 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Safety-Fidelity Trade-off: Massive-Variate Time Series Forecasting for Power Systems via Probabilistic Scenarios
Jun 11, 2026Probabilistic forecasting models are increasingly deployed on multivariate systems with distinct channel physics and operational constraints, but existing benchmarks evaluate neither property at scale. Public canonical multivariate benchmarks cap out at 2,000 channels, while power-system benchmarks either lack temporal structure or probabilistic evaluation. We introduce PowerPhase, a probabilistic forecasting benchmark built on six transmission grids ranging from 2,000 to 36,964 jointly forecasted channels, more than an order of magnitude beyond popular canonical multivariate benchmarks. Each target trajectory is the output of an AC power-flow solve, and PowerPhase ships with constraint-aware metrics, including Safety_mBrier, NECV, and CVaR-alpha, that complement CRPS and Distortion. Across eight baselines and three seeds, distributional accuracy and constraint satisfaction rank models differently, a trade-off we term safety-fidelity. We further propose PowerForge, a scenario-based quantile forecaster with type-specific decoding heads and a causal bridge between variable groups, which achieves the best average rank on every grid.
UniLab: A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
Jun 02, 2026Simulation-based RL for contemporary robot control is increasingly organized around GPU-resident simulation: physics, rollout collection, and learning are placed on a single GPU-centric execution path. This paradigm has greatly improved training speed, but it has also encouraged a default assumption that efficient training requires physics to reside on the GPU. We revisit this assumption. Our view is that, in simulation-dominated robot control, the essential question is not which processor runs physics, but whether simulation throughput, policy learning, and runtime synchronization form an efficient end-to-end loop. We present UniLab, a heterogeneous CPU-simulation / GPU-learning architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. UniLab is implemented as a complete and extensible training system using MuJoCoUni and MotrixSim CPU-batched physics backends, supporting PPO, FastSAC, FlashSAC, and APPO. On representative simulation-based robot control tasks, UniLab improves end-to-end training efficiency by 3--10$\times$ under the same hardware configuration, while reducing dependence on the NVIDIA CUDA-based software stack and supporting cross-platform execution on the Apple macOS platform and the AMD ROCm and Intel XPU accelerator backends. These results show that GPU simulation is an effective path to efficient training, but not a necessary one, broadening the practical system choices available for robot RL training. Project page: https://unilabsim.github.io.
A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
May 28, 2026Simulation-based RL for contemporary robot control is increasingly organized around GPU-resident simulation: physics, rollout collection, and learning are placed on a single GPU-centric execution path. This paradigm has greatly improved training speed, but it has also encouraged a default assumption that efficient training requires physics to reside on the GPU. We revisit this assumption. Our view is that, in simulation-dominated robot control, the essential question is not which processor runs physics, but whether simulation throughput, policy learning, and runtime synchronization form an efficient end-to-end loop. We present UniLab, a heterogeneous CPU-simulation / GPU-learning architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. UniLab is implemented as a complete and extensible training system using MuJoCoUni and MotrixSim CPU-batched physics backends, supporting PPO, SAC, FlashSAC, TD3, and APPO. On representative simulation-based robot control tasks, UniLab improves end-to-end training efficiency by 3--10$\times$ under the same hardware configuration, while reducing dependence on the NVIDIA CUDA-based software stack and supporting cross-platform execution on the Apple macOS platform and the AMD ROCm and Intel XPU accelerator backends. These results show that GPU simulation is an effective path to efficient training, but not a necessary one, broadening the practical system choices available for robot RL training. Project page: https://github.com/unilabsim/UniLab.
