 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Conversational Inertia in Multi-Turn Agents
Feb 03, 2026Large language models excel as few-shot learners when provided with appropriate demonstrations, yet this strength becomes problematic in multiturn agent scenarios, where LLMs erroneously mimic their own previous responses as few-shot examples. Through attention analysis, we identify conversational inertia, a phenomenon where models exhibit strong diagonal attention to previous responses, which is associated with imitation bias that constrains exploration. This reveals a tension when transforming few-shot LLMs into agents: longer context enriches environmental feedback for exploitation, yet also amplifies conversational inertia that undermines exploration. Our key insight is that for identical states, actions generated with longer contexts exhibit stronger inertia than those with shorter contexts, enabling construction of preference pairs without environment rewards. Based on this, we propose Context Preference Learning to calibrate model preferences to favor low-inertia responses over highinertia ones. We further provide context management strategies at inference time to balance exploration and exploitation. Experimental results across eight agentic environments and one deep research scenario validate that our framework reduces conversational inertia and achieves performance improvements.
The Anatomy of Conversational Scams: A Topic-Based Red Teaming Analysis of Multi-Turn Interactions in LLMs
Jan 06, 2026As LLMs gain persuasive agentic capabilities through extended dialogues, they introduce novel risks in multi-turn conversational scams that single-turn safety evaluations fail to capture. We systematically study these risks using a controlled LLM-to-LLM simulation framework across multi-turn scam scenarios. Evaluating eight state-of-the-art models in English and Chinese, we analyze dialogue outcomes and qualitatively annotate attacker strategies, defensive responses, and failure modes. Results reveal that scam interactions follow recurrent escalation patterns, while defenses employ verification and delay mechanisms. Furthermore, interactional failures frequently stem from safety guardrail activation and role instability. Our findings highlight multi-turn interactional safety as a critical, distinct dimension of LLM behavior.
Spatial-ORMLLM: Improve Spatial Relation Understanding in the Operating Room with Multimodal Large Language Model
Aug 11, 2025Precise spatial modeling in the operating room (OR) is foundational to many clinical tasks, supporting intraoperative awareness, hazard avoidance, and surgical decision-making. While existing approaches leverage large-scale multimodal datasets for latent-space alignment to implicitly learn spatial relationships, they overlook the 3D capabilities of MLLMs. However, this approach raises two issues: (1) Operating rooms typically lack multiple video and audio sensors, making multimodal 3D data difficult to obtain; (2) Training solely on readily available 2D data fails to capture fine-grained details in complex scenes. To address this gap, we introduce Spatial-ORMLLM, the first large vision-language model for 3D spatial reasoning in operating rooms using only RGB modality to infer volumetric and semantic cues, enabling downstream medical tasks with detailed and holistic spatial context. Spatial-ORMLLM incorporates a Spatial-Enhanced Feature Fusion Block, which integrates 2D modality inputs with rich 3D spatial knowledge extracted by the estimation algorithm and then feeds the combined features into the visual tower. By employing a unified end-to-end MLLM framework, it combines powerful spatial features with textual features to deliver robust 3D scene reasoning without any additional expert annotations or sensor inputs. Experiments on multiple benchmark clinical datasets demonstrate that Spatial-ORMLLM achieves state-of-the-art performance and generalizes robustly to previously unseen surgical scenarios and downstream tasks.
