 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgos: Agentic Time-Series Anomaly Detection with Autonomous Rule Generation via Large Language Models
Jan 24, 2025



Observability in cloud infrastructure is critical for service providers, driving the widespread adoption of anomaly detection systems for monitoring metrics. However, existing systems often struggle to simultaneously achieve explainability, reproducibility, and autonomy, which are three indispensable properties for production use. We introduce Argos, an agentic system for detecting time-series anomalies in cloud infrastructure by leveraging large language models (LLMs). Argos proposes to use explainable and reproducible anomaly rules as intermediate representation and employs LLMs to autonomously generate such rules. The system will efficiently train error-free and accuracy-guaranteed anomaly rules through multiple collaborative agents and deploy the trained rules for low-cost online anomaly detection. Through evaluation results, we demonstrate that Argos outperforms state-of-the-art methods, increasing $F_1$ scores by up to $9.5\%$ and $28.3\%$ on public anomaly detection datasets and an internal dataset collected from Microsoft, respectively.
AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Clouds
Jan 12, 2025



AI for IT Operations (AIOps) aims to automate complex operational tasks, such as fault localization and root cause analysis, to reduce human workload and minimize customer impact. While traditional DevOps tools and AIOps algorithms often focus on addressing isolated operational tasks, recent advances in Large Language Models (LLMs) and AI agents are revolutionizing AIOps by enabling end-to-end and multitask automation. This paper envisions a future where AI agents autonomously manage operational tasks throughout the entire incident lifecycle, leading to self-healing cloud systems, a paradigm we term AgentOps. Realizing this vision requires a comprehensive framework to guide the design, development, and evaluation of these agents. To this end, we present AIOPSLAB, a framework that not only deploys microservice cloud environments, injects faults, generates workloads, and exports telemetry data but also orchestrates these components and provides interfaces for interacting with and evaluating agents. We discuss the key requirements for such a holistic framework and demonstrate how AIOPSLAB can facilitate the evaluation of next-generation AIOps agents. Through evaluations of state-of-the-art LLM agents within the benchmark created by AIOPSLAB, we provide insights into their capabilities and limitations in handling complex operational tasks in cloud environments.
Building AI Agents for Autonomous Clouds: Challenges and Design Principles
Jul 16, 2024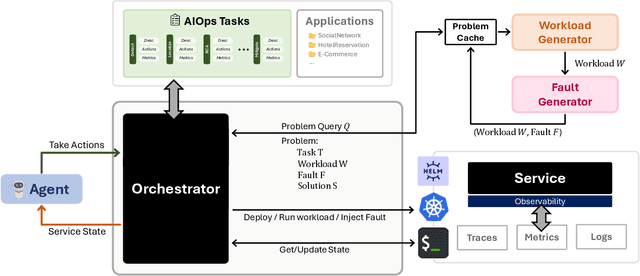


