 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Calibration for Music Semantic Similarity using Auto-regressive Transformer
Paper and Code
Mar 13, 2021
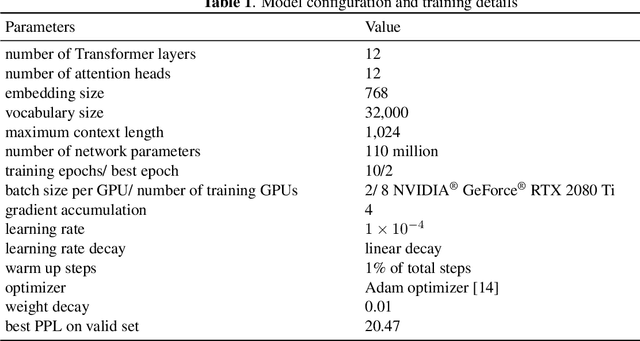
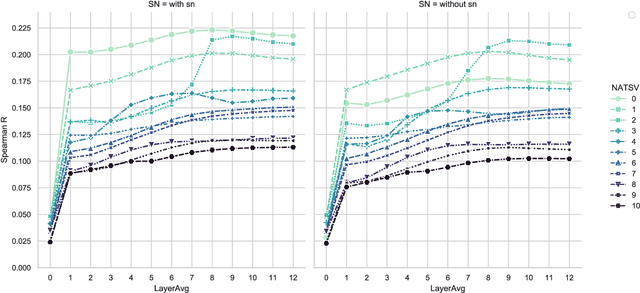
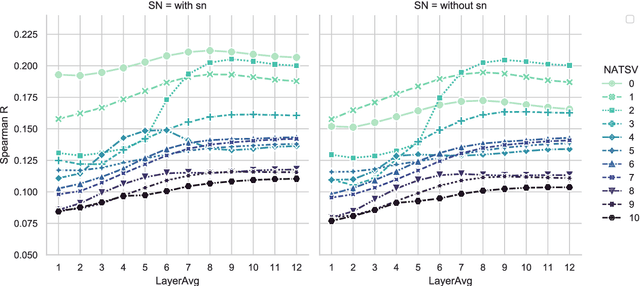
One of the advantages of using natural language processing (NLP) technology for music is to fully exploit the embedding based representation learning paradigm that can easily handle classical tasks such as semantic similarity. However, recent researches have revealed the poor performance issue of common baseline methods for semantic similarity in NLP. They show that some simple embedding calibration methods can easily promote the performance of semantic similarity without extra training hence is ready-to-use. Nevertheless, it is still unclear which is the best combination of calibration methods and by how much can we further improve the performance with such methods. Most importantly, previous works are based on auto-encoder Transformer, hence the performance under auto-regressive model for music is unclear. These render the following open questions: does embedding based semantic similarity also apply for auto-regressive music model, does poor baseline issue for semantic similarity also exists, and if so, are there unexplored embedding calibration methods to better promote the performance of music semantic similarity? In this paper, we answer these questions by exploring different combination of embedding calibration under auto-regressive language model for symbolic music. Our results show that music semantic similarity works under auto-regressive model, and also suffers from poor baseline issues like in NLP. Furthermore, we provide optimal combination of embedding calibration that has not been explored in previous researches. Results show that such combination of embedding calibration can greatly improve music semantic similarity without further training tasks.