SDEval: Safety Dynamic Evaluation for Multimodal Large Language Models
Aug 08, 2025
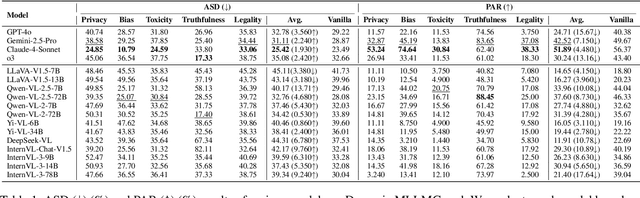
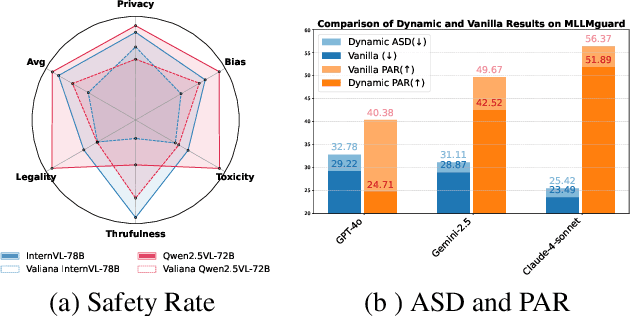
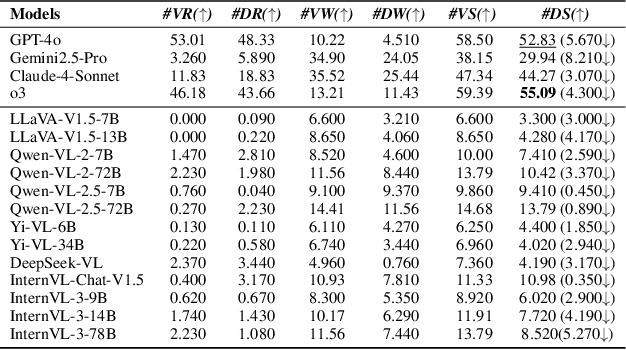
In the rapidly evolving landscape of Multimodal Large Language Models (MLLMs), the safety concerns of their outputs have earned significant attention. Although numerous datasets have been proposed, they may become outdated with MLLM advancements and are susceptible to data contamination issues. To address these problems, we propose \textbf{SDEval}, the \textit{first} safety dynamic evaluation framework to controllably adjust the distribution and complexity of safety benchmarks. Specifically, SDEval mainly adopts three dynamic strategies: text, image, and text-image dynamics to generate new samples from original benchmarks. We first explore the individual effects of text and image dynamics on model safety. Then, we find that injecting text dynamics into images can further impact safety, and conversely, injecting image dynamics into text also leads to safety risks. SDEval is general enough to be applied to various existing safety and even capability benchmarks. Experiments across safety benchmarks, MLLMGuard and VLSBench, and capability benchmarks, MMBench and MMVet, show that SDEval significantly influences safety evaluation, mitigates data contamination, and exposes safety limitations of MLLMs. Code is available at https://github.com/hq-King/SDEval
OpenHOI: Open-World Hand-Object Interaction Synthesis with Multimodal Large Language Model
May 25, 2025Understanding and synthesizing realistic 3D hand-object interactions (HOI) is critical for applications ranging from immersive AR/VR to dexterous robotics. Existing methods struggle with generalization, performing well on closed-set objects and predefined tasks but failing to handle unseen objects or open-vocabulary instructions. We introduce OpenHOI, the first framework for open-world HOI synthesis, capable of generating long-horizon manipulation sequences for novel objects guided by free-form language commands. Our approach integrates a 3D Multimodal Large Language Model (MLLM) fine-tuned for joint affordance grounding and semantic task decomposition, enabling precise localization of interaction regions (e.g., handles, buttons) and breakdown of complex instructions (e.g., "Find a water bottle and take a sip") into executable sub-tasks. To synthesize physically plausible interactions, we propose an affordance-driven diffusion model paired with a training-free physics refinement stage that minimizes penetration and optimizes affordance alignment. Evaluations across diverse scenarios demonstrate OpenHOI's superiority over state-of-the-art methods in generalizing to novel object categories, multi-stage tasks, and complex language instructions. Our project page at \href{https://openhoi.github.io}
