 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni IIE Bench: Benchmarking the Practical Capabilities of Image Editing Models
Mar 16, 2026While Instruction-based Image Editing (IIE) has achieved significant progress, existing benchmarks pursue task breadth via mixed evaluations. This paradigm obscures a critical failure mode crucial in professional applications: the inconsistent performance of models across tasks of varying semantic scales. To address this gap, we introduce Omni IIE Bench, a high-quality, human-annotated benchmark specifically designed to diagnose the editing consistency of IIE models in practical application scenarios. Omni IIE Bench features an innovative dual-track diagnostic design: (1) Single-turn Consistency, comprising shared-context task pairs of attribute modification and entity replacement; and (2) Multi-turn Coordination, involving continuous dialogue tasks that traverse semantic scales. The benchmark is constructed via an exceptionally rigorous multi-stage human filtering process, incorporating a quality standard enforced by computer vision graduate students and an industry relevance review conducted by professional designers. We perform a comprehensive evaluation of 8 mainstream IIE models using Omni IIE Bench. Our analysis quantifies, for the first time, a prevalent performance gap: nearly all models exhibit a significant performance degradation when transitioning from low-semantic-scale to high-semantic-scale tasks. Omni IIE Bench provides critical diagnostic tools and insights for the development of next-generation, more reliable, and stable IIE models.
Beyond Closed-Pool Video Retrieval: A Benchmark and Agent Framework for Real-World Video Search and Moment Localization
Feb 10, 2026Traditional video retrieval benchmarks focus on matching precise descriptions to closed video pools, failing to reflect real-world searches characterized by fuzzy, multi-dimensional memories on the open web. We present \textbf{RVMS-Bench}, a comprehensive system for evaluating real-world video memory search. It consists of \textbf{1,440 samples} spanning \textbf{20 diverse categories} and \textbf{four duration groups}, sourced from \textbf{real-world open-web videos}. RVMS-Bench utilizes a hierarchical description framework encompassing \textbf{Global Impression, Key Moment, Temporal Context, and Auditory Memory} to mimic realistic multi-dimensional search cues, with all samples strictly verified via a human-in-the-loop protocol. We further propose \textbf{RACLO}, an agentic framework that employs abductive reasoning to simulate the human ``Recall-Search-Verify'' cognitive process, effectively addressing the challenge of searching for videos via fuzzy memories in the real world. Experiments reveal that existing MLLMs still demonstrate insufficient capabilities in real-world Video Retrieval and Moment Localization based on fuzzy memories. We believe this work will facilitate the advancement of video retrieval robustness in real-world unstructured scenarios.
PaperX: A Unified Framework for Multimodal Academic Presentation Generation with Scholar DAG
Feb 05, 2026Transforming scientific papers into multimodal presentation content is essential for research dissemination but remains labor intensive. Existing automated solutions typically treat each format as an isolated downstream task, leading to redundant processing and semantic inconsistency. We introduce PaperX, a unified framework that models academic presentation generation as a structural transformation and rendering process. Central to our approach is the Scholar DAG, an intermediate representation that decouples the paper's logical structure from its final presentation syntax. By applying adaptive graph traversal strategies, PaperX generates diverse, high quality outputs from a single source. Comprehensive evaluations demonstrate that our framework achieves the state of the art performance in content fidelity and aesthetic quality while significantly improving cost efficiency compared to specialized single task agents.
ShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
VDE Bench: Evaluating The Capability of Image Editing Models to Modify Visual Documents
Jan 27, 2026In recent years, multimodal image editing models have achieved substantial progress, enabling users to manipulate visual content through natural language in a flexible and interactive manner. Nevertheless, an important yet insufficiently explored research direction remains visual document image editing, which involves modifying textual content within images while faithfully preserving the original text style and background context. Existing approaches, including AnyText, GlyphControl, and TextCtrl, predominantly focus on English-language scenarios and documents with relatively sparse textual layouts, thereby failing to adequately address dense, structurally complex documents or non-Latin scripts such as Chinese. To bridge this gap, we propose \textbf{V}isual \textbf{D}oc \textbf{E}dit Bench(VDE Bench), a rigorously human-annotated and evaluated benchmark specifically designed to assess image editing models on multilingual and complex visual document editing tasks. The benchmark comprises a high-quality dataset encompassing densely textual documents in both English and Chinese, including academic papers, posters, presentation slides, examination materials, and newspapers. Furthermore, we introduce a decoupled evaluation framework that systematically quantifies editing performance at the OCR parsing level, enabling fine-grained assessment of text modification accuracy. Based on this benchmark, we conduct a comprehensive evaluation of representative state-of-the-art image editing models. Manual verification demonstrates a strong consistency between human judgments and automated evaluation metrics. VDE Bench constitutes the first systematic benchmark for evaluating image editing models on multilingual and densely textual visual documents.
