 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM-4D: Towards Visual-based Spatial-Temporal Intelligence
Feb 28, 2026Humans are born with vision-based 4D spatial-temporal intelligence, which enables us to perceive and reason about the evolution of 3D space over time from purely visual inputs. Despite its importance, this capability remains a significant bottleneck for current multimodal large language models (MLLMs). To tackle this challenge, we introduce MLLM-4D, a comprehensive framework designed to bridge the gaps in training data curation and model post-training for spatiotemporal understanding and reasoning. On the data front, we develop a cost-efficient data curation pipeline that repurposes existing stereo video datasets into high-quality 4D spatiotemporal instructional data. This results in the MLLM4D-2M and MLLM4D-R1-30k datasets for Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT), alongside MLLM4D-Bench for comprehensive evaluation. Regarding model training, our post-training strategy establishes a foundational 4D understanding via SFT and further catalyzes 4D reasoning capabilities by employing Group Relative Policy Optimization (GRPO) with specialized Spatiotemporal Chain of Thought (ST-CoT) prompting and Spatiotemporal reward functions (ST-reward) without involving the modification of architecture. Extensive experiments demonstrate that MLLM-4D achieves state-of-the-art spatial-temporal understanding and reasoning capabilities from purely 2D RGB inputs. Project page: https://github.com/GVCLab/MLLM-4D.
Iron Sharpens Iron: Defending Against Attacks in Machine-Generated Text Detection with Adversarial Training
Feb 18, 2025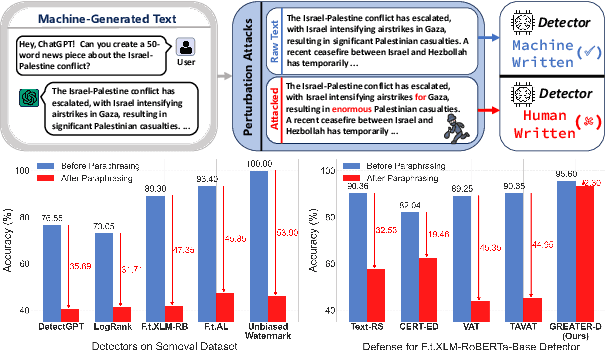
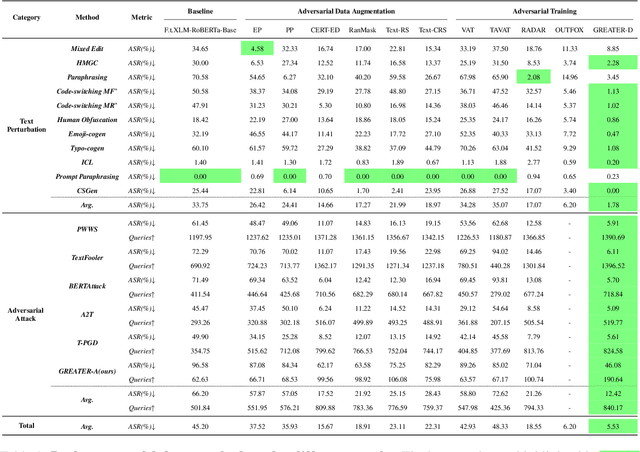
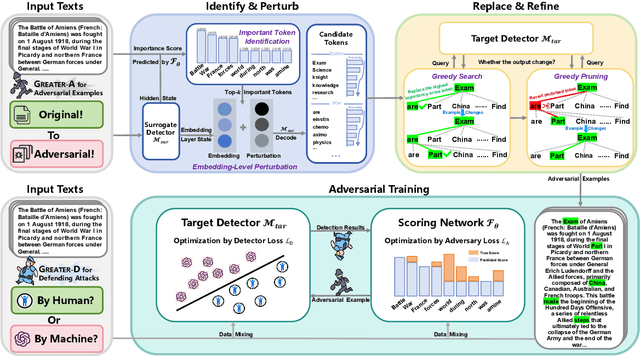
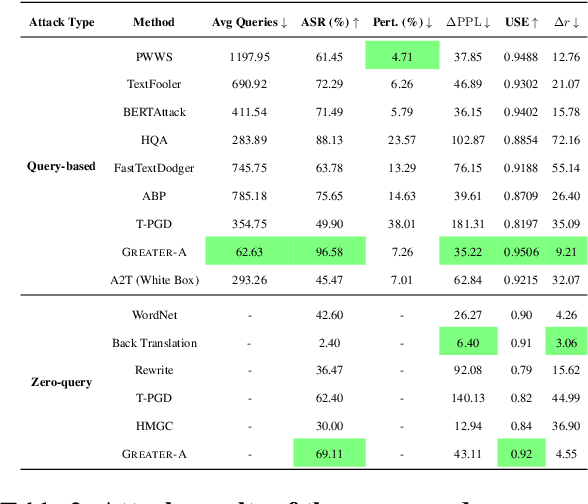
Machine-generated Text (MGT) detection is crucial for regulating and attributing online texts. While the existing MGT detectors achieve strong performance, they remain vulnerable to simple perturbations and adversarial attacks. To build an effective defense against malicious perturbations, we view MGT detection from a threat modeling perspective, that is, analyzing the model's vulnerability from an adversary's point of view and exploring effective mitigations. To this end, we introduce an adversarial framework for training a robust MGT detector, named GREedy Adversary PromoTed DefendER (GREATER). The GREATER consists of two key components: an adversary GREATER-A and a detector GREATER-D. The GREATER-D learns to defend against the adversarial attack from GREATER-A and generalizes the defense to other attacks. GREATER-A identifies and perturbs the critical tokens in embedding space, along with greedy search and pruning to generate stealthy and disruptive adversarial examples. Besides, we update the GREATER-A and GREATER-D synchronously, encouraging the GREATER-D to generalize its defense to different attacks and varying attack intensities. Our experimental results across 9 text perturbation strategies and 5 adversarial attacks show that our GREATER-D reduces the Attack Success Rate (ASR) by 10.61% compared with SOTA defense methods while our GREATER-A is demonstrated to be more effective and efficient than SOTA attack approaches.