Robust Variable Selection for High-dimensional Regression with Missing Data and Measurement Errors
Oct 23, 2024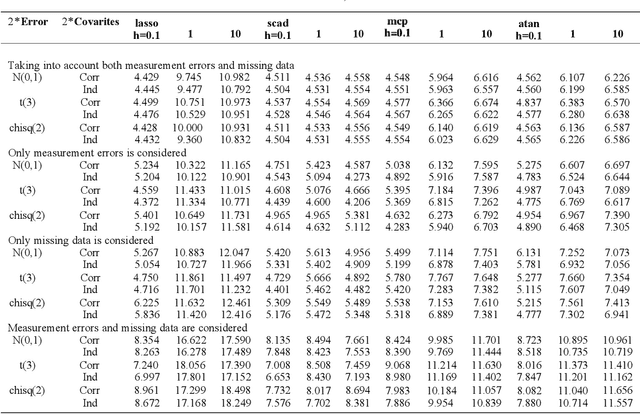


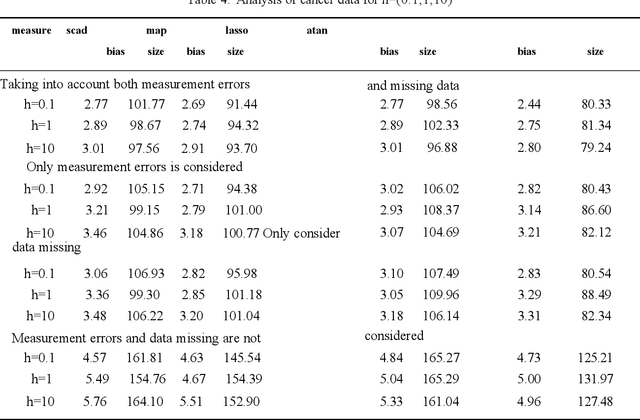
In our paper,we focus on robust variable selection for missing data and measurement error.Missing data and measurement errors can lead to confusing data distribution.We propose an exponential loss function with tuning parameter to apply to Missing and measurement errors data.By adjusting the parameter,the loss functioncan be better and more robust under various different data distributions.We use inverse probability weighting and additivityerrormodels to address missing data and measurement errors.Also,we find that the Atan punishment method works better.We used Monte Carlo simulations to assess the validity of robust variable selection and validated our findings with the breast cancer dataset
Diffusion-based Reinforcement Learning via Q-weighted Variational Policy Optimization
May 25, 2024



Diffusion models have garnered widespread attention in Reinforcement Learning (RL) for their powerful expressiveness and multimodality. It has been verified that utilizing diffusion policies can significantly improve the performance of RL algorithms in continuous control tasks by overcoming the limitations of unimodal policies, such as Gaussian policies, and providing the agent with enhanced exploration capabilities. However, existing works mainly focus on the application of diffusion policies in offline RL, while their incorporation into online RL is less investigated. The training objective of the diffusion model, known as the variational lower bound, cannot be optimized directly in online RL due to the unavailability of 'good' actions. This leads to difficulties in conducting diffusion policy improvement. To overcome this, we propose a novel model-free diffusion-based online RL algorithm, Q-weighted Variational Policy Optimization (QVPO). Specifically, we introduce the Q-weighted variational loss, which can be proved to be a tight lower bound of the policy objective in online RL under certain conditions. To fulfill these conditions, the Q-weight transformation functions are introduced for general scenarios. Additionally, to further enhance the exploration capability of the diffusion policy, we design a special entropy regularization term. We also develop an efficient behavior policy to enhance sample efficiency by reducing the variance of the diffusion policy during online interactions. Consequently, the QVPO algorithm leverages the exploration capabilities and multimodality of diffusion policies, preventing the RL agent from converging to a sub-optimal policy. To verify the effectiveness of QVPO, we conduct comprehensive experiments on MuJoCo benchmarks. The final results demonstrate that QVPO achieves state-of-the-art performance on both cumulative reward and sample efficiency.