RPO:Reinforcement Fine-Tuning with Partial Reasoning Optimization
Jan 27, 2026Within the domain of large language models, reinforcement fine-tuning algorithms necessitate the generation of a complete reasoning trajectory beginning from the input query, which incurs significant computational overhead during the rollout phase of training. To address this issue, we analyze the impact of different segments of the reasoning path on the correctness of the final result and, based on these insights, propose Reinforcement Fine-Tuning with Partial Reasoning Optimization (RPO), a plug-and-play reinforcement fine-tuning algorithm. Unlike traditional reinforcement fine-tuning algorithms that generate full reasoning paths, RPO trains the model by generating suffixes of the reasoning path using experience cache. During the rollout phase of training, RPO reduces token generation in this phase by approximately 95%, greatly lowering the theoretical time overhead. Compared with full-path reinforcement fine-tuning algorithms, RPO reduces the training time of the 1.5B model by 90% and the 7B model by 72%. At the same time, it can be integrated with typical algorithms such as GRPO and DAPO, enabling them to achieve training acceleration while maintaining performance comparable to the original algorithms. Our code is open-sourced at https://github.com/yhz5613813/RPO.
Beyond BEV: Optimizing Point-Level Tokens for Collaborative Perception
Aug 27, 2025Collaborative perception allows agents to enhance their perceptual capabilities by exchanging intermediate features. Existing methods typically organize these intermediate features as 2D bird's-eye-view (BEV) representations, which discard critical fine-grained 3D structural cues essential for accurate object recognition and localization. To this end, we first introduce point-level tokens as intermediate representations for collaborative perception. However, point-cloud data are inherently unordered, massive, and position-sensitive, making it challenging to produce compact and aligned point-level token sequences that preserve detailed structural information. Therefore, we present CoPLOT, a novel Collaborative perception framework that utilizes Point-Level Optimized Tokens. It incorporates a point-native processing pipeline, including token reordering, sequence modeling, and multi-agent spatial alignment. A semantic-aware token reordering module generates adaptive 1D reorderings by leveraging scene-level and token-level semantic information. A frequency-enhanced state space model captures long-range sequence dependencies across both spatial and spectral domains, improving the differentiation between foreground tokens and background clutter. Lastly, a neighbor-to-ego alignment module applies a closed-loop process, combining global agent-level correction with local token-level refinement to mitigate localization noise. Extensive experiments on both simulated and real-world datasets show that CoPLOT outperforms state-of-the-art models, with even lower communication and computation overhead. Code will be available at https://github.com/CheeryLeeyy/CoPLOT.
CollaMamba: Efficient Collaborative Perception with Cross-Agent Spatial-Temporal State Space Model
Sep 12, 2024



By sharing complementary perceptual information, multi-agent collaborative perception fosters a deeper understanding of the environment. Recent studies on collaborative perception mostly utilize CNNs or Transformers to learn feature representation and fusion in the spatial dimension, which struggle to handle long-range spatial-temporal features under limited computing and communication resources. Holistically modeling the dependencies over extensive spatial areas and extended temporal frames is crucial to enhancing feature quality. To this end, we propose a resource efficient cross-agent spatial-temporal collaborative state space model (SSM), named CollaMamba. Initially, we construct a foundational backbone network based on spatial SSM. This backbone adeptly captures positional causal dependencies from both single-agent and cross-agent views, yielding compact and comprehensive intermediate features while maintaining linear complexity. Furthermore, we devise a history-aware feature boosting module based on temporal SSM, extracting contextual cues from extended historical frames to refine vague features while preserving low overhead. Extensive experiments across several datasets demonstrate that CollaMamba outperforms state-of-the-art methods, achieving higher model accuracy while reducing computational and communication overhead by up to 71.9% and 1/64, respectively. This work pioneers the exploration of the Mamba's potential in collaborative perception. The source code will be made available.
M4Fog: A Global Multi-Regional, Multi-Modal, and Multi-Stage Dataset for Marine Fog Detection and Forecasting to Bridge Ocean and Atmosphere
Jun 19, 2024Marine fog poses a significant hazard to global shipping, necessitating effective detection and forecasting to reduce economic losses. In recent years, several machine learning (ML) methods have demonstrated superior detection accuracy compared to traditional meteorological methods. However, most of these works are developed on proprietary datasets, and the few publicly accessible datasets are often limited to simplistic toy scenarios for research purposes. To advance the field, we have collected nearly a decade's worth of multi-modal data related to continuous marine fog stages from four series of geostationary meteorological satellites, along with meteorological observations and numerical analysis, covering 15 marine regions globally where maritime fog frequently occurs. Through pixel-level manual annotation by meteorological experts, we present the most comprehensive marine fog detection and forecasting dataset to date, named M4Fog, to bridge ocean and atmosphere. The dataset comprises 68,000 "super data cubes" along four dimensions: elements, latitude, longitude and time, with a temporal resolution of half an hour and a spatial resolution of 1 kilometer. Considering practical applications, we have defined and explored three meaningful tracks with multi-metric evaluation systems: static or dynamic marine fog detection, and spatio-temporal forecasting for cloud images. Extensive benchmarking and experiments demonstrate the rationality and effectiveness of the construction concept for proposed M4Fog. The data and codes are available to whole researchers through cloud platforms to develop ML-driven marine fog solutions and mitigate adverse impacts on human activities.
