 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKhala: Scaling Acoustic Token Language Models Toward High-Fidelity Music Generation
May 03, 2026A common design pattern in high-quality music generation is to handle structure and fidelity in different representation spaces: a generator first models high-level structure, followed by diffusion-based or neural decoding stages that reconstruct fine details. In this work, we explore an alternative view: both may be progressively modeled within a single deep acoustic-token hierarchy. To study this, we build a 64-layer residual vector quantization (RVQ) acoustic representation and propose a two-stage coarse-to-fine generation framework. A backbone model first generates coarse acoustic tokens for the full track, and a super-resolution model then completes finer tokens within the same acoustic token space. The super-resolution stage works at full-track scale and refines tokens layer by layer while running in parallel over time, leading to a fixed 62-step inference process. To jointly improve lyric alignment and fine-detail reconstruction, we further introduce hybrid-attention training: the alignment objective uses causal attention, while layer-wise refinement uses full attention. A key finding is that text--vocal alignment can emerge within pure acoustic-token language modeling, without requiring a separate semantic token stage. Moreover, initializing the super-resolution model from the trained backbone significantly improves convergence and final quality. Taken together, our results suggest that high-quality music generation can be effectively pursued without separating structure and fidelity into heterogeneous representation spaces. Instead, both can be progressively modeled within a unified acoustic-token hierarchy, pointing toward a simpler and more unified path to high-quality music generation.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
CLaMP 2: Multimodal Music Information Retrieval Across 101 Languages Using Large Language Models
Oct 17, 2024



Challenges in managing linguistic diversity and integrating various musical modalities are faced by current music information retrieval systems. These limitations reduce their effectiveness in a global, multimodal music environment. To address these issues, we introduce CLaMP 2, a system compatible with 101 languages that supports both ABC notation (a text-based musical notation format) and MIDI (Musical Instrument Digital Interface) for music information retrieval. CLaMP 2, pre-trained on 1.5 million ABC-MIDI-text triplets, includes a multilingual text encoder and a multimodal music encoder aligned via contrastive learning. By leveraging large language models, we obtain refined and consistent multilingual descriptions at scale, significantly reducing textual noise and balancing language distribution. Our experiments show that CLaMP 2 achieves state-of-the-art results in both multilingual semantic search and music classification across modalities, thus establishing a new standard for inclusive and global music information retrieval.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023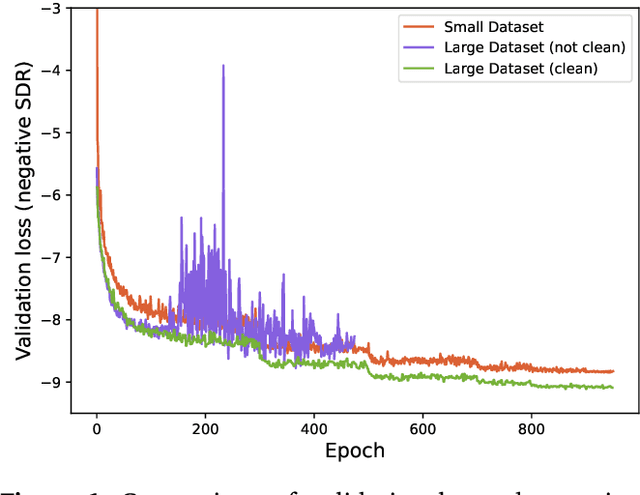
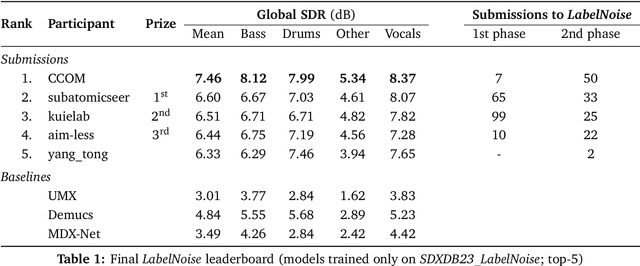

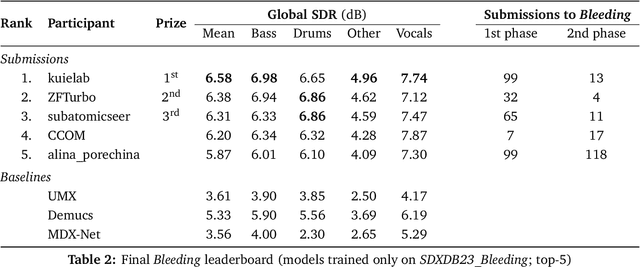
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.
Symphony Generation with Permutation Invariant Language Model
May 10, 2022
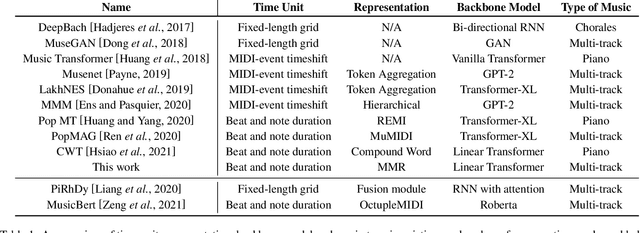
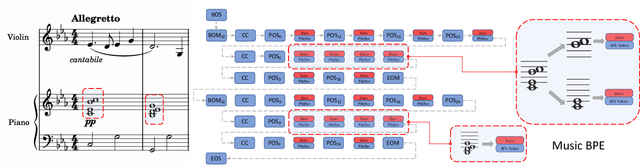
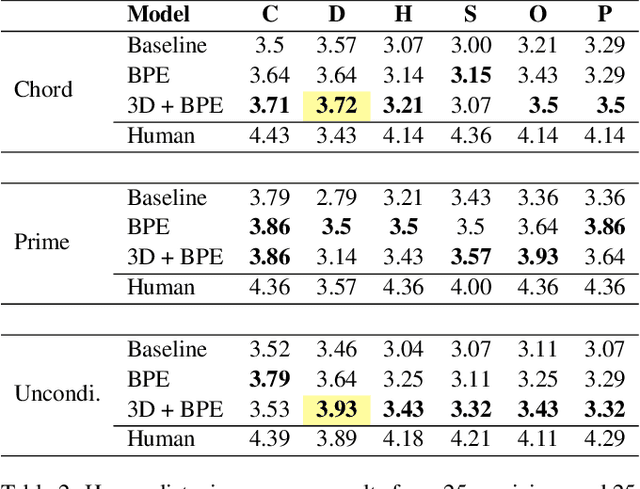
In this work, we present a symbolic symphony music generation solution, SymphonyNet, based on a permutation invariant language model. To bridge the gap between text generation and symphony generation task, we propose a novel Multi-track Multi-instrument Repeatable (MMR) representation with particular 3-D positional embedding and a modified Byte Pair Encoding algorithm (Music BPE) for music tokens. A novel linear transformer decoder architecture is introduced as a backbone for modeling extra-long sequences of symphony tokens. Meanwhile, we train the decoder to learn automatic orchestration as a joint task by masking instrument information from the input. We also introduce a large-scale symbolic symphony dataset for the advance of symphony generation research. Our empirical results show that our proposed approach can generate coherent, novel, complex and harmonious symphony compared to human composition, which is the pioneer solution for multi-track multi-instrument symbolic music generation.