Hypergraph Convolutional Networks for Fine-grained ICU Patient Similarity Analysis and Risk Prediction
Aug 24, 2023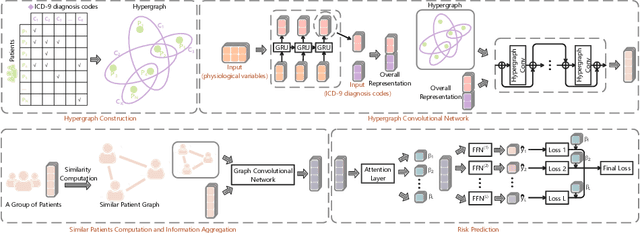
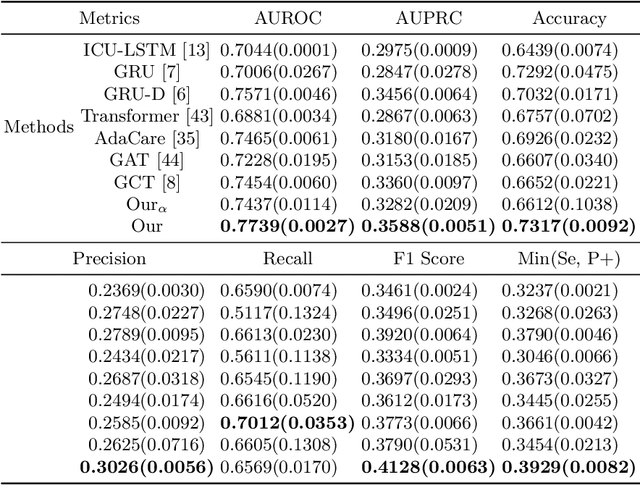
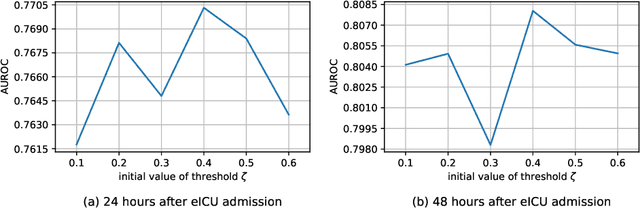
The Intensive Care Unit (ICU) is one of the most important parts of a hospital, which admits critically ill patients and provides continuous monitoring and treatment. Various patient outcome prediction methods have been attempted to assist healthcare professionals in clinical decision-making. Existing methods focus on measuring the similarity between patients using deep neural networks to capture the hidden feature structures. However, the higher-order relationships are ignored, such as patient characteristics (e.g., diagnosis codes) and their causal effects on downstream clinical predictions. In this paper, we propose a novel Hypergraph Convolutional Network that allows the representation of non-pairwise relationships among diagnosis codes in a hypergraph to capture the hidden feature structures so that fine-grained patient similarity can be calculated for personalized mortality risk prediction. Evaluation using a publicly available eICU Collaborative Research Database indicates that our method achieves superior performance over the state-of-the-art models on mortality risk prediction. Moreover, the results of several case studies demonstrated the effectiveness of constructing graph networks in providing good transparency and robustness in decision-making.
Contrastive Learning-based Imputation-Prediction Networks for In-hospital Mortality Risk Modeling using EHRs
Aug 19, 2023Predicting the risk of in-hospital mortality from electronic health records (EHRs) has received considerable attention. Such predictions will provide early warning of a patient's health condition to healthcare professionals so that timely interventions can be taken. This prediction task is challenging since EHR data are intrinsically irregular, with not only many missing values but also varying time intervals between medical records. Existing approaches focus on exploiting the variable correlations in patient medical records to impute missing values and establishing time-decay mechanisms to deal with such irregularity. This paper presents a novel contrastive learning-based imputation-prediction network for predicting in-hospital mortality risks using EHR data. Our approach introduces graph analysis-based patient stratification modeling in the imputation process to group similar patients. This allows information of similar patients only to be used, in addition to personal contextual information, for missing value imputation. Moreover, our approach can integrate contrastive learning into the proposed network architecture to enhance patient representation learning and predictive performance on the classification task. Experiments on two real-world EHR datasets show that our approach outperforms the state-of-the-art approaches in both imputation and prediction tasks.
Integrated Convolutional and Recurrent Neural Networks for Health Risk Prediction using Patient Journey Data with Many Missing Values
Nov 14, 2022Predicting the health risks of patients using Electronic Health Records (EHR) has attracted considerable attention in recent years, especially with the development of deep learning techniques. Health risk refers to the probability of the occurrence of a specific health outcome for a specific patient. The predicted risks can be used to support decision-making by healthcare professionals. EHRs are structured patient journey data. Each patient journey contains a chronological set of clinical events, and within each clinical event, there is a set of clinical/medical activities. Due to variations of patient conditions and treatment needs, EHR patient journey data has an inherently high degree of missingness that contains important information affecting relationships among variables, including time. Existing deep learning-based models generate imputed values for missing values when learning the relationships. However, imputed data in EHR patient journey data may distort the clinical meaning of the original EHR patient journey data, resulting in classification bias. This paper proposes a novel end-to-end approach to modeling EHR patient journey data with Integrated Convolutional and Recurrent Neural Networks. Our model can capture both long- and short-term temporal patterns within each patient journey and effectively handle the high degree of missingness in EHR data without any imputation data generation. Extensive experimental results using the proposed model on two real-world datasets demonstrate robust performance as well as superior prediction accuracy compared to existing state-of-the-art imputation-based prediction methods.