Data-driven Predictive Tracking Control based on Koopman Operators
Aug 25, 2022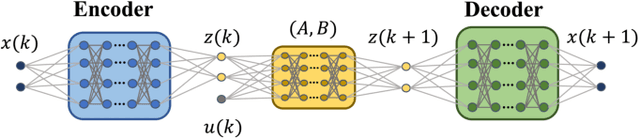
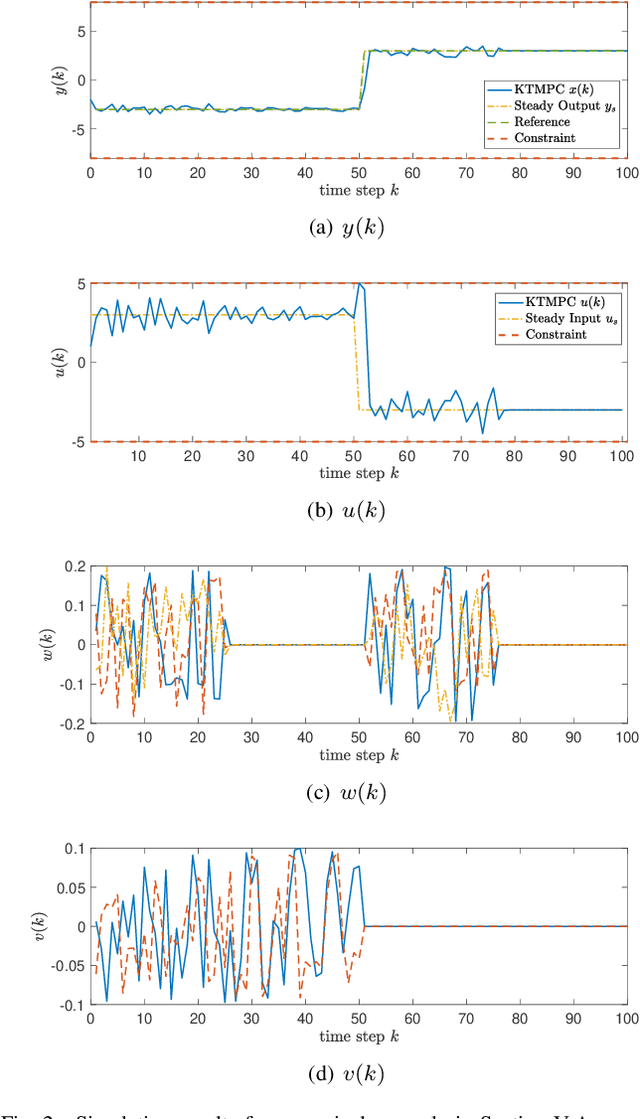
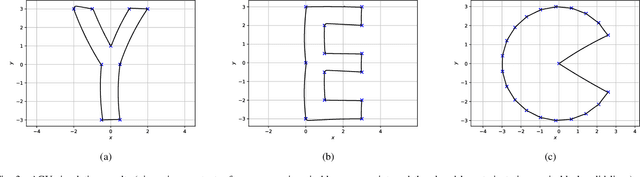
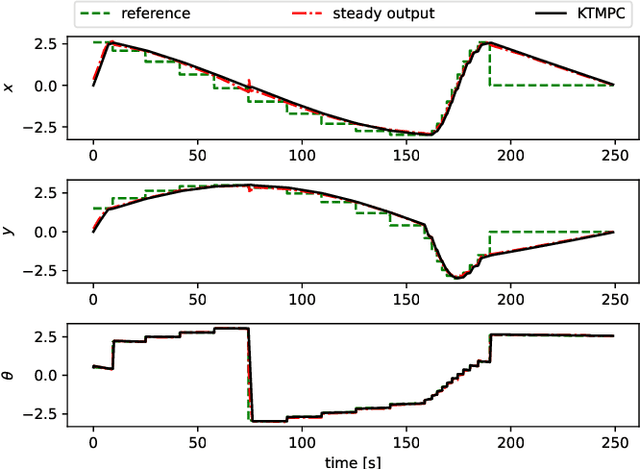
We seek to combine the nonlinear modeling capabilities of a wide class of neural networks with the safety guarantees of model predictive control (MPC) in a rigorous and online computationally tractable framework. The class of networks considered can be captured using Koopman operators, and are integrated into a Koopman-based tracking MPC (KTMPC) for nonlinear systems to track piecewise constant references. The effect of model mismatch between original nonlinear dynamics and its trained Koopman linear model is handled by using a constraint tightening approach in the proposed tracking MPC strategy. By choosing two Lyapunov candidate functions, we prove that solution is recursively feasible and input-to-state stable to a neighborhood of both online and offline optimal reachable steady outputs in the presence of bounded modeling errors. Finally, we show the results of a numerical example and an application of autonomous ground vehicle to track given references.