 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconfuseTrack:Dealing with Confusion for Multi-Object Tracking
Mar 05, 2024Accurate data association is crucial in reducing confusion, such as ID switches and assignment errors, in multi-object tracking (MOT). However, existing advanced methods often overlook the diversity among trajectories and the ambiguity and conflicts present in motion and appearance cues, leading to confusion among detections, trajectories, and associations when performing simple global data association. To address this issue, we propose a simple, versatile, and highly interpretable data association approach called Decomposed Data Association (DDA). DDA decomposes the traditional association problem into multiple sub-problems using a series of non-learning-based modules and selectively addresses the confusion in each sub-problem by incorporating targeted exploitation of new cues. Additionally, we introduce Occlusion-aware Non-Maximum Suppression (ONMS) to retain more occluded detections, thereby increasing opportunities for association with trajectories and indirectly reducing the confusion caused by missed detections. Finally, based on DDA and ONMS, we design a powerful multi-object tracker named DeconfuseTrack, specifically focused on resolving confusion in MOT. Extensive experiments conducted on the MOT17 and MOT20 datasets demonstrate that our proposed DDA and ONMS significantly enhance the performance of several popular trackers. Moreover, DeconfuseTrack achieves state-of-the-art performance on the MOT17 and MOT20 test sets, significantly outperforms the baseline tracker ByteTrack in metrics such as HOTA, IDF1, AssA. This validates that our tracking design effectively reduces confusion caused by simple global association.
Focus On Details: Online Multi-object Tracking with Diverse Fine-grained Representation
Mar 08, 2023Discriminative representation is essential to keep a unique identifier for each target in Multiple object tracking (MOT). Some recent MOT methods extract features of the bounding box region or the center point as identity embeddings. However, when targets are occluded, these coarse-grained global representations become unreliable. To this end, we propose exploring diverse fine-grained representation, which describes appearance comprehensively from global and local perspectives. This fine-grained representation requires high feature resolution and precise semantic information. To effectively alleviate the semantic misalignment caused by indiscriminate contextual information aggregation, Flow Alignment FPN (FAFPN) is proposed for multi-scale feature alignment aggregation. It generates semantic flow among feature maps from different resolutions to transform their pixel positions. Furthermore, we present a Multi-head Part Mask Generator (MPMG) to extract fine-grained representation based on the aligned feature maps. Multiple parallel branches of MPMG allow it to focus on different parts of targets to generate local masks without label supervision. The diverse details in target masks facilitate fine-grained representation. Eventually, benefiting from a Shuffle-Group Sampling (SGS) training strategy with positive and negative samples balanced, we achieve state-of-the-art performance on MOT17 and MOT20 test sets. Even on DanceTrack, where the appearance of targets is extremely similar, our method significantly outperforms ByteTrack by 5.0% on HOTA and 5.6% on IDF1. Extensive experiments have proved that diverse fine-grained representation makes Re-ID great again in MOT.
