 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLaMP 2: Multimodal Music Information Retrieval Across 101 Languages Using Large Language Models
Oct 17, 2024



Challenges in managing linguistic diversity and integrating various musical modalities are faced by current music information retrieval systems. These limitations reduce their effectiveness in a global, multimodal music environment. To address these issues, we introduce CLaMP 2, a system compatible with 101 languages that supports both ABC notation (a text-based musical notation format) and MIDI (Musical Instrument Digital Interface) for music information retrieval. CLaMP 2, pre-trained on 1.5 million ABC-MIDI-text triplets, includes a multilingual text encoder and a multimodal music encoder aligned via contrastive learning. By leveraging large language models, we obtain refined and consistent multilingual descriptions at scale, significantly reducing textual noise and balancing language distribution. Our experiments show that CLaMP 2 achieves state-of-the-art results in both multilingual semantic search and music classification across modalities, thus establishing a new standard for inclusive and global music information retrieval.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023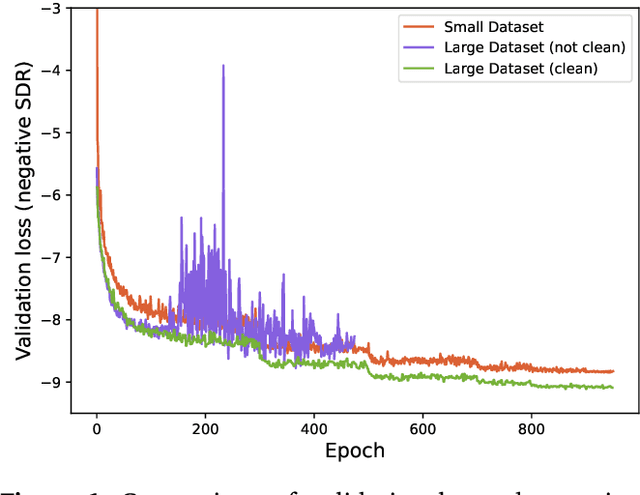
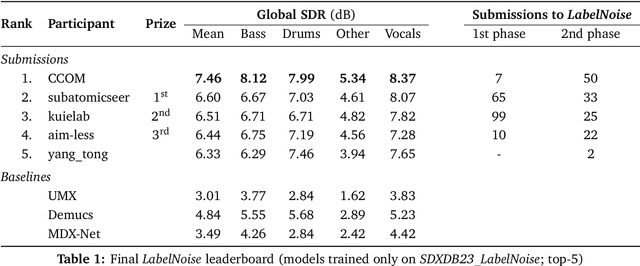

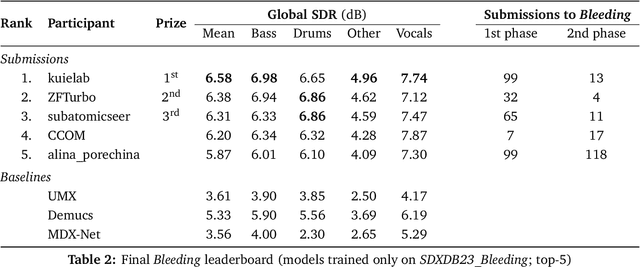
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.
Symphony Generation with Permutation Invariant Language Model
May 10, 2022
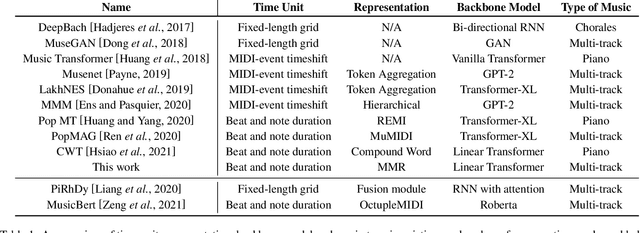
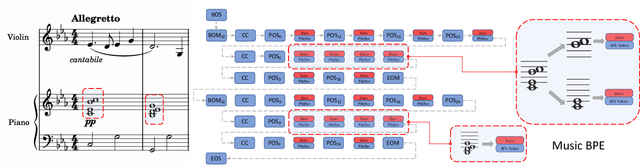
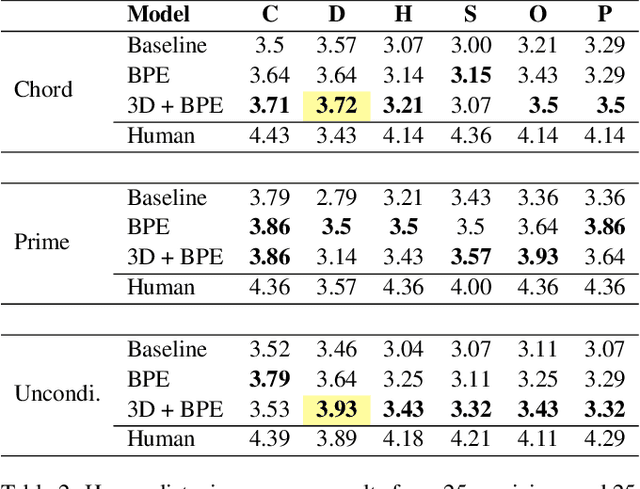
In this work, we present a symbolic symphony music generation solution, SymphonyNet, based on a permutation invariant language model. To bridge the gap between text generation and symphony generation task, we propose a novel Multi-track Multi-instrument Repeatable (MMR) representation with particular 3-D positional embedding and a modified Byte Pair Encoding algorithm (Music BPE) for music tokens. A novel linear transformer decoder architecture is introduced as a backbone for modeling extra-long sequences of symphony tokens. Meanwhile, we train the decoder to learn automatic orchestration as a joint task by masking instrument information from the input. We also introduce a large-scale symbolic symphony dataset for the advance of symphony generation research. Our empirical results show that our proposed approach can generate coherent, novel, complex and harmonious symphony compared to human composition, which is the pioneer solution for multi-track multi-instrument symbolic music generation.
