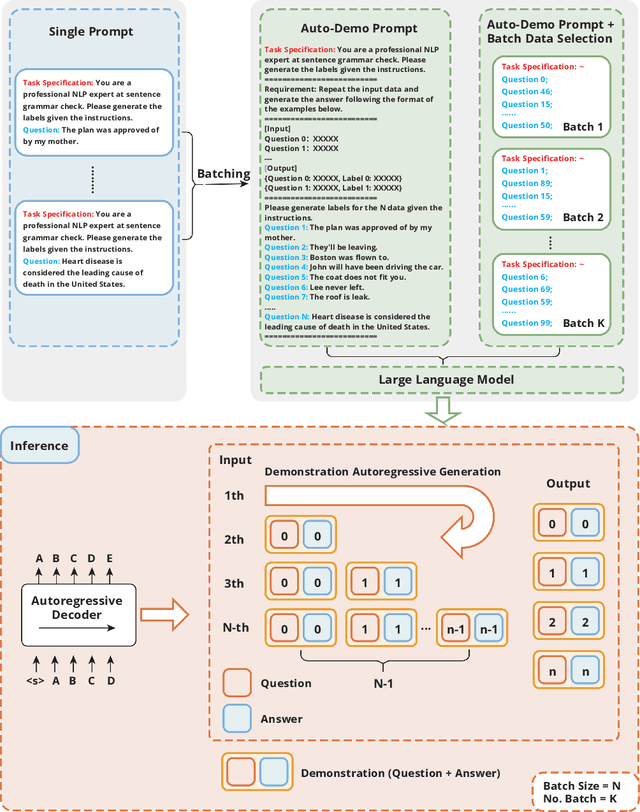
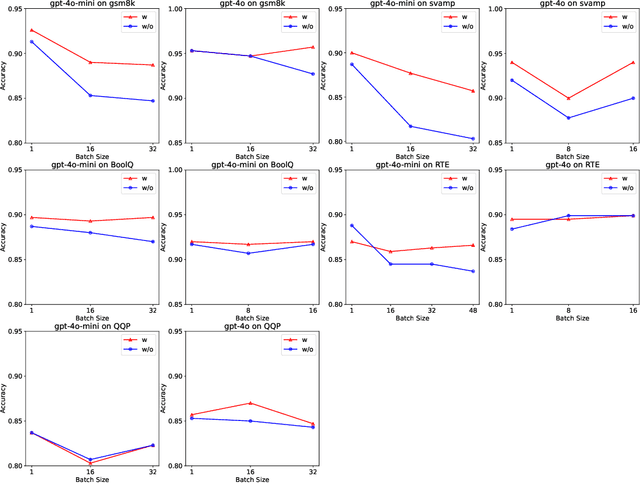
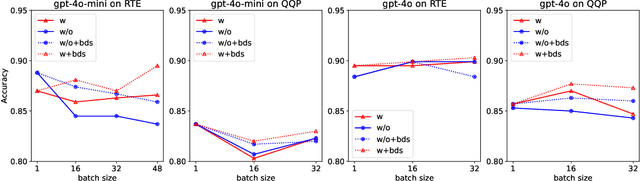
Batch prompting is a common technique in large language models (LLMs) used to process multiple inputs simultaneously, aiming to improve computational efficiency. However, as batch sizes increase, performance degradation often occurs due to the model's difficulty in handling lengthy context inputs. Existing methods that attempt to mitigate these issues rely solely on batch data arrangement and majority voting rather than improving the design of the batch prompt itself. In this paper, we address these limitations by proposing "Auto-Demo Prompting," a novel approach that leverages the question-output pairs from earlier questions within a batch as demonstrations for subsequent answer inference. We provide a formal theoretical analysis of how Auto-Demo Prompting functions within the autoregressive generation process of LLMs, illustrating how it utilizes prior outputs to optimize the model's internal representations. Our method effectively bridges the gap between batch prompting and few-shot prompting, enhancing performance with only a slight compromise in token usage. Experimental results across five NLP tasks demonstrate its effectiveness in mitigating performance degradation and occasionally outperforming single prompts. Furthermore, it opens new avenues for applying few-shot learning techniques, such as demonstration selection, within batch prompting, making it a robust solution for real-world applications.