 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFore-Mamba3D: Mamba-based Foreground-Enhanced Encoding for 3D Object Detection
Feb 23, 2026Linear modeling methods like Mamba have been merged as the effective backbone for the 3D object detection task. However, previous Mamba-based methods utilize the bidirectional encoding for the whole non-empty voxel sequence, which contains abundant useless background information in the scenes. Though directly encoding foreground voxels appears to be a plausible solution, it tends to degrade detection performance. We attribute this to the response attenuation and restricted context representation in the linear modeling for fore-only sequences. To address this problem, we propose a novel backbone, termed Fore-Mamba3D, to focus on the foreground enhancement by modifying Mamba-based encoder. The foreground voxels are first sampled according to the predicted scores. Considering the response attenuation existing in the interaction of foreground voxels across different instances, we design a regional-to-global slide window (RGSW) to propagate the information from regional split to the entire sequence. Furthermore, a semantic-assisted and state spatial fusion module (SASFMamba) is proposed to enrich contextual representation by enhancing semantic and geometric awareness within the Mamba model. Our method emphasizes foreground-only encoding and alleviates the distance-based and causal dependencies in the linear autoregression model. The superior performance across various benchmarks demonstrates the effectiveness of Fore-Mamba3D in the 3D object detection task.
Point Cloud Quantization through Multimodal Prompting for 3D Understanding
Nov 19, 2025Vector quantization has emerged as a powerful tool in large-scale multimodal models, unifying heterogeneous representations through discrete token encoding. However, its effectiveness hinges on robust codebook design. Current prototype-based approaches relying on trainable vectors or clustered centroids fall short in representativeness and interpretability, even as multimodal alignment demonstrates its promise in vision-language models. To address these limitations, we propose a simple multimodal prompting-driven quantization framework for point cloud analysis. Our methodology is built upon two core insights: 1) Text embeddings from pre-trained models inherently encode visual semantics through many-to-one contrastive alignment, naturally serving as robust prototype priors; and 2) Multimodal prompts enable adaptive refinement of these prototypes, effectively mitigating vision-language semantic gaps. The framework introduces a dual-constrained quantization space, enforced by compactness and separation regularization, which seamlessly integrates visual and prototype features, resulting in hybrid representations that jointly encode geometric and semantic information. Furthermore, we employ Gumbel-Softmax relaxation to achieve differentiable discretization while maintaining quantization sparsity. Extensive experiments on the ModelNet40 and ScanObjectNN datasets clearly demonstrate the superior effectiveness of the proposed method.