GS-Playground: A High-Throughput Photorealistic Simulator for Vision-Informed Robot Learning
Apr 28, 2026Embodied AI research is undergoing a shift toward vision-centric perceptual paradigms. While massively parallel simulators have catalyzed breakthroughs in proprioception-based locomotion, their potential remains largely untapped for vision-informed tasks due to the prohibitive computational overhead of large-scale photorealistic rendering. Furthermore, the creation of simulation-ready 3D assets heavily relies on labor-intensive manual modeling, while the significant sim-to-real physical gap hinders the transfer of contact-rich manipulation policies. To address these bottlenecks, we propose GS-Playground, a multi-modal simulation framework designed to accelerate end-to-end perceptual learning. We develop a novel high-performance parallel physics engine, specifically designed to integrate with a batch 3D Gaussian Splatting (3DGS) rendering pipeline to ensure high-fidelity synchronization. Our system achieves a breakthrough throughput of 10^4 FPS at 640x480 resolution, significantly lowering the barrier for large-scale visual RL. Additionally, we introduce an automated Real2Sim workflow that reconstructs photorealistic, physically consistent, and memory-efficient environments, streamlining the generation of complex simulation-ready scenes. Extensive experiments on locomotion, navigation, and manipulation demonstrate that GS-Playground effectively bridges the perceptual and physical gaps across diverse embodied tasks. Project homepage: https://gsplayground.github.io.
Discriminative Pedestrian Features and Gated Channel Attention for Clothes-Changing Person Re-Identification
Oct 29, 2024
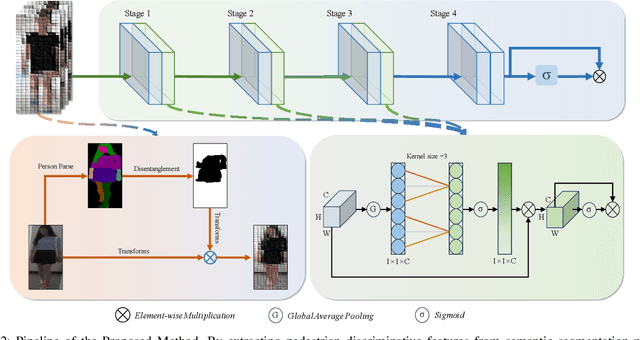
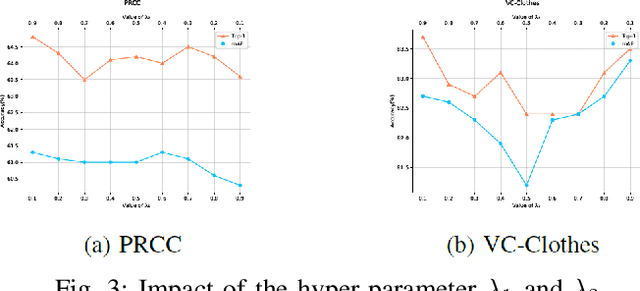
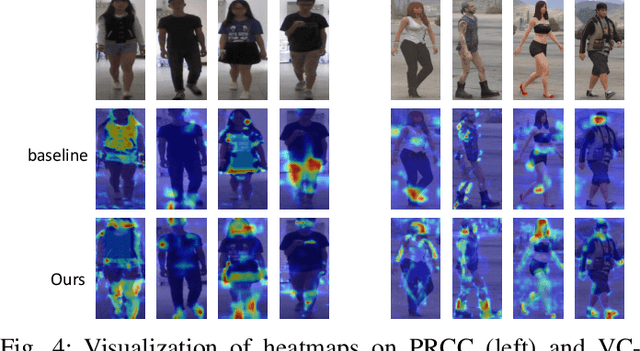
In public safety and social life, the task of Clothes-Changing Person Re-Identification (CC-ReID) has become increasingly significant. However, this task faces considerable challenges due to appearance changes caused by clothing alterations. Addressing this issue, this paper proposes an innovative method for disentangled feature extraction, effectively extracting discriminative features from pedestrian images that are invariant to clothing. This method leverages pedestrian parsing techniques to identify and retain features closely associated with individual identity while disregarding the variable nature of clothing attributes. Furthermore, this study introduces a gated channel attention mechanism, which, by adjusting the network's focus, aids the model in more effectively learning and emphasizing features critical for pedestrian identity recognition. Extensive experiments conducted on two standard CC-ReID datasets validate the effectiveness of the proposed approach, with performance surpassing current leading solutions. The Top-1 accuracy under clothing change scenarios on the PRCC and VC-Clothes datasets reached 64.8% and 83.7%, respectively.