Generalizing Multiple Object Tracking to Unseen Domains by Introducing Natural Language Representation
Dec 03, 2022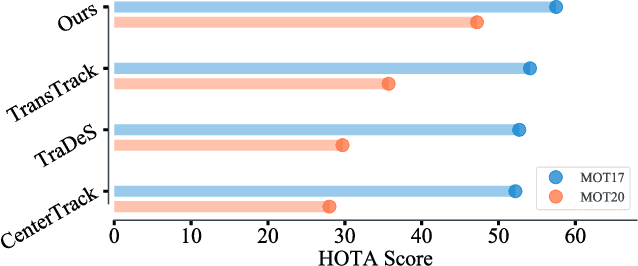
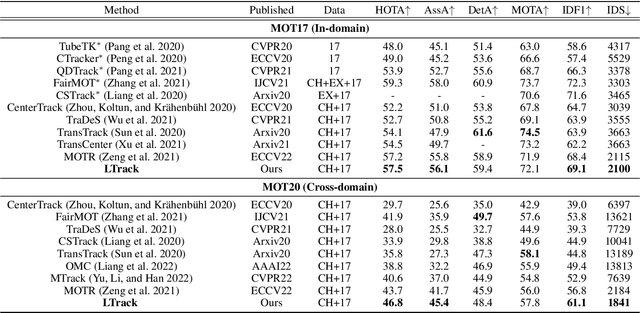
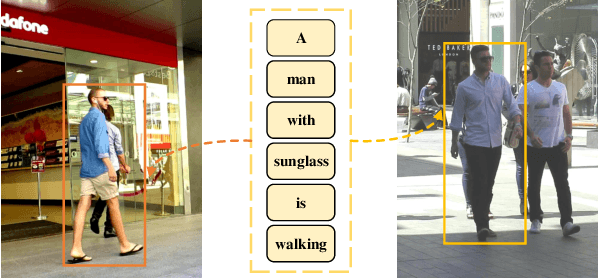
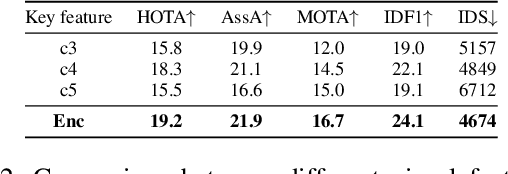
Although existing multi-object tracking (MOT) algorithms have obtained competitive performance on various benchmarks, almost all of them train and validate models on the same domain. The domain generalization problem of MOT is hardly studied. To bridge this gap, we first draw the observation that the high-level information contained in natural language is domain invariant to different tracking domains. Based on this observation, we propose to introduce natural language representation into visual MOT models for boosting the domain generalization ability. However, it is infeasible to label every tracking target with a textual description. To tackle this problem, we design two modules, namely visual context prompting (VCP) and visual-language mixing (VLM). Specifically, VCP generates visual prompts based on the input frames. VLM joints the information in the generated visual prompts and the textual prompts from a pre-defined Trackbook to obtain instance-level pseudo textual description, which is domain invariant to different tracking scenes. Through training models on MOT17 and validating them on MOT20, we observe that the pseudo textual descriptions generated by our proposed modules improve the generalization performance of query-based trackers by large margins.
Towards Discriminative Representation: Multi-view Trajectory Contrastive Learning for Online Multi-object Tracking
Apr 05, 2022



Discriminative representation is crucial for the association step in multi-object tracking. Recent work mainly utilizes features in single or neighboring frames for constructing metric loss and empowering networks to extract representation of targets. Although this strategy is effective, it fails to fully exploit the information contained in a whole trajectory. To this end, we propose a strategy, namely multi-view trajectory contrastive learning, in which each trajectory is represented as a center vector. By maintaining all the vectors in a dynamically updated memory bank, a trajectory-level contrastive loss is devised to explore the inter-frame information in the whole trajectories. Besides, in this strategy, each target is represented as multiple adaptively selected keypoints rather than a pre-defined anchor or center. This design allows the network to generate richer representation from multiple views of the same target, which can better characterize occluded objects. Additionally, in the inference stage, a similarity-guided feature fusion strategy is developed for further boosting the quality of the trajectory representation. Extensive experiments have been conducted on MOTChallenge to verify the effectiveness of the proposed techniques. The experimental results indicate that our method has surpassed preceding trackers and established new state-of-the-art performance.
