 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Generative Infrared and Visible Image Fusion Based on Human Cognitive Laws
Oct 30, 2025Existing infrared and visible image fusion methods often face the dilemma of balancing modal information. Generative fusion methods reconstruct fused images by learning from data distributions, but their generative capabilities remain limited. Moreover, the lack of interpretability in modal information selection further affects the reliability and consistency of fusion results in complex scenarios. This manuscript revisits the essence of generative image fusion under the inspiration of human cognitive laws and proposes a novel infrared and visible image fusion method, termed HCLFuse. First, HCLFuse investigates the quantification theory of information mapping in unsupervised fusion networks, which leads to the design of a multi-scale mask-regulated variational bottleneck encoder. This encoder applies posterior probability modeling and information decomposition to extract accurate and concise low-level modal information, thereby supporting the generation of high-fidelity structural details. Furthermore, the probabilistic generative capability of the diffusion model is integrated with physical laws, forming a time-varying physical guidance mechanism that adaptively regulates the generation process at different stages, thereby enhancing the ability of the model to perceive the intrinsic structure of data and reducing dependence on data quality. Experimental results show that the proposed method achieves state-of-the-art fusion performance in qualitative and quantitative evaluations across multiple datasets and significantly improves semantic segmentation metrics. This fully demonstrates the advantages of this generative image fusion method, drawing inspiration from human cognition, in enhancing structural consistency and detail quality.
Capture Artifacts via Progressive Disentangling and Purifying Blended Identities for Deepfake Detection
Oct 15, 2024

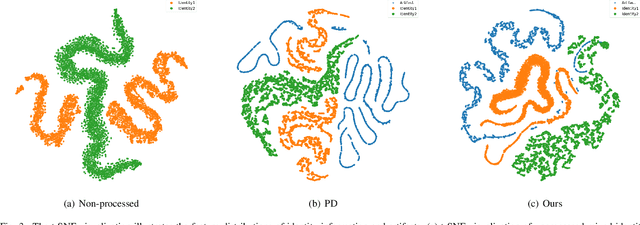

The Deepfake technology has raised serious concerns regarding privacy breaches and trust issues. To tackle these challenges, Deepfake detection technology has emerged. Current methods over-rely on the global feature space, which contains redundant information independent of the artifacts. As a result, existing Deepfake detection techniques suffer performance degradation when encountering unknown datasets. To reduce information redundancy, the current methods use disentanglement techniques to roughly separate the fake faces into artifacts and content information. However, these methods lack a solid disentanglement foundation and cannot guarantee the reliability of their disentangling process. To address these issues, a Deepfake detection method based on progressive disentangling and purifying blended identities is innovatively proposed in this paper. Based on the artifact generation mechanism, the coarse- and fine-grained strategies are combined to ensure the reliability of the disentanglement method. Our method aims to more accurately capture and separate artifact features in fake faces. Specifically, we first perform the coarse-grained disentangling on fake faces to obtain a pair of blended identities that require no additional annotation to distinguish between source face and target face. Then, the artifact features from each identity are separated to achieve fine-grained disentanglement. To obtain pure identity information and artifacts, an Identity-Artifact Correlation Compression module (IACC) is designed based on the information bottleneck theory, effectively reducing the potential correlation between identity information and artifacts. Additionally, an Identity-Artifact Separation Contrast Loss is designed to enhance the independence of artifact features post-disentangling. Finally, the classifier only focuses on pure artifact features to achieve a generalized Deepfake detector.
Infrared and visible image fusion based on Multi-State Contextual Hidden Markov Model
Jan 26, 2022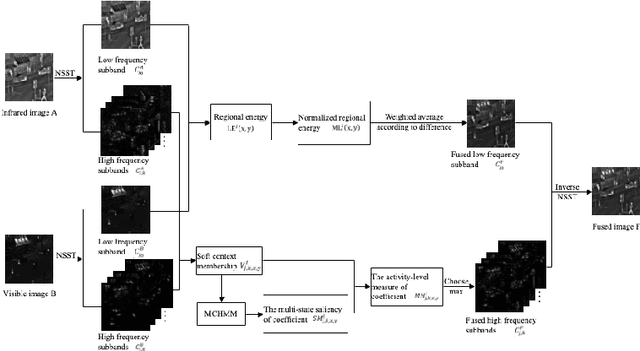
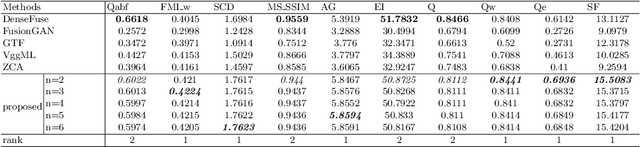
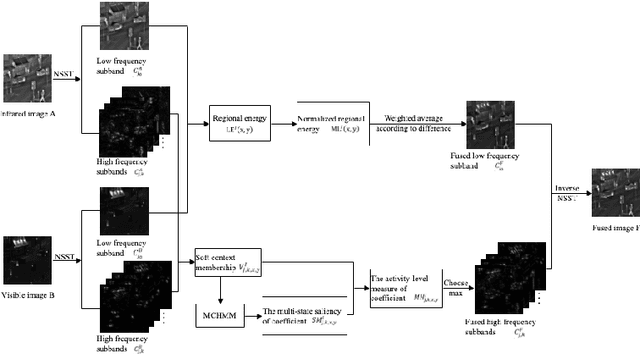
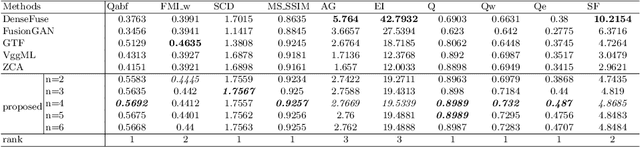
The traditional two-state hidden Markov model divides the high frequency coefficients only into two states (large and small states). Such scheme is prone to produce an inaccurate statistical model for the high frequency subband and reduces the quality of fusion result. In this paper, a fine-grained multi-state contextual hidden Markov model (MCHMM) is proposed for infrared and visible image fusion in the non-subsampled Shearlet domain, which takes full consideration of the strong correlations and level of details of NSST coefficients. To this end, an accurate soft context variable is designed correspondingly from the perspective of context correlation. Then, the statistical features provided by MCHMM are utilized for the fusion of high frequency subbands. To ensure the visual quality, a fusion strategy based on the difference in regional energy is proposed as well for lowfrequency subbands. Experimental results demonstrate that the proposed method can achieve a superior performance compared with other fusion methods in both subjective and objective aspects.
A Joint Convolution Auto-encoder Network for Infrared and Visible Image Fusion
Jan 26, 2022Background: Leaning redundant and complementary relationships is a critical step in the human visual system. Inspired by the infrared cognition ability of crotalinae animals, we design a joint convolution auto-encoder (JCAE) network for infrared and visible image fusion. Methods: Our key insight is to feed infrared and visible pair images into the network simultaneously and separate an encoder stream into two private branches and one common branch, the private branch works for complementary features learning and the common branch does for redundant features learning. We also build two fusion rules to integrate redundant and complementary features into their fused feature which are then fed into the decoder layer to produce the final fused image. We detail the structure, fusion rule and explain its multi-task loss function. Results: Our JCAE network achieves good results in terms of both subjective effect and objective evaluation metrics.