RAC-DMVC: Reliability-Aware Contrastive Deep Multi-View Clustering under Multi-Source Noise
Nov 17, 2025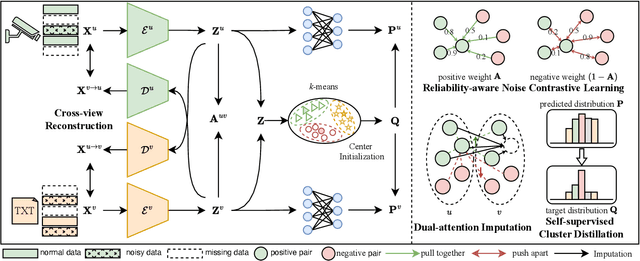
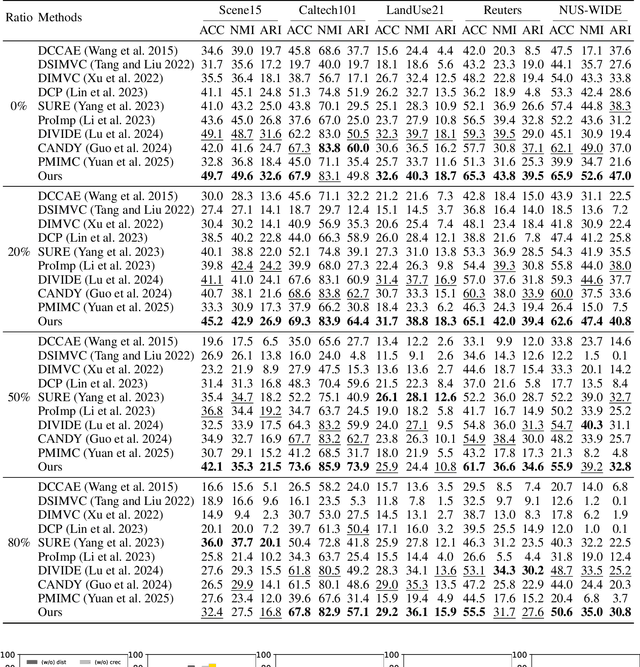

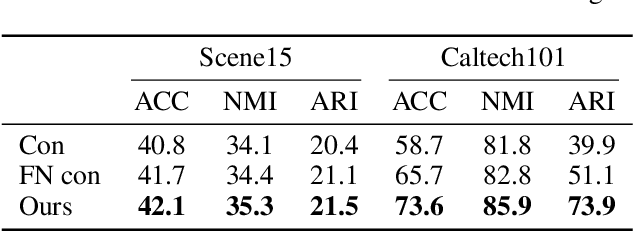
Multi-view clustering (MVC), which aims to separate the multi-view data into distinct clusters in an unsupervised manner, is a fundamental yet challenging task. To enhance its applicability in real-world scenarios, this paper addresses a more challenging task: MVC under multi-source noises, including missing noise and observation noise. To this end, we propose a novel framework, Reliability-Aware Contrastive Deep Multi-View Clustering (RAC-DMVC), which constructs a reliability graph to guide robust representation learning under noisy environments. Specifically, to address observation noise, we introduce a cross-view reconstruction to enhances robustness at the data level, and a reliability-aware noise contrastive learning to mitigates bias in positive and negative pairs selection caused by noisy representations. To handle missing noise, we design a dual-attention imputation to capture shared information across views while preserving view-specific features. In addition, a self-supervised cluster distillation module further refines the learned representations and improves the clustering performance. Extensive experiments on five benchmark datasets demonstrate that RAC-DMVC outperforms SOTA methods on multiple evaluation metrics and maintains excellent performance under varying ratios of noise.
Center-Oriented Prototype Contrastive Clustering
Aug 21, 2025Contrastive learning is widely used in clustering tasks due to its discriminative representation. However, the conflict problem between classes is difficult to solve effectively. Existing methods try to solve this problem through prototype contrast, but there is a deviation between the calculation of hard prototypes and the true cluster center. To address this problem, we propose a center-oriented prototype contrastive clustering framework, which consists of a soft prototype contrastive module and a dual consistency learning module. In short, the soft prototype contrastive module uses the probability that the sample belongs to the cluster center as a weight to calculate the prototype of each category, while avoiding inter-class conflicts and reducing prototype drift. The dual consistency learning module aligns different transformations of the same sample and the neighborhoods of different samples respectively, ensuring that the features have transformation-invariant semantic information and compact intra-cluster distribution, while providing reliable guarantees for the calculation of prototypes. Extensive experiments on five datasets show that the proposed method is effective compared to the SOTA. Our code is published on https://github.com/LouisDong95/CPCC.