Exploring the Potential of Large Language Models in Artistic Creation: Collaboration and Reflection on Creative Programming
Feb 15, 2024



Recently, the potential of large language models (LLMs) has been widely used in assisting programming. However, current research does not explore the artist potential of LLMs in creative coding within artist and AI collaboration. Our work probes the reflection type of artists in the creation process with such collaboration. We compare two common collaboration approaches: invoking the entire program and multiple subtasks. Our findings exhibit artists' different stimulated reflections in two different methods. Our finding also shows the correlation of reflection type with user performance, user satisfaction, and subjective experience in two collaborations through conducting two methods, including experimental data and qualitative interviews. In this sense, our work reveals the artistic potential of LLM in creative coding. Meanwhile, we provide a critical lens of human-AI collaboration from the artists' perspective and expound design suggestions for future work of AI-assisted creative tasks.
VR PreM+ : An Immersive Pre-learning Branching Visualization System for Museum Tours
Nov 01, 2023
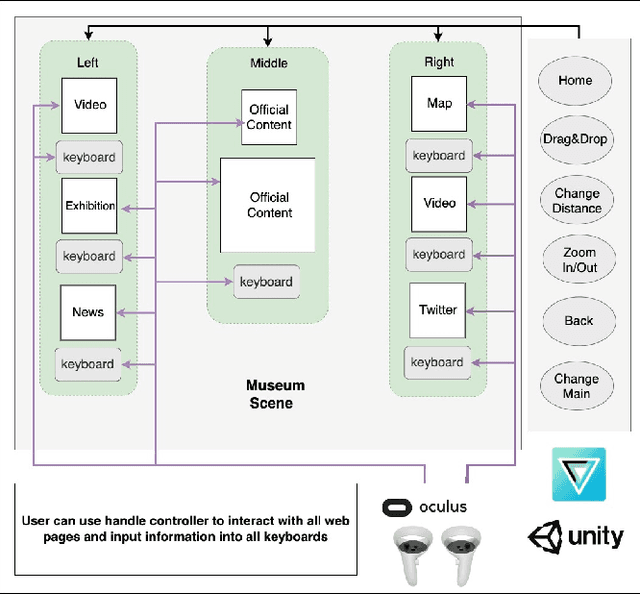

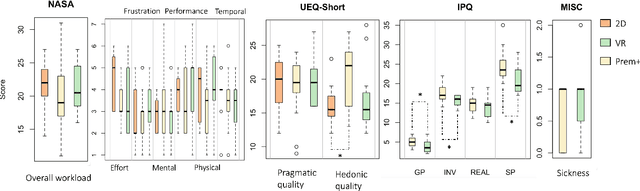
We present VR PreM+, an innovative VR system designed to enhance web exploration beyond traditional computer screens. Unlike static 2D displays, VR PreM+ leverages 3D environments to create an immersive pre-learning experience. Using keyword-based information retrieval allows users to manage and connect various content sources in a dynamic 3D space, improving communication and data comparison. We conducted preliminary and user studies that demonstrated efficient information retrieval, increased user engagement, and a greater sense of presence. These findings yielded three design guidelines for future VR information systems: display, interaction, and user-centric design. VR PreM+ bridges the gap between traditional web browsing and immersive VR, offering an interactive and comprehensive approach to information acquisition. It holds promise for research, education, and beyond.