Concentrate Attention: Towards Domain-Generalizable Prompt Optimization for Language Models
Jun 15, 2024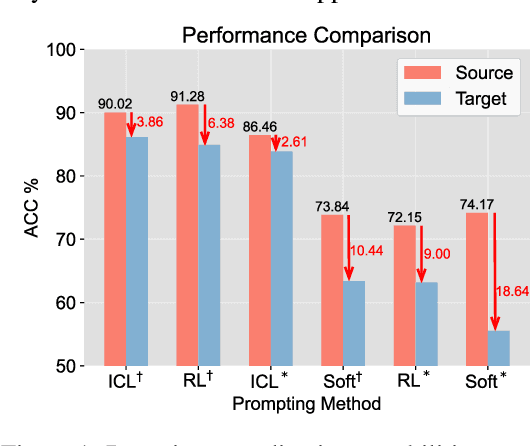
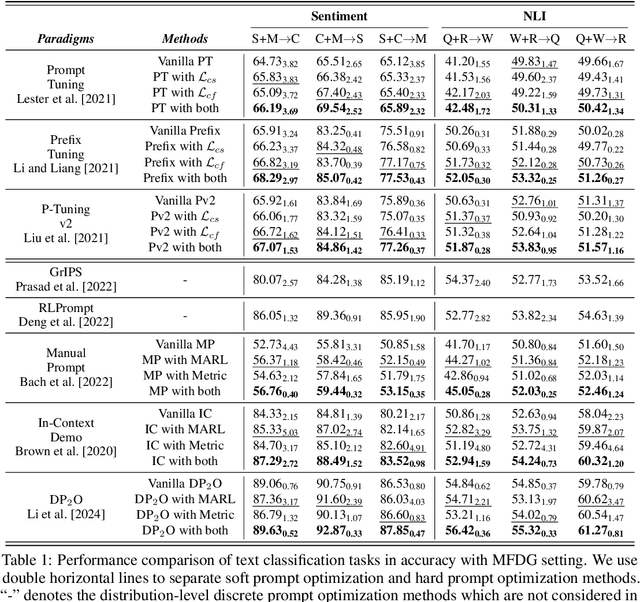

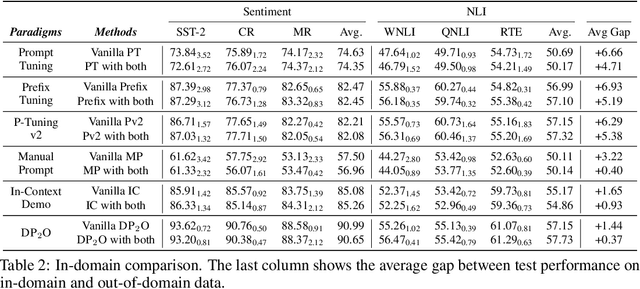
Recent advances in prompt optimization have notably enhanced the performance of pre-trained language models (PLMs) on downstream tasks. However, the potential of optimized prompts on domain generalization has been under-explored. To explore the nature of prompt generalization on unknown domains, we conduct pilot experiments and find that (i) Prompts gaining more attention weight from PLMs' deep layers are more generalizable and (ii) Prompts with more stable attention distributions in PLMs' deep layers are more generalizable. Thus, we offer a fresh objective towards domain-generalizable prompts optimization named "Concentration", which represents the "lookback" attention from the current decoding token to the prompt tokens, to increase the attention strength on prompts and reduce the fluctuation of attention distribution. We adapt this new objective to popular soft prompt and hard prompt optimization methods, respectively. Extensive experiments demonstrate that our idea improves comparison prompt optimization methods by 1.42% for soft prompt generalization and 2.16% for hard prompt generalization in accuracy on the multi-source domain generalization setting, while maintaining satisfying in-domain performance. The promising results validate the effectiveness of our proposed prompt optimization objective and provide key insights into domain-generalizable prompts.