CWS-PResUNet: Music Source Separation with Channel-wise Subband Phase-aware ResUNet
Dec 09, 2021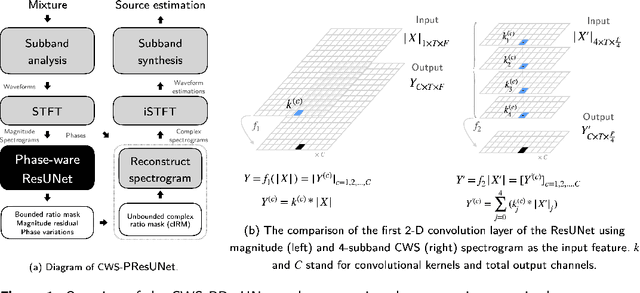
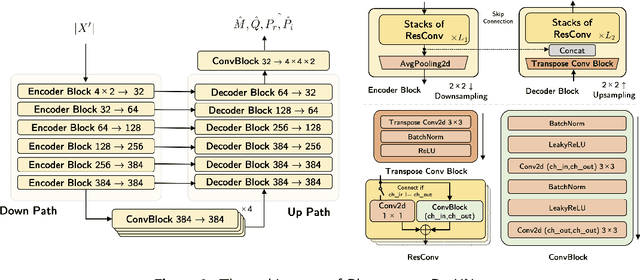
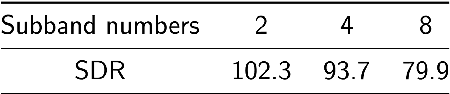
Music source separation (MSS) shows active progress with deep learning models in recent years. Many MSS models perform separations on spectrograms by estimating bounded ratio masks and reusing the phases of the mixture. When using convolutional neural networks (CNN), weights are usually shared within a spectrogram during convolution regardless of the different patterns between frequency bands. In this study, we propose a new MSS model, channel-wise subband phase-aware ResUNet (CWS-PResUNet), to decompose signals into subbands and estimate an unbound complex ideal ratio mask (cIRM) for each source. CWS-PResUNet utilizes a channel-wise subband (CWS) feature to limit unnecessary global weights sharing on the spectrogram and reduce computational resource consumptions. The saved computational cost and memory can in turn allow for a larger architecture. On the MUSDB18HQ test set, we propose a 276-layer CWS-PResUNet and achieve state-of-the-art (SoTA) performance on vocals with an 8.92 signal-to-distortion ratio (SDR) score. By combining CWS-PResUNet and Demucs, our ByteMSS system ranks the 2nd on vocals score and 5th on average score in the 2021 ISMIR Music Demixing (MDX) Challenge limited training data track (leaderboard A). Our code and pre-trained models are publicly available at: https://github.com/haoheliu/2021-ISMIR-MSS-Challenge-CWS-PResUNet
Lingxi: A Diversity-aware Chinese Modern Poetry Generation System
Aug 27, 2021
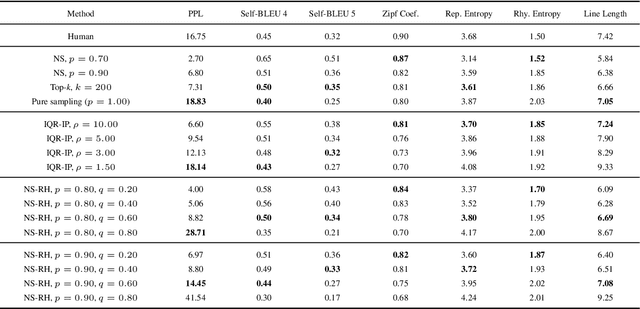
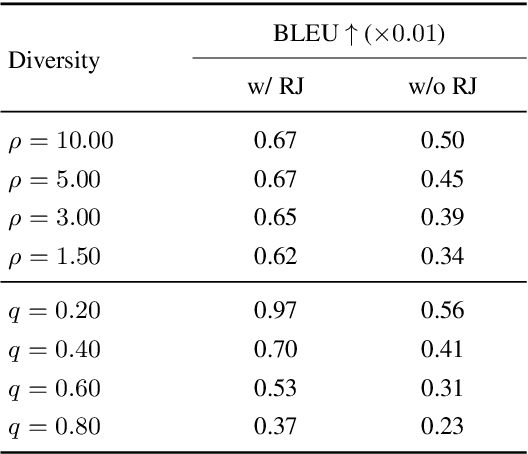

Poetry generation has been a difficult task in natural language processing. Unlike plain neural text generation tasks, poetry has a high requirement for novelty, since an easily-understood sentence with too many high frequency words might not be considered as poetic, while adequately ambiguous sentences with low frequency words can possibly be novel and creative. Inspired by this, we present Lingxi, a diversity-aware Chinese modern poetry generation system. We propose nucleus sampling with randomized head (NS-RH) algorithm, which randomizes the high frequency part ("head") of the predicted distribution, in order to emphasize on the "comparatively low frequency" words. The proposed algorithm can significantly increase the novelty of generated poetry compared