 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIron Sharpens Iron: Defending Against Attacks in Machine-Generated Text Detection with Adversarial Training
Feb 18, 2025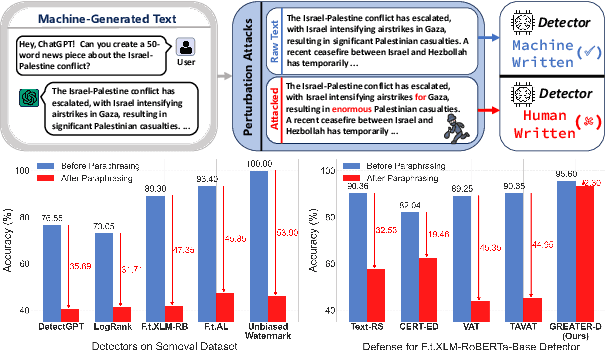
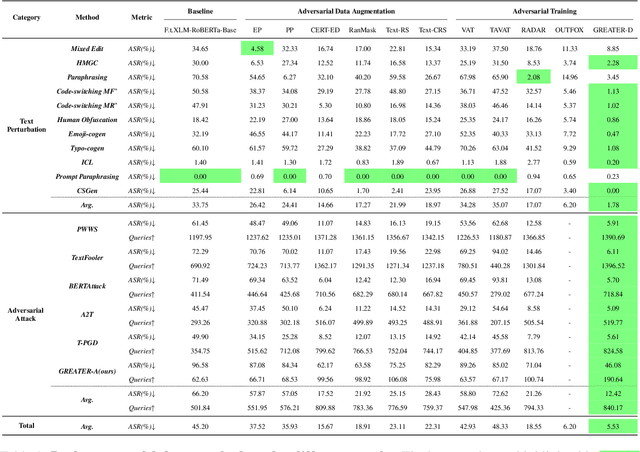
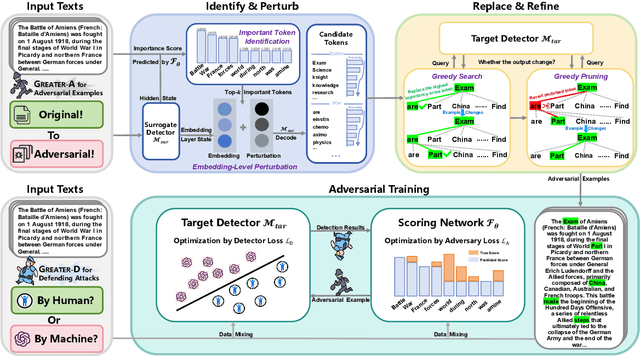
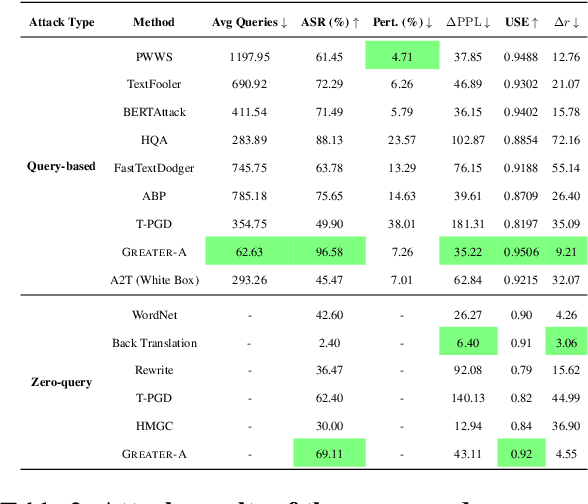
Machine-generated Text (MGT) detection is crucial for regulating and attributing online texts. While the existing MGT detectors achieve strong performance, they remain vulnerable to simple perturbations and adversarial attacks. To build an effective defense against malicious perturbations, we view MGT detection from a threat modeling perspective, that is, analyzing the model's vulnerability from an adversary's point of view and exploring effective mitigations. To this end, we introduce an adversarial framework for training a robust MGT detector, named GREedy Adversary PromoTed DefendER (GREATER). The GREATER consists of two key components: an adversary GREATER-A and a detector GREATER-D. The GREATER-D learns to defend against the adversarial attack from GREATER-A and generalizes the defense to other attacks. GREATER-A identifies and perturbs the critical tokens in embedding space, along with greedy search and pruning to generate stealthy and disruptive adversarial examples. Besides, we update the GREATER-A and GREATER-D synchronously, encouraging the GREATER-D to generalize its defense to different attacks and varying attack intensities. Our experimental results across 9 text perturbation strategies and 5 adversarial attacks show that our GREATER-D reduces the Attack Success Rate (ASR) by 10.61% compared with SOTA defense methods while our GREATER-A is demonstrated to be more effective and efficient than SOTA attack approaches.