 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Backpropagation in Two Tower Recommendation Models
Mar 27, 2024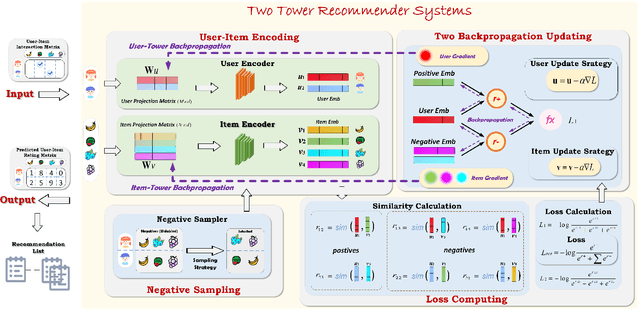
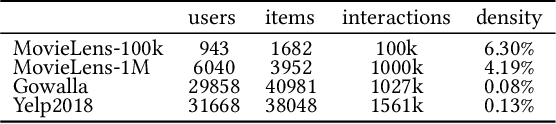
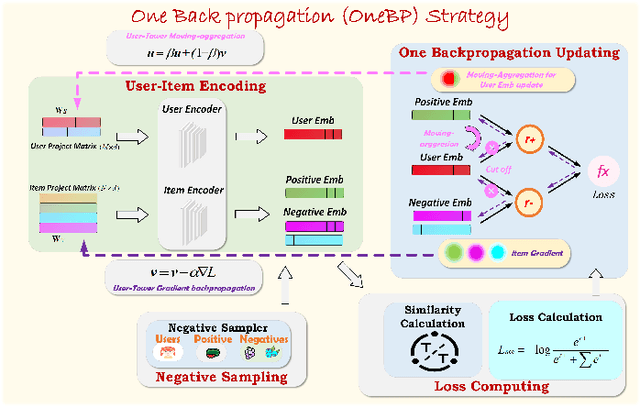
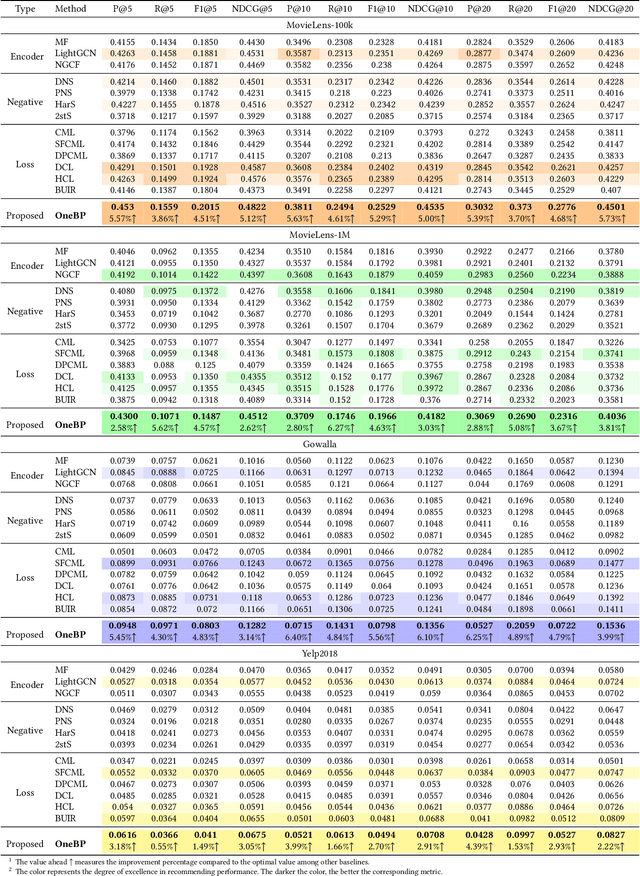
Recent years have witnessed extensive researches on developing two tower recommendation models for relieving information overload. Four building modules can be identified in such models, namely, user-item encoding, negative sampling, loss computing and back-propagation updating. To the best of our knowledge, existing algorithms have researched only on the first three modules, yet neglecting the backpropagation module. They all adopt a kind of two backpropagation strategy, which are based on an implicit assumption of equally treating users and items in the training phase. In this paper, we challenge such an equal training assumption and propose a novel one backpropagation updating strategy, which keeps the normal gradient backpropagation for the item encoding tower, but cuts off the backpropagation for the user encoding tower. Instead, we propose a moving-aggregation updating strategy to update a user encoding in each training epoch. Except the proposed backpropagation updating module, we implement the other three modules with the most straightforward choices. Experiments on four public datasets validate the effectiveness and efficiency of our model in terms of improved recommendation performance and reduced computation overload over the state-of-the-art competitors.
Reducing Popularity Bias in Recommender Systems through AUC-Optimal Negative Sampling
Jun 02, 2023



Popularity bias is a persistent issue associated with recommendation systems, posing challenges to both fairness and efficiency. Existing literature widely acknowledges that reducing popularity bias often requires sacrificing recommendation accuracy. In this paper, we challenge this commonly held belief. Our analysis under general bias-variance decomposition framework shows that reducing bias can actually lead to improved model performance under certain conditions. To achieve this win-win situation, we propose to intervene in model training through negative sampling thereby modifying model predictions. Specifically, we provide an optimal negative sampling rule that maximizes partial AUC to preserve the accuracy of any given model, while correcting sample information and prior information to reduce popularity bias in a flexible and principled way. Our experimental results on real-world datasets demonstrate the superiority of our approach in improving recommendation performance and reducing popularity bias.