The rapid growth in the use of Large Language Models (LLMs) and AI Agents as part of software development and deployment is revolutionizing the information technology landscape. While code generation receives significant attention, a higher-impact application lies in using AI agents for operational resilience of cloud services, which currently require significant human effort and domain knowledge. There is a growing interest in AI for IT Operations (AIOps) which aims to automate complex operational tasks, like fault localization and root cause analysis, thereby reducing human intervention and customer impact. However, achieving the vision of autonomous and self-healing clouds though AIOps is hampered by the lack of standardized frameworks for building, evaluating, and improving AIOps agents. This vision paper lays the groundwork for such a framework by first framing the requirements and then discussing design decisions that satisfy them. We also propose AIOpsLab, a prototype implementation leveraging agent-cloud-interface that orchestrates an application, injects real-time faults using chaos engineering, and interfaces with an agent to localize and resolve the faults. We report promising results and lay the groundwork to build a modular and robust framework for building, evaluating, and improving agents for autonomous clouds.
Cloud Atlas: Efficient Fault Localization for Cloud Systems using Language Models and Causal Insight
Jul 11, 2024Runtime failure and performance degradation is commonplace in modern cloud systems. For cloud providers, automatically determining the root cause of incidents is paramount to ensuring high reliability and availability as prompt fault localization can enable faster diagnosis and triage for timely resolution. A compelling solution explored in recent work is causal reasoning using causal graphs to capture relationships between varied cloud system performance metrics. To be effective, however, systems developers must correctly define the causal graph of their system, which is a time-consuming, brittle, and challenging task that increases in difficulty for large and dynamic systems and requires domain expertise. Alternatively, automated data-driven approaches have limited efficacy for cloud systems due to the inherent rarity of incidents. In this work, we present Atlas, a novel approach to automatically synthesizing causal graphs for cloud systems. Atlas leverages large language models (LLMs) to generate causal graphs using system documentation, telemetry, and deployment feedback. Atlas is complementary to data-driven causal discovery techniques, and we further enhance Atlas with a data-driven validation step. We evaluate Atlas across a range of fault localization scenarios and demonstrate that Atlas is capable of generating causal graphs in a scalable and generalizable manner, with performance that far surpasses that of data-driven algorithms and is commensurate to the ground-truth baseline.
Serving DNNs like Clockwork: Performance Predictability from the Bottom Up
Jun 03, 2020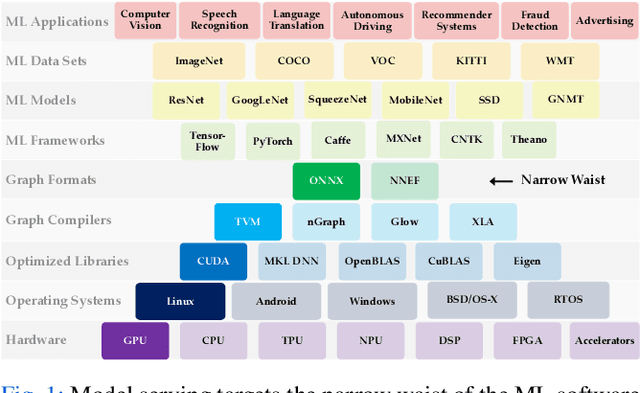
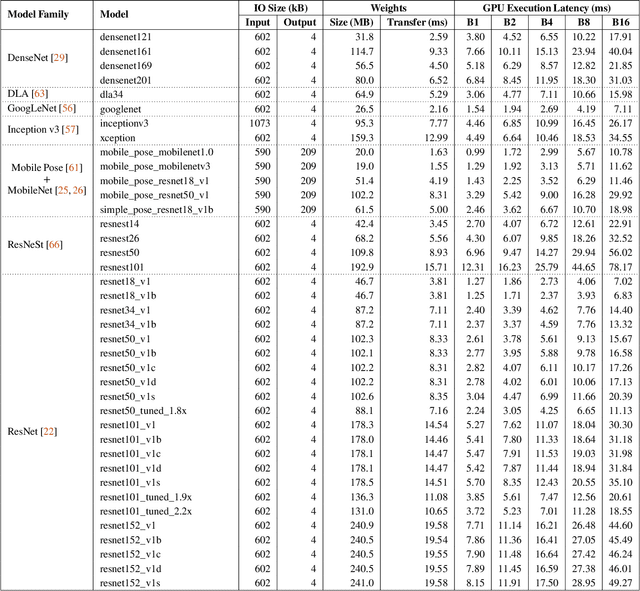
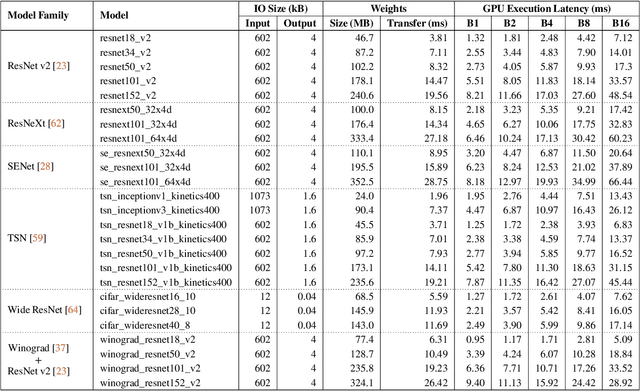
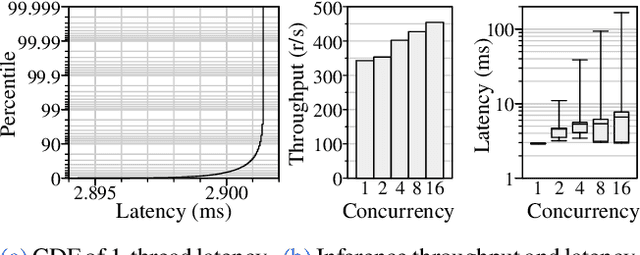
Machine learning inference is becoming a core building block for interactive web applications. As a result, the underlying model serving systems on which these applications depend must consistently meet low latency targets. Existing model serving architectures use well-known reactive techniques to alleviate common-case sources of latency, but cannot effectively curtail tail latency caused by unpredictable execution times. Yet the underlying execution times are not fundamentally unpredictable-on the contrary we observe that inference using Deep Neural Network (DNN) models has deterministic performance. Here, starting with the predictable execution times of individual DNN inferences, we adopt a principled design methodology to successively build a fully distributed model serving system that achieves predictable end-to-end performance. We evaluate our implementation, Clockwork, using production trace workloads, and show that Clockwork can support thousands of models while simultaneously meeting 100 ms latency targets for 99.997% of requests. We further demonstrate that Clockwork exploits predictable execution times to achieve tight request-level service-level objectives (SLOs) as well as a high degree of request-level performance isolation.