 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaminoDiff: Artifact-Free Computed Laminography in Non-Destructive Testing via Diffusion Model
Jan 12, 2026Computed Laminography (CL) is a key non-destructive testing technology for the visualization of internal structures in large planar objects. The inherent scanning geometry of CL inevitably results in inter-layer aliasing artifacts, limiting its practical application, particularly in electronic component inspection. While deep learning (DL) provides a powerful paradigm for artifact removal, its effectiveness is often limited by the domain gap between synthetic data and real-world data. In this work, we present LaminoDiff, a framework to integrate a diffusion model with a high-fidelity prior representation to bridge the domain gap in CL imaging. This prior, generated via a dual-modal CT-CL fusion strategy, is integrated into the proposed network as a conditional constraint. This integration ensures high-precision preservation of circuit structures and geometric fidelity while suppressing artifacts. Extensive experiments on both simulated and real PCB datasets demonstrate that LaminoDiff achieves high-fidelity reconstruction with competitive performance in artifact suppression and detail recovery. More importantly, the results facilitate reliable automated defect recognition.
Meta-information Guided Cross-domain Synergistic Diffusion Model for Low-dose PET Reconstruction
Dec 23, 2025Low-dose PET imaging is crucial for reducing patient radiation exposure but faces challenges like noise interference, reduced contrast, and difficulty in preserving physiological details. Existing methods often neglect both projection-domain physics knowledge and patient-specific meta-information, which are critical for functional-semantic correlation mining. In this study, we introduce a meta-information guided cross-domain synergistic diffusion model (MiG-DM) that integrates comprehensive cross-modal priors to generate high-quality PET images. Specifically, a meta-information encoding module transforms clinical parameters into semantic prompts by considering patient characteristics, dose-related information, and semi-quantitative parameters, enabling cross-modal alignment between textual meta-information and image reconstruction. Additionally, the cross-domain architecture combines projection-domain and image-domain processing. In the projection domain, a specialized sinogram adapter captures global physical structures through convolution operations equivalent to global image-domain filtering. Experiments on the UDPET public dataset and clinical datasets with varying dose levels demonstrate that MiG-DM outperforms state-of-the-art methods in enhancing PET image quality and preserving physiological details.
Partitioned Hankel-based Diffusion Models for Few-shot Low-dose CT Reconstruction
May 27, 2024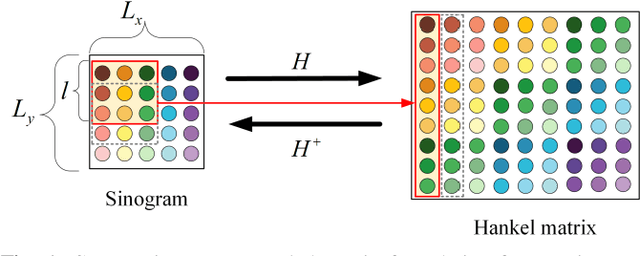

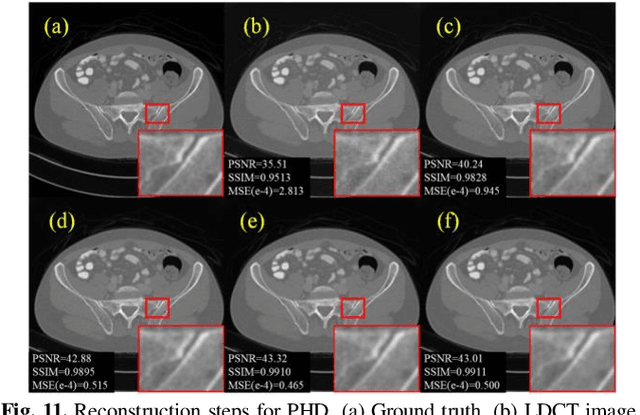
Low-dose computed tomography (LDCT) plays a vital role in clinical applications by mitigating radiation risks. Nevertheless, reducing radiation doses significantly degrades image quality. Concurrently, common deep learning methods demand extensive data, posing concerns about privacy, cost, and time constraints. Consequently, we propose a few-shot low-dose CT reconstruction method using Partitioned Hankel-based Diffusion (PHD) models. During the prior learning stage, the projection data is first transformed into multiple partitioned Hankel matrices. Structured tensors are then extracted from these matrices to facilitate prior learning through multiple diffusion models. In the iterative reconstruction stage, an iterative stochastic differential equation solver is employed along with data consistency constraints to update the acquired projection data. Furthermore, penalized weighted least-squares and total variation techniques are introduced to enhance the resulting image quality. The results approximate those of normal-dose counterparts, validating PHD model as an effective and practical model for reducing artifacts and noise while preserving image quality.
