 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwilight: Adaptive Attention Sparsity with Hierarchical Top-$p$ Pruning
Feb 06, 2025



Leveraging attention sparsity to accelerate long-context large language models (LLMs) has been a hot research topic. However, current algorithms such as sparse attention or key-value (KV) cache compression tend to use a fixed budget, which presents a significant challenge during deployment because it fails to account for the dynamic nature of real-world scenarios, where the optimal balance between accuracy and efficiency can vary greatly. In this paper, we find that borrowing top-$p$ sampling (nucleus sampling) to sparse attention can surprisingly achieve adaptive budgeting. Based on this, we propose Twilight, a framework to bring adaptive sparsity to any existing sparse attention algorithm without sacrificing their accuracy. Empirical results show that Twilight can adaptively prune at most 98% of redundant tokens, leading to $15.4\times$ acceleration in self-attention operations and $3.9\times$ acceleration in end-to-end per token latency in long context LLM decoding.
Adaptive Unscented Kalman Filter under Minimum Error Entropy with Fiducial Points for Non-Gaussian Systems
Sep 18, 2023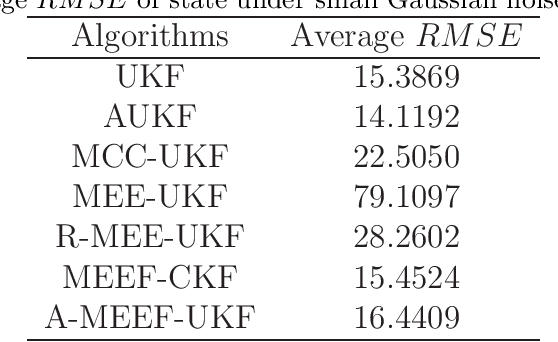
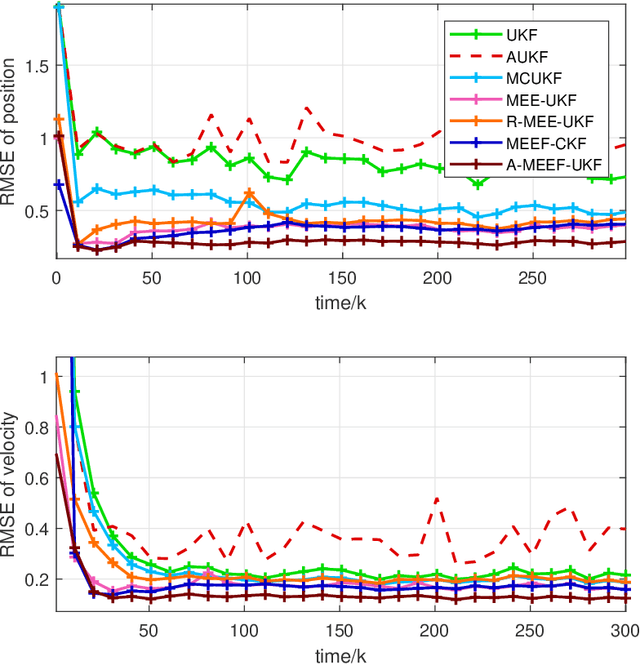
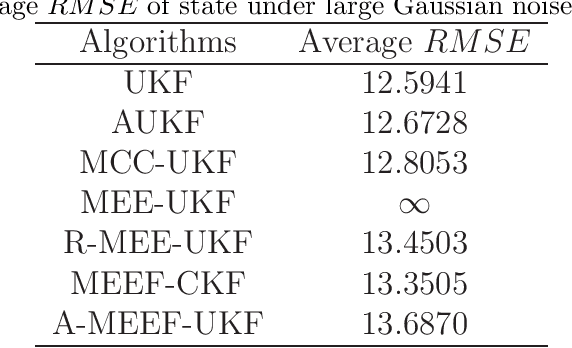
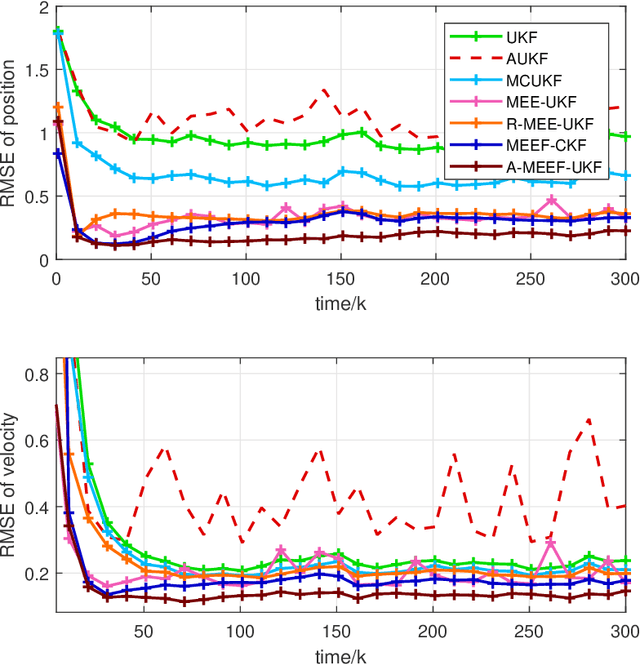
The minimum error entropy (MEE) has been extensively used in unscented Kalman filter (UKF) to handle impulsive noises or abnormal measurement data in non-Gaussian systems. However, the MEE-UKF has poor numerical stability due to the inverse operation of singular matrix. In this paper, a novel UKF based on minimum error entropy with fiducial points (MEEF) is proposed \textcolor{black}{to improve the problem of non-positive definite key matrix. By adding the correntropy to the error entropy, the proposed algorithm further enhances the ability of suppressing impulse noise and outliers. At the same time, considering the uncertainty of noise distribution, the modified Sage-Husa estimator of noise statistics is introduced to adaptively update the noise covariance matrix. In addition, the convergence analysis of the proposed algorithm provides a guidance for the selection of kernel width. The robustness and estimation accuracy of the proposed algorithm are manifested by the state tracking examples under complex non-Gaussian noises.
* 29 pages,6 figures