 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Distillation in the Parameter and Spectrum Domains for Video Action Recognition
Paper and Code
Sep 15, 2020
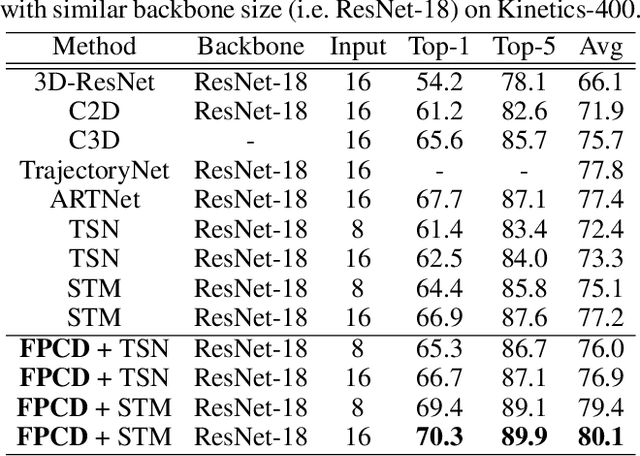
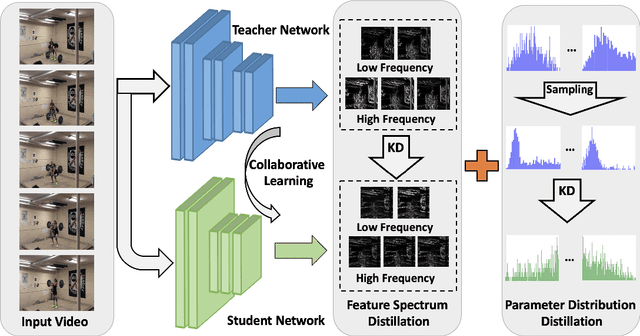

Recent years have witnessed the significant progress of action recognition task with deep networks. However, most of current video networks require large memory and computational resources, which hinders their applications in practice. Existing knowledge distillation methods are limited to the image-level spatial domain, ignoring the temporal and frequency information which provide structural knowledge and are important for video analysis. This paper explores how to train small and efficient networks for action recognition. Specifically, we propose two distillation strategies in the frequency domain, namely the feature spectrum and parameter distribution distillations respectively. Our insight is that appealing performance of action recognition requires \textit{explicitly} modeling the temporal frequency spectrum of video features. Therefore, we introduce a spectrum loss that enforces the student network to mimic the temporal frequency spectrum from the teacher network, instead of \textit{implicitly} distilling features as many previous works. Second, the parameter frequency distribution is further adopted to guide the student network to learn the appearance modeling process from the teacher. Besides, a collaborative learning strategy is presented to optimize the training process from a probabilistic view. Extensive experiments are conducted on several action recognition benchmarks, such as Kinetics, Something-Something, and Jester, which consistently verify effectiveness of our approach, and demonstrate that our method can achieve higher performance than state-of-the-art methods with the same backbone.