Partition-based K-space Synthesis for Multi-contrast Parallel Imaging
Dec 01, 2023Multi-contrast magnetic resonance imaging is a significant and essential medical imaging technique.However, multi-contrast imaging has longer acquisition time and is easy to cause motion artifacts. In particular, the acquisition time for a T2-weighted image is prolonged due to its longer repetition time (TR). On the contrary, T1-weighted image has a shorter TR. Therefore,utilizing complementary information across T1 and T2-weighted image is a way to decrease the overall imaging time. Previous T1-assisted T2 reconstruction methods have mostly focused on image domain using whole-based image fusion approaches. The image domain reconstruction method has the defects of high computational complexity and limited flexibility. To address this issue, we propose a novel multi-contrast imaging method called partition-based k-space synthesis (PKS) which can achieve super reconstruction quality of T2-weighted image by feature fusion. Concretely, we first decompose fully-sampled T1 k-space data and under-sampled T2 k-space data into two sub-data, separately. Then two new objects are constructed by combining the two sub-T1/T2 data. After that, the two new objects as the whole data to realize the reconstruction of T2-weighted image. Finally, the objective T2 is synthesized by extracting the sub-T2 data of each part. Experimental results showed that our combined technique can achieve comparable or better results than using traditional k-space parallel imaging(SAKE) that processes each contrast independently.
Low-rank Tensor Assisted K-space Generative Model for Parallel Imaging Reconstruction
Dec 11, 2022Although recent deep learning methods, especially generative models, have shown good performance in fast magnetic resonance imaging, there is still much room for improvement in high-dimensional generation. Considering that internal dimensions in score-based generative models have a critical impact on estimating the gradient of the data distribution, we present a new idea, low-rank tensor assisted k-space generative model (LR-KGM), for parallel imaging reconstruction. This means that we transform original prior information into high-dimensional prior information for learning. More specifically, the multi-channel data is constructed into a large Hankel matrix and the matrix is subsequently folded into tensor for prior learning. In the testing phase, the low-rank rotation strategy is utilized to impose low-rank constraints on tensor output of the generative network. Furthermore, we alternately use traditional generative iterations and low-rank high-dimensional tensor iterations for reconstruction. Experimental comparisons with the state-of-the-arts demonstrated that the proposed LR-KGM method achieved better performance.
Multi-Weight Respecification of Scan-specific Learning for Parallel Imaging
Apr 05, 2022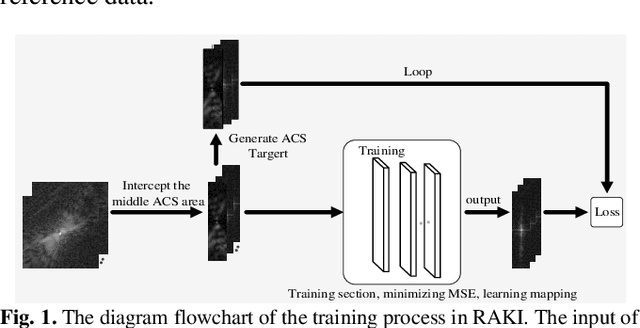
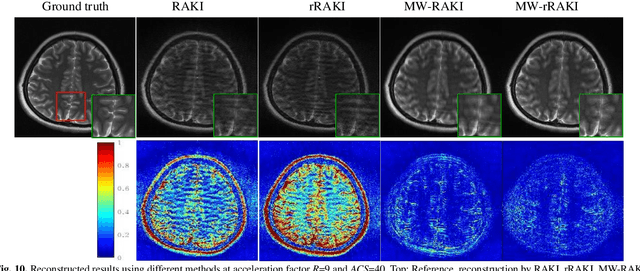
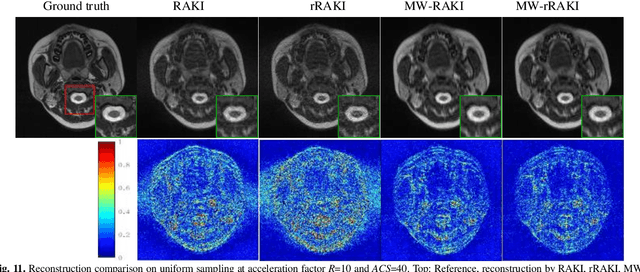
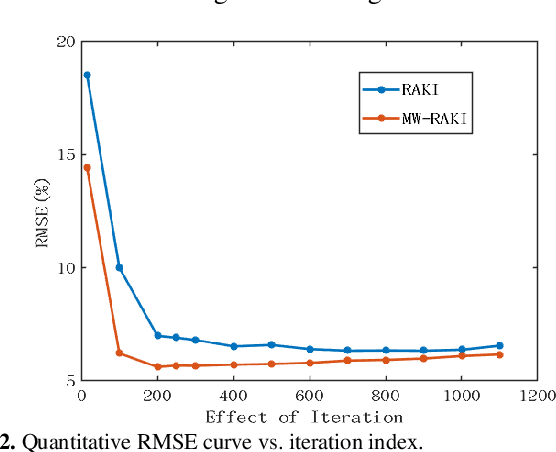
Parallel imaging is widely used in magnetic resonance imaging as an acceleration technology. Traditional linear reconstruction methods in parallel imaging often suffer from noise amplification. Recently, a non-linear robust artificial-neural-network for k-space interpolation (RAKI) exhibits superior noise resilience over other linear methods. However, RAKI performs poorly at high acceleration rates, and needs a large amount of autocalibration signals as the training samples. In order to tackle these issues, we propose a multi-weight method that implements multiple weighting matrices on the undersampled data, named as MW-RAKI. Enforcing multiple weighted matrices on the measurements can effectively reduce the influence of noise and increase the data constraints. Furthermore, we incorporate the strategy of multiple weighting matrixes into a residual version of RAKI, and form MW-rRAKI.Experimental compari-sons with the alternative methods demonstrated noticeably better reconstruction performances, particularly at high acceleration rates.