Towards Efficiently Evaluating the Robustness of Deep Neural Networks in IoT Systems: A GAN-based Method
Nov 19, 2021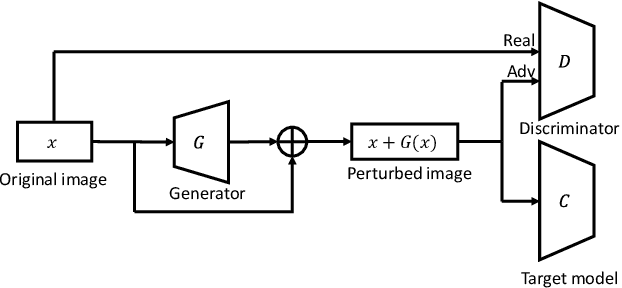
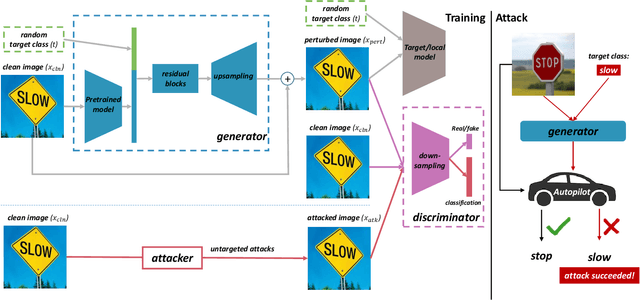

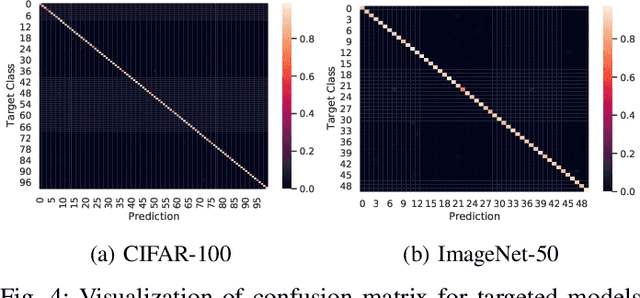
Intelligent Internet of Things (IoT) systems based on deep neural networks (DNNs) have been widely deployed in the real world. However, DNNs are found to be vulnerable to adversarial examples, which raises people's concerns about intelligent IoT systems' reliability and security. Testing and evaluating the robustness of IoT systems becomes necessary and essential. Recently various attacks and strategies have been proposed, but the efficiency problem remains unsolved properly. Existing methods are either computationally extensive or time-consuming, which is not applicable in practice. In this paper, we propose a novel framework called Attack-Inspired GAN (AI-GAN) to generate adversarial examples conditionally. Once trained, it can generate adversarial perturbations efficiently given input images and target classes. We apply AI-GAN on different datasets in white-box settings, black-box settings and targeted models protected by state-of-the-art defenses. Through extensive experiments, AI-GAN achieves high attack success rates, outperforming existing methods, and reduces generation time significantly. Moreover, for the first time, AI-GAN successfully scales to complex datasets e.g. CIFAR-100 and ImageNet, with about $90\%$ success rates among all classes.
RelationTrack: Relation-aware Multiple Object Tracking with Decoupled Representation
May 10, 2021



Existing online multiple object tracking (MOT) algorithms often consist of two subtasks, detection and re-identification (ReID). In order to enhance the inference speed and reduce the complexity, current methods commonly integrate these double subtasks into a unified framework. Nevertheless, detection and ReID demand diverse features. This issue would result in an optimization contradiction during the training procedure. With the target of alleviating this contradiction, we devise a module named Global Context Disentangling (GCD) that decouples the learned representation into detection-specific and ReID-specific embeddings. As such, this module provides an implicit manner to balance the different requirements of these two subtasks. Moreover, we observe that preceding MOT methods typically leverage local information to associate the detected targets and neglect to consider the global semantic relation. To resolve this restriction, we develop a module, referred to as Guided Transformer Encoder (GTE), by combining the powerful reasoning ability of Transformer encoder and deformable attention. Unlike previous works, GTE avoids analyzing all the pixels and only attends to capture the relation between query nodes and a few self-adaptively selected key samples. Therefore, it is computationally efficient. Extensive experiments have been conducted on the MOT16, MOT17 and MOT20 benchmarks to demonstrate the superiority of the proposed MOT framework, namely RelationTrack. The experimental results indicate that RelationTrack has surpassed preceding methods significantly and established a new state-of-the-art performance, e.g., IDF1 of 70.5% and MOTA of 67.2% on MOT20.