RemDet: Rethinking Efficient Model Design for UAV Object Detection
Dec 13, 2024



Object detection in Unmanned Aerial Vehicle (UAV) images has emerged as a focal area of research, which presents two significant challenges: i) objects are typically small and dense within vast images; ii) computational resource constraints render most models unsuitable for real-time deployment. Current real-time object detectors are not optimized for UAV images, and complex methods designed for small object detection often lack real-time capabilities. To address these challenges, we propose a novel detector, RemDet (Reparameter efficient multiplication Detector). Our contributions are as follows: 1) Rethinking the challenges of existing detectors for small and dense UAV images, and proposing information loss as a design guideline for efficient models. 2) We introduce the ChannelC2f module to enhance small object detection performance, demonstrating that high-dimensional representations can effectively mitigate information loss. 3) We design the GatedFFN module to provide not only strong performance but also low latency, effectively addressing the challenges of real-time detection. Our research reveals that GatedFFN, through the use of multiplication, is more cost-effective than feed-forward networks for high-dimensional representation. 4) We propose the CED module, which combines the advantages of ViT and CNN downsampling to effectively reduce information loss. It specifically enhances context information for small and dense objects. Extensive experiments on large UAV datasets, Visdrone and UAVDT, validate the real-time efficiency and superior performance of our methods. On the challenging UAV dataset VisDrone, our methods not only provided state-of-the-art results, improving detection by more than 3.4%, but also achieve 110 FPS on a single 4090.Codes are available at (this URL)(https://github.com/HZAI-ZJNU/RemDet).
SCSA: Exploring the Synergistic Effects Between Spatial and Channel Attention
Jul 06, 2024Channel and spatial attentions have respectively brought significant improvements in extracting feature dependencies and spatial structure relations for various downstream vision tasks. While their combination is more beneficial for leveraging their individual strengths, the synergy between channel and spatial attentions has not been fully explored, lacking in fully harness the synergistic potential of multi-semantic information for feature guidance and mitigation of semantic disparities. Our study attempts to reveal the synergistic relationship between spatial and channel attention at multiple semantic levels, proposing a novel Spatial and Channel Synergistic Attention module (SCSA). Our SCSA consists of two parts: the Shareable Multi-Semantic Spatial Attention (SMSA) and the Progressive Channel-wise Self-Attention (PCSA). SMSA integrates multi-semantic information and utilizes a progressive compression strategy to inject discriminative spatial priors into PCSA's channel self-attention, effectively guiding channel recalibration. Additionally, the robust feature interactions based on the self-attention mechanism in PCSA further mitigate the disparities in multi-semantic information among different sub-features within SMSA. We conduct extensive experiments on seven benchmark datasets, including classification on ImageNet-1K, object detection on MSCOCO 2017, segmentation on ADE20K, and four other complex scene detection datasets. Our results demonstrate that our proposed SCSA not only surpasses the current state-of-the-art attention but also exhibits enhanced generalization capabilities across various task scenarios. The code and models are available at: https://github.com/HZAI-ZJNU/SCSA.
Mamba YOLO: SSMs-Based YOLO For Object Detection
Jun 09, 2024



Propelled by the rapid advancement of deep learning technologies, the YOLO series has set a new benchmark for real-time object detectors. Researchers have continuously explored innovative applications of reparameterization, efficient layer aggregation networks, and anchor-free techniques on the foundation of YOLO. To further enhance detection performance, Transformer-based structures have been introduced, significantly expanding the model's receptive field and achieving notable performance gains. However, such improvements come at a cost, as the quadratic complexity of the self-attention mechanism increases the computational burden of the model. Fortunately, the emergence of State Space Models (SSM) as an innovative technology has effectively mitigated the issues caused by quadratic complexity. In light of these advancements, we introduce Mamba-YOLO a novel object detection model based on SSM. Mamba-YOLO not only optimizes the SSM foundation but also adapts specifically for object detection tasks. Given the potential limitations of SSM in sequence modeling, such as insufficient receptive field and weak image locality, we have designed the LSBlock and RGBlock. These modules enable more precise capture of local image dependencies and significantly enhance the robustness of the model. Extensive experimental results on the publicly available benchmark datasets COCO and VOC demonstrate that Mamba-YOLO surpasses the existing YOLO series models in both performance and competitiveness, showcasing its substantial potential and competitive edge.The PyTorch code is available at:\url{https://github.com/HZAI-ZJNU/Mamba-YOLO}