 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigma-MoE-Tiny Technical Report
Dec 19, 2025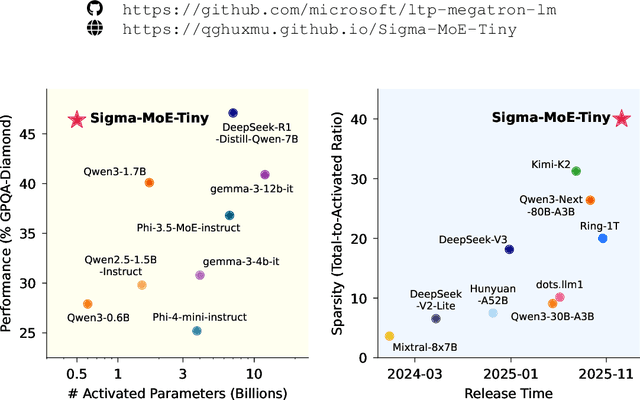

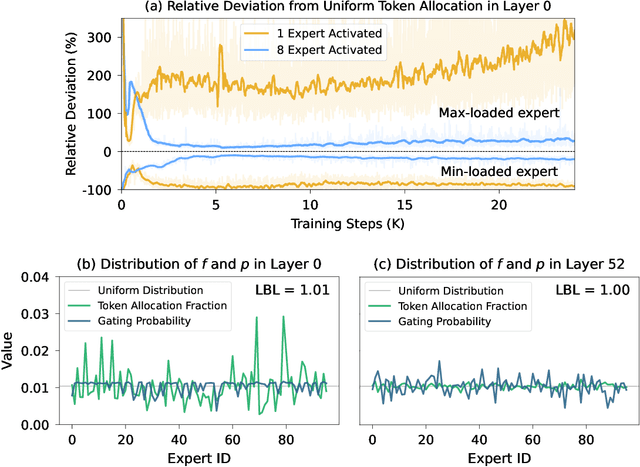
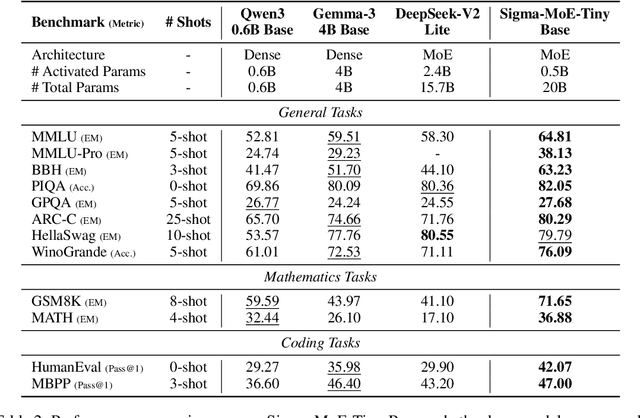
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025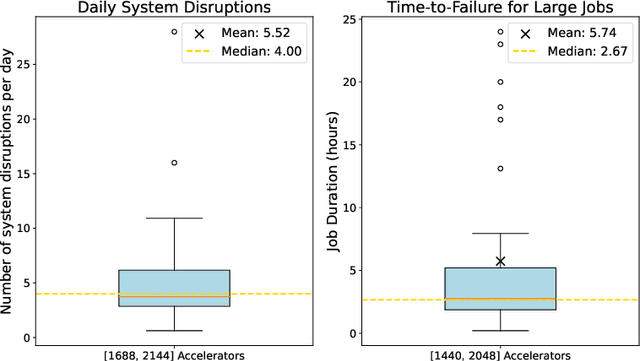

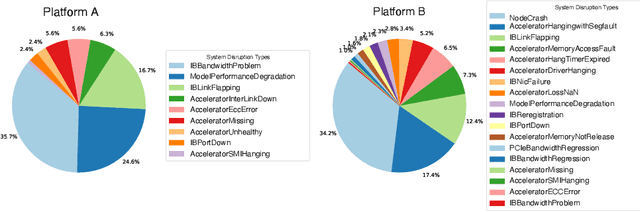

An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
Wasserstein-Aligned Hyperbolic Multi-View Clustering
Dec 10, 2025Multi-view clustering (MVC) aims to uncover the latent structure of multi-view data by learning view-common and view-specific information. Although recent studies have explored hyperbolic representations for better tackling the representation gap between different views, they focus primarily on instance-level alignment and neglect global semantic consistency, rendering them vulnerable to view-specific information (\textit{e.g.}, noise and cross-view discrepancies). To this end, this paper proposes a novel Wasserstein-Aligned Hyperbolic (WAH) framework for multi-view clustering. Specifically, our method exploits a view-specific hyperbolic encoder for each view to embed features into the Lorentz manifold for hierarchical semantic modeling. Whereafter, a global semantic loss based on the hyperbolic sliced-Wasserstein distance is introduced to align manifold distributions across views. This is followed by soft cluster assignments to encourage cross-view semantic consistency. Extensive experiments on multiple benchmarking datasets show that our method can achieve SOTA clustering performance.
Argos: Agentic Time-Series Anomaly Detection with Autonomous Rule Generation via Large Language Models
Jan 24, 2025