ANL: Anti-Noise Learning for Cross-Domain Person Re-Identification
Dec 27, 2020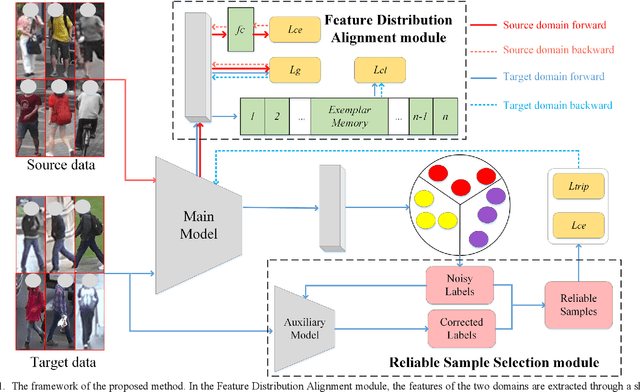
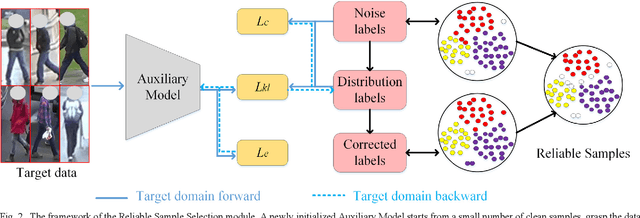
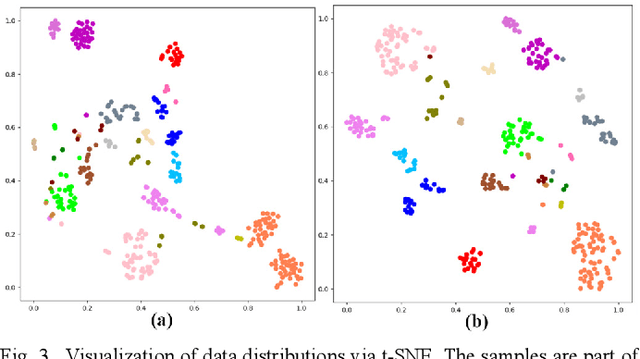
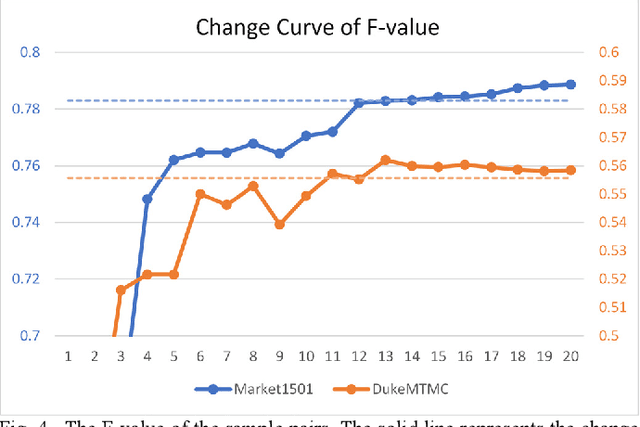
Due to the lack of labels and the domain diversities, it is a challenge to study person re-identification in the cross-domain setting. An admirable method is to optimize the target model by assigning pseudo-labels for unlabeled samples through clustering. Usually, attributed to the domain gaps, the pre-trained source domain model cannot extract appropriate target domain features, which will dramatically affect the clustering performance and the accuracy of pseudo-labels. Extensive label noise will lead to sub-optimal solutions doubtlessly. To solve these problems, we propose an Anti-Noise Learning (ANL) approach, which contains two modules. The Feature Distribution Alignment (FDA) module is designed to gather the id-related samples and disperse id-unrelated samples, through the camera-wise contrastive learning and adversarial adaptation. Creating a friendly cross-feature foundation for clustering that is to reduce clustering noise. Besides, the Reliable Sample Selection (RSS) module utilizes an Auxiliary Model to correct noisy labels and select reliable samples for the Main Model. In order to effectively utilize the outlier information generated by the clustering algorithm and RSS module, we train these samples at the instance-level. The experiments demonstrate that our proposed ANL framework can effectively reduce the domain conflicts and alleviate the influence of noisy samples, as well as superior performance compared with the state-of-the-art methods.