StablePT: Towards Stable Prompting for Few-shot Learning via Input Separation
Apr 30, 2024Large language models have shown their ability to become effective few-shot learners with prompting, revoluting the paradigm of learning with data scarcity. However, this approach largely depends on the quality of prompt initialization, and always exhibits large variability among different runs. Such property makes prompt tuning highly unreliable and vulnerable to poorly constructed prompts, which limits its extension to more real-world applications. To tackle this issue, we propose to treat the hard prompt and soft prompt as separate inputs to mitigate noise brought by the prompt initialization. Furthermore, we optimize soft prompts with contrastive learning for utilizing class-aware information in the training process to maintain model performance. Experimental results demonstrate that \sysname outperforms state-of-the-art methods by 7.20% in accuracy and reduces the standard deviation by 2.02 on average. Furthermore, extensive experiments underscore its robustness and stability across 7 datasets covering various tasks.
Does DetectGPT Fully Utilize Perturbation? Selective Perturbation on Model-Based Contrastive Learning Detector would be Better
Feb 04, 2024



The burgeoning capabilities of large language models (LLMs) have raised growing concerns about abuse. DetectGPT, a zero-shot metric-based unsupervised machine-generated text detector, first introduces perturbation and shows great performance improvement. However, DetectGPT's random perturbation strategy might introduce noise, limiting the distinguishability and further performance improvements. Moreover, its logit regression module relies on setting the threshold, which harms the generalizability and applicability of individual or small-batch inputs. Hence, we propose a novel detector, Pecola, which uses selective strategy perturbation to relieve the information loss caused by random masking, and multi-pair contrastive learning to capture the implicit pattern information during perturbation, facilitating few-shot performance. The experiments show that Pecola outperforms the SOTA method by 1.20% in accuracy on average on four public datasets. We further analyze the effectiveness, robustness, and generalization of our perturbation method.
Dialogue for Prompting: a Policy-Gradient-Based Discrete Prompt Optimization for Few-shot Learning
Aug 14, 2023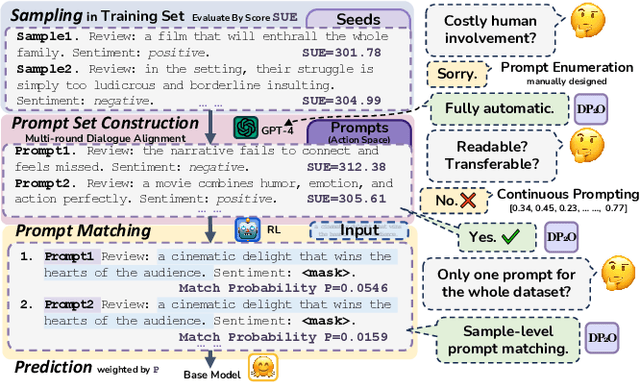
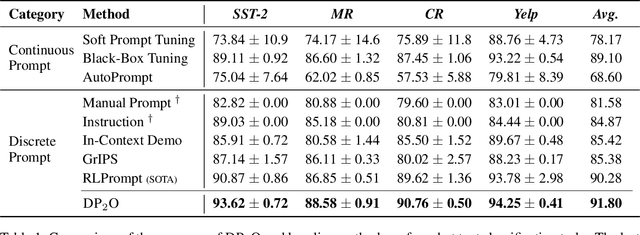
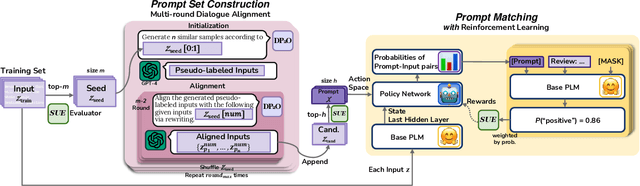

Prompt-based pre-trained language models (PLMs) paradigm have succeeded substantially in few-shot natural language processing (NLP) tasks. However, prior discrete prompt optimization methods require expert knowledge to design the base prompt set and identify high-quality prompts, which is costly, inefficient, and subjective. Meanwhile, existing continuous prompt optimization methods improve the performance by learning the ideal prompts through the gradient information of PLMs, whose high computational cost, and low readability and generalizability are often concerning. To address the research gap, we propose a Dialogue-comprised Policy-gradient-based Discrete Prompt Optimization ($DP_2O$) method. We first design a multi-round dialogue alignment strategy for readability prompt set generation based on GPT-4. Furthermore, we propose an efficient prompt screening metric to identify high-quality prompts with linear complexity. Finally, we construct a reinforcement learning (RL) framework based on policy gradients to match the prompts to inputs optimally. By training a policy network with only 0.67% of the PLM parameter size on the tasks in the few-shot setting, $DP_2O$ outperforms the state-of-the-art (SOTA) method by 1.52% in accuracy on average on four open-source datasets. Moreover, subsequent experiments also demonstrate that $DP_2O$ has good universality, robustness, and generalization ability.