Towards Computational Architecture of Liberty: A Comprehensive Survey on Deep Learning for Generating Virtual Architecture in the Metaverse
Apr 30, 2023
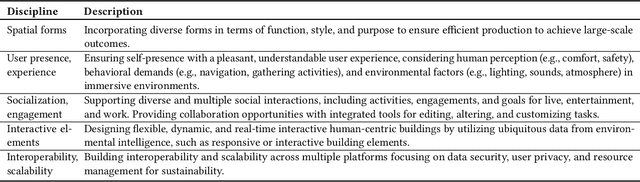


3D shape generation techniques utilizing deep learning are increasing attention from both computer vision and architectural design. This survey focuses on investigating and comparing the current latest approaches to 3D object generation with deep generative models (DGMs), including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), 3D-aware images, and diffusion models. We discuss 187 articles (80.7% of articles published between 2018-2022) to review the field of generated possibilities of architecture in virtual environments, limited to the architecture form. We provide an overview of architectural research, virtual environment, and related technical approaches, followed by a review of recent trends in discrete voxel generation, 3D models generated from 2D images, and conditional parameters. We highlight under-explored issues in 3D generation and parameterized control that is worth further investigation. Moreover, we speculate that four research agendas including data limitation, editability, evaluation metrics, and human-computer interaction are important enablers of ubiquitous interaction with immersive systems in architecture for computer-aided design Our work contributes to researchers' understanding of the current potential and future needs of deep learnings in generating virtual architecture.
Infrared and visible image fusion based on Multi-State Contextual Hidden Markov Model
Jan 26, 2022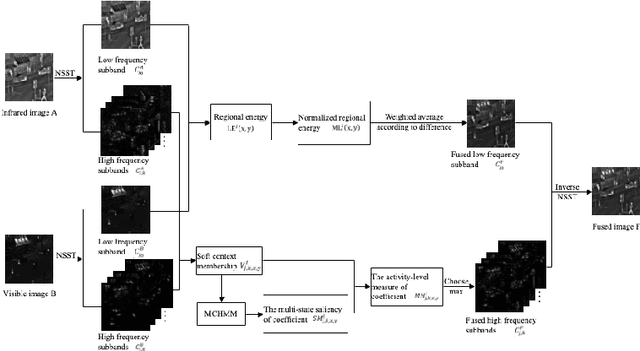
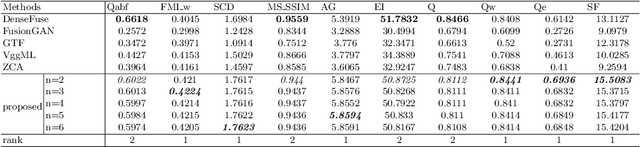
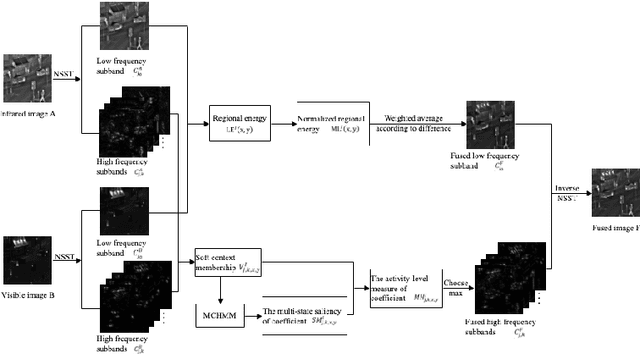
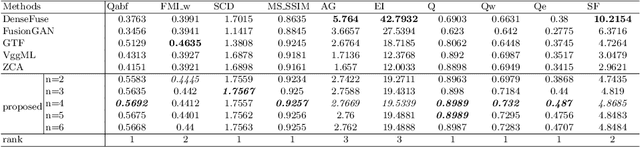
The traditional two-state hidden Markov model divides the high frequency coefficients only into two states (large and small states). Such scheme is prone to produce an inaccurate statistical model for the high frequency subband and reduces the quality of fusion result. In this paper, a fine-grained multi-state contextual hidden Markov model (MCHMM) is proposed for infrared and visible image fusion in the non-subsampled Shearlet domain, which takes full consideration of the strong correlations and level of details of NSST coefficients. To this end, an accurate soft context variable is designed correspondingly from the perspective of context correlation. Then, the statistical features provided by MCHMM are utilized for the fusion of high frequency subbands. To ensure the visual quality, a fusion strategy based on the difference in regional energy is proposed as well for lowfrequency subbands. Experimental results demonstrate that the proposed method can achieve a superior performance compared with other fusion methods in both subjective and objective aspects.