FTN: Foreground-Guided Texture-Focused Person Re-Identification
Sep 24, 2020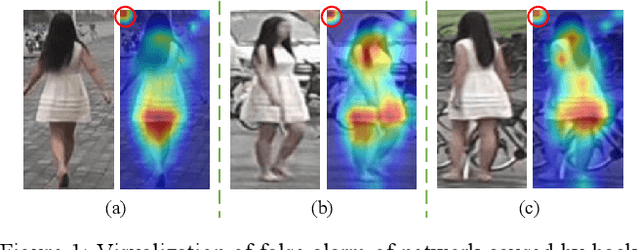
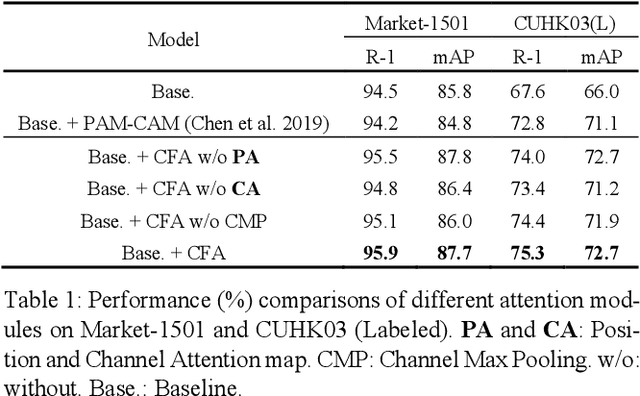
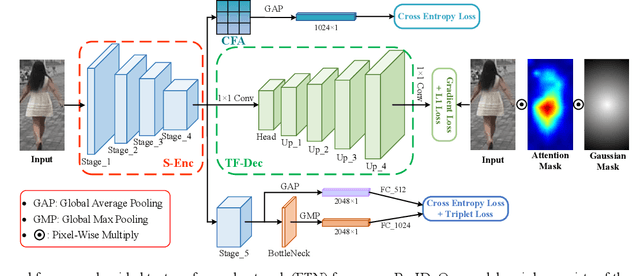
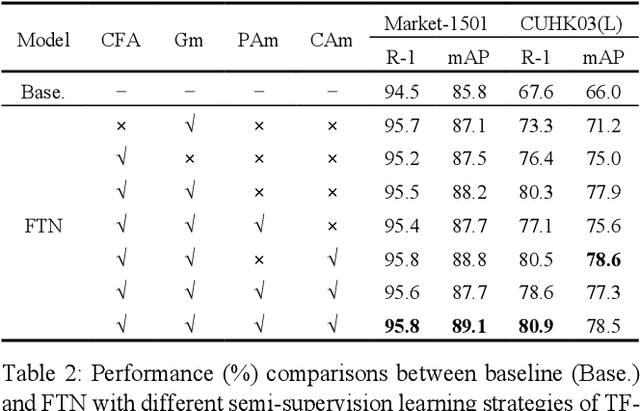
Person re-identification (Re-ID) is a challenging task as persons are often in different backgrounds. Most recent Re-ID methods treat the foreground and background information equally for person discriminative learning, but can easily lead to potential false alarm problems when different persons are in similar backgrounds or the same person is in different backgrounds. In this paper, we propose a Foreground-Guided Texture-Focused Network (FTN) for Re-ID, which can weaken the representation of unrelated background and highlight the attributes person-related in an end-to-end manner. FTN consists of a semantic encoder (S-Enc) and a compact foreground attention module (CFA) for Re-ID task, and a texture-focused decoder (TF-Dec) for reconstruction task. Particularly, we build a foreground-guided semi-supervised learning strategy for TF-Dec because the reconstructed ground-truths are only the inputs of FTN weighted by the Gaussian mask and the attention mask generated by CFA. Moreover, a new gradient loss is introduced to encourage the network to mine the texture consistency between the inputs and the reconstructed outputs. Our FTN is computationally efficient and extensive experiments on three commonly used datasets Market1501, CUHK03 and MSMT17 demonstrate that the proposed method performs favorably against the state-of-the-art methods.
