 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoG3D: Ultra-High-Resolution 3D Shape Modeling via Local-to-Global Partitioning
Nov 18, 2025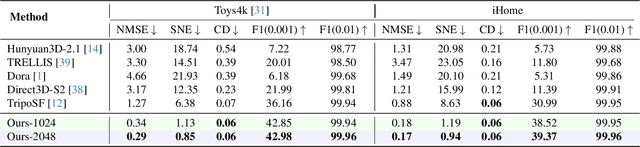
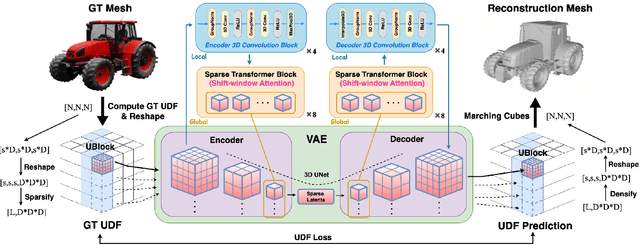
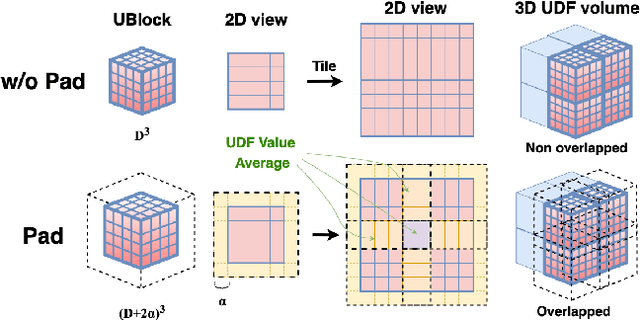
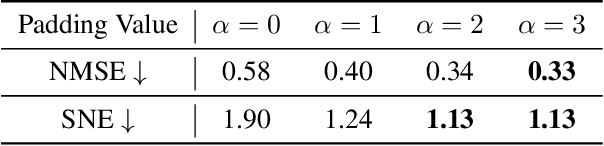
Generating high-fidelity 3D contents remains a fundamental challenge due to the complexity of representing arbitrary topologies-such as open surfaces and intricate internal structures-while preserving geometric details. Prevailing methods based on signed distance fields (SDFs) are hampered by costly watertight preprocessing and struggle with non-manifold geometries, while point-cloud representations often suffer from sampling artifacts and surface discontinuities. To overcome these limitations, we propose a novel 3D variational autoencoder (VAE) framework built upon unsigned distance fields (UDFs)-a more robust and computationally efficient representation that naturally handles complex and incomplete shapes. Our core innovation is a local-to-global (LoG) architecture that processes the UDF by partitioning it into uniform subvolumes, termed UBlocks. This architecture couples 3D convolutions for capturing local detail with sparse transformers for enforcing global coherence. A Pad-Average strategy further ensures smooth transitions at subvolume boundaries during reconstruction. This modular design enables seamless scaling to ultra-high resolutions up to $2048^3$-a regime previously unattainable for 3D VAEs. Experiments demonstrate state-of-the-art performance in both reconstruction accuracy and generative quality, yielding superior surface smoothness and geometric flexibility.
M$^{3}$D: A Multimodal, Multilingual and Multitask Dataset for Grounded Document-level Information Extraction
Dec 05, 2024



Multimodal information extraction (IE) tasks have attracted increasing attention because many studies have shown that multimodal information benefits text information extraction. However, existing multimodal IE datasets mainly focus on sentence-level image-facilitated IE in English text, and pay little attention to video-based multimodal IE and fine-grained visual grounding. Therefore, in order to promote the development of multimodal IE, we constructed a multimodal multilingual multitask dataset, named M$^{3}$D, which has the following features: (1) It contains paired document-level text and video to enrich multimodal information; (2) It supports two widely-used languages, namely English and Chinese; (3) It includes more multimodal IE tasks such as entity recognition, entity chain extraction, relation extraction and visual grounding. In addition, our dataset introduces an unexplored theme, i.e., biography, enriching the domains of multimodal IE resources. To establish a benchmark for our dataset, we propose an innovative hierarchical multimodal IE model. This model effectively leverages and integrates multimodal information through a Denoised Feature Fusion Module (DFFM). Furthermore, in non-ideal scenarios, modal information is often incomplete. Thus, we designed a Missing Modality Construction Module (MMCM) to alleviate the issues caused by missing modalities. Our model achieved an average performance of 53.80% and 53.77% on four tasks in English and Chinese datasets, respectively, which set a reasonable standard for subsequent research. In addition, we conducted more analytical experiments to verify the effectiveness of our proposed module. We believe that our work can promote the development of the field of multimodal IE.
Deep Point Cloud Simplification for High-quality Surface Reconstruction
Mar 17, 2022
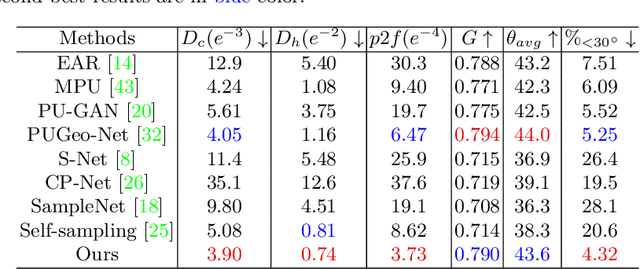


The growing size of point clouds enlarges consumptions of storage, transmission, and computation of 3D scenes. Raw data is redundant, noisy, and non-uniform. Therefore, simplifying point clouds for achieving compact, clean, and uniform points is becoming increasingly important for 3D vision and graphics tasks. Previous learning based methods aim to generate fewer points for scene understanding, regardless of the quality of surface reconstruction, leading to results with low reconstruction accuracy and bad point distribution. In this paper, we propose a novel point cloud simplification network (PCS-Net) dedicated to high-quality surface mesh reconstruction while maintaining geometric fidelity. We first learn a sampling matrix in a feature-aware simplification module to reduce the number of points. Then we propose a novel double-scale resampling module to refine the positions of the sampled points, to achieve a uniform distribution. To further retain important shape features, an adaptive sampling strategy with a novel saliency loss is designed. With our PCS-Net, the input non-uniform and noisy point cloud can be simplified in a feature-aware manner, i.e., points near salient features are consolidated but still with uniform distribution locally. Experiments demonstrate the effectiveness of our method and show that we outperform previous simplification or reconstruction-oriented upsampling methods.