Observability in cloud infrastructure is critical for service providers, driving the widespread adoption of anomaly detection systems for monitoring metrics. However, existing systems often struggle to simultaneously achieve explainability, reproducibility, and autonomy, which are three indispensable properties for production use. We introduce Argos, an agentic system for detecting time-series anomalies in cloud infrastructure by leveraging large language models (LLMs). Argos proposes to use explainable and reproducible anomaly rules as intermediate representation and employs LLMs to autonomously generate such rules. The system will efficiently train error-free and accuracy-guaranteed anomaly rules through multiple collaborative agents and deploy the trained rules for low-cost online anomaly detection. Through evaluation results, we demonstrate that Argos outperforms state-of-the-art methods, increasing $F_1$ scores by up to $9.5\%$ and $28.3\%$ on public anomaly detection datasets and an internal dataset collected from Microsoft, respectively.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
Infrared and visible image fusion based on Multi-State Contextual Hidden Markov Model
Jan 26, 2022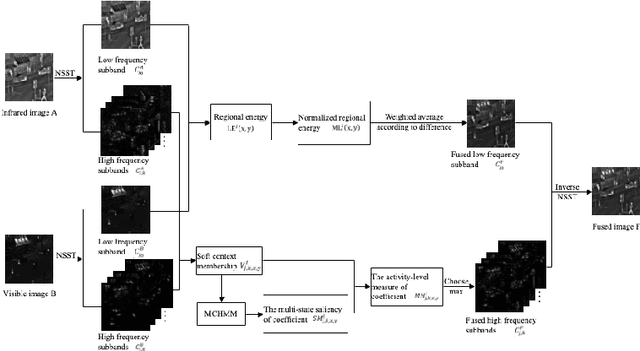
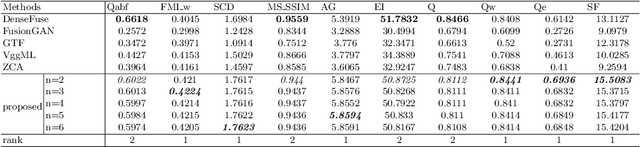
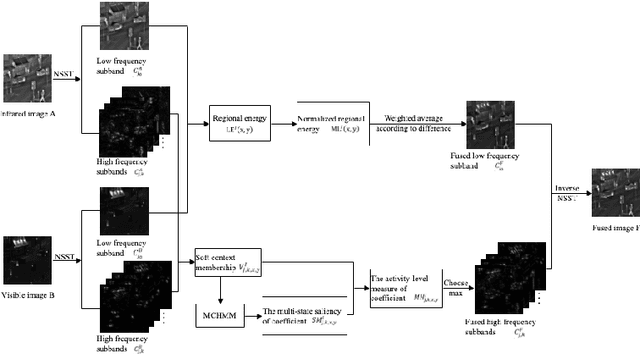
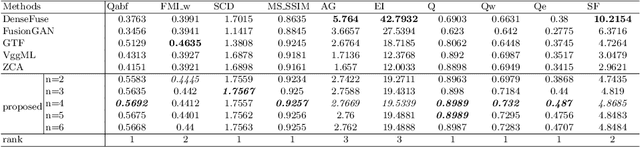
The traditional two-state hidden Markov model divides the high frequency coefficients only into two states (large and small states). Such scheme is prone to produce an inaccurate statistical model for the high frequency subband and reduces the quality of fusion result. In this paper, a fine-grained multi-state contextual hidden Markov model (MCHMM) is proposed for infrared and visible image fusion in the non-subsampled Shearlet domain, which takes full consideration of the strong correlations and level of details of NSST coefficients. To this end, an accurate soft context variable is designed correspondingly from the perspective of context correlation. Then, the statistical features provided by MCHMM are utilized for the fusion of high frequency subbands. To ensure the visual quality, a fusion strategy based on the difference in regional energy is proposed as well for lowfrequency subbands. Experimental results demonstrate that the proposed method can achieve a superior performance compared with other fusion methods in both subjective and objective aspects.