with traditional sampling methods. The permutation of distribution is controllable by tuning the filtering parameter that determines the "head" to permutate, achieving diversity-aware sampling. We find that even when a large portion of filtered vocabulary is randomized, it can actually generate fluent poetry but with notably higher novelty. We also propose a semantic-similarity-based rejection sampling algorithm, which creates longer and more informative context on the basis of the short input poetry title while maintaining high semantic similarity to the title, alleviating the off-topic issue.
Embedding Calibration for Music Semantic Similarity using Auto-regressive Transformer
Mar 13, 2021
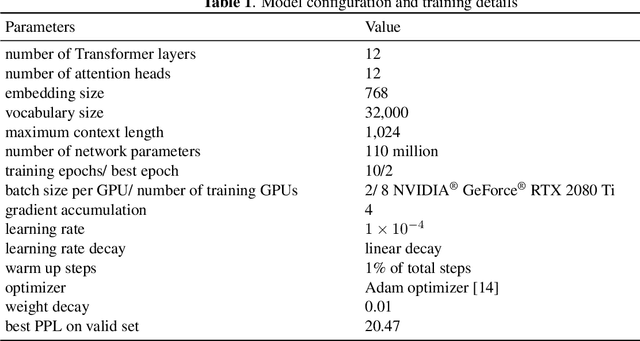
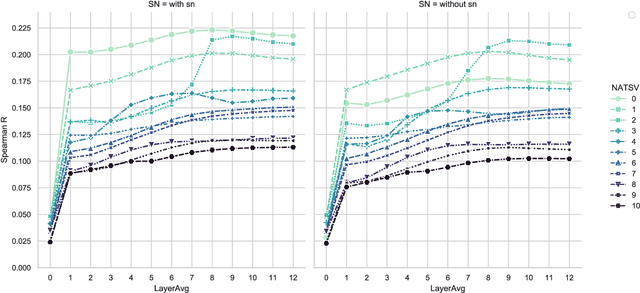
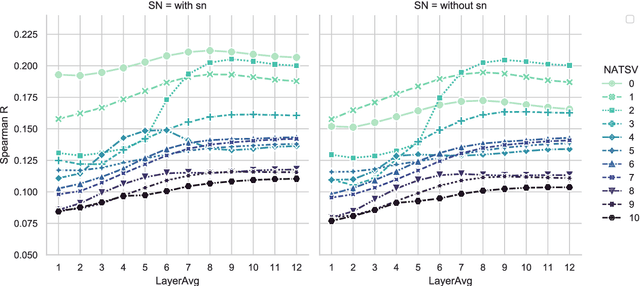
One of the advantages of using natural language processing (NLP) technology for music is to fully exploit the embedding based representation learning paradigm that can easily handle classical tasks such as semantic similarity. However, recent researches have revealed the poor performance issue of common baseline methods for semantic similarity in NLP. They show that some simple embedding calibration methods can easily promote the performance of semantic similarity without extra training hence is ready-to-use. Nevertheless, it is still unclear which is the best combination of calibration methods and by how much can we further improve the performance with such methods. Most importantly, previous works are based on auto-encoder Transformer, hence the performance under auto-regressive model for music is unclear. These render the following open questions: does embedding based semantic similarity also apply for auto-regressive music model, does poor baseline issue for semantic similarity also exists, and if so, are there unexplored embedding calibration methods to better promote the performance of music semantic similarity? In this paper, we answer these questions by exploring different combination of embedding calibration under auto-regressive language model for symbolic music. Our results show that music semantic similarity works under auto-regressive model, and also suffers from poor baseline issues like in NLP. Furthermore, we provide optimal combination of embedding calibration that has not been explored in previous researches. Results show that such combination of embedding calibration can greatly improve music semantic similarity without further training tasks.
Improving Diversity of Neural Text Generation via Inverse Probability Weighting
Mar 13, 2021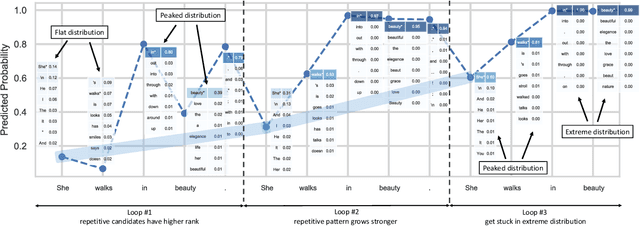
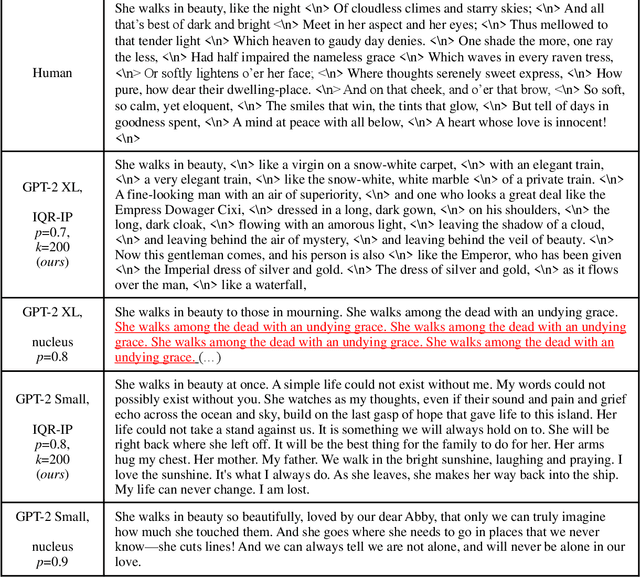
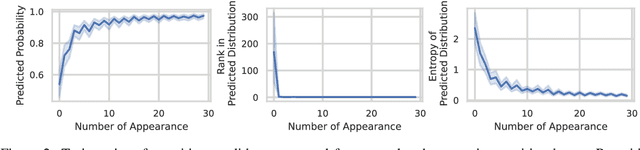
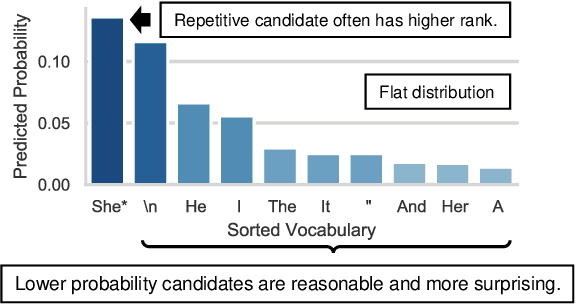
The neural network based text generation suffers from the text degeneration issue such as repetition. Although top-k sampling and nucleus sampling outperform beam search based decoding methods, they only focus on truncating the "tail" of the distribution and do not address the "head" part, which we show might contain tedious or even repetitive candidates with high probability that lead to repetition loops. They also do not fully address the issue that human text does not always favor high probability words. To explore improved diversity for text generation, we propose a heuristic sampling method inspired by inverse probability weighting. We propose to use interquartile range of the predicted distribution to determine the "head" part, then permutate and rescale the "head" with inverse probability. This aims at decreasing the probability for the tedious and possibly repetitive candidates with higher probability, and increasing the probability for the rational but more surprising candidates with lower probability. The proposed algorithm provides a controllable variation on the predicted distribution which enhances diversity without compromising rationality of the distribution. We use pre-trained language model to compare our algorithm with nucleus sampling. Results show that our algorithm can effectively increase the diversity of generated samples while achieving close resemblance to human text.