MAT: Motion-Aware Multi-Object Tracking
Sep 18, 2020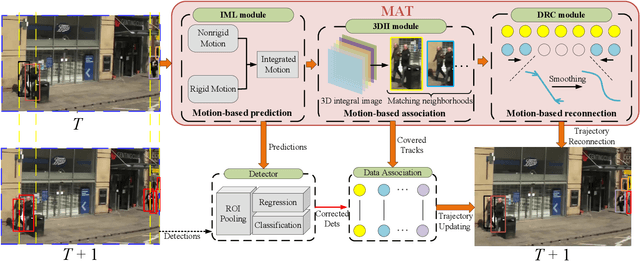
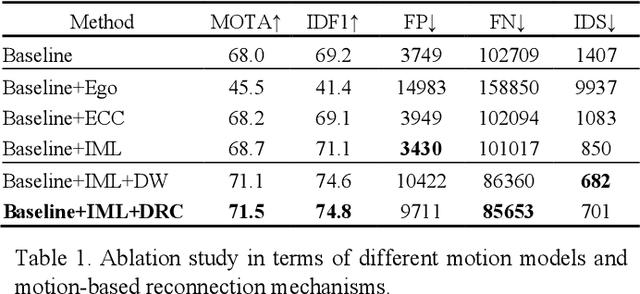
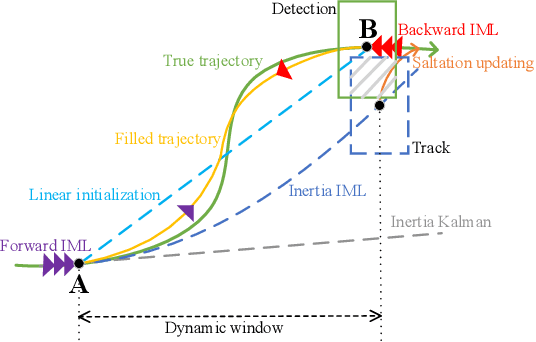
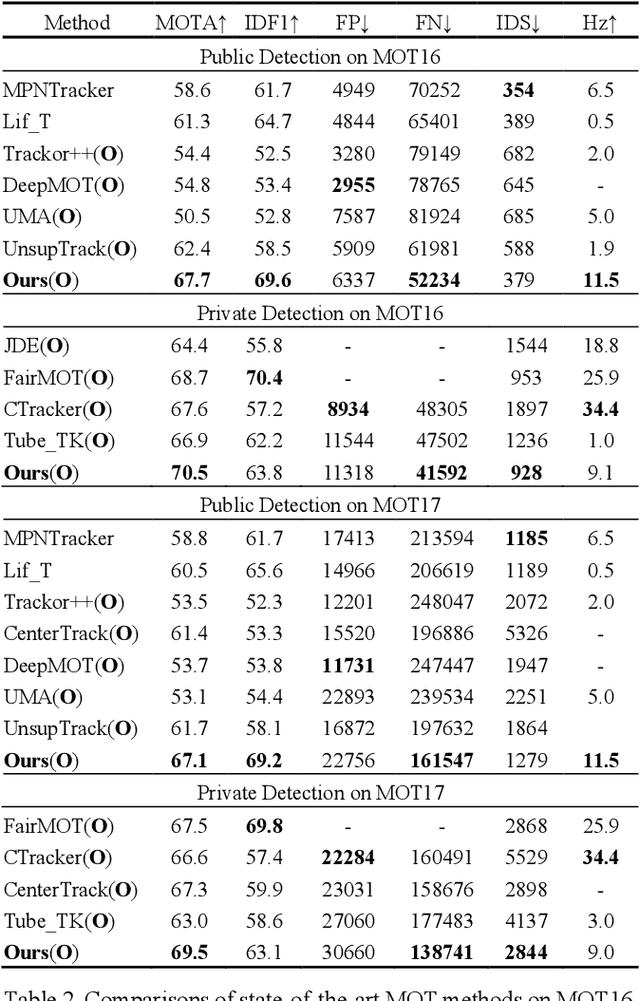
Modern multi-object tracking (MOT) systems usually model the trajectories by associating per-frame detections. However, when camera motion, fast motion, and occlusion challenges occur, it is difficult to ensure long-range tracking or even the tracklet purity, especially for small objects. Although re-identification is often employed, due to noisy partial-detections, similar appearance, and lack of temporal-spatial constraints, it is not only unreliable and time-consuming, but still cannot address the false negatives for occluded and blurred objects. In this paper, we propose an enhanced MOT paradigm, namely Motion-Aware Tracker (MAT), focusing more on various motion patterns of different objects. The rigid camera motion and nonrigid pedestrian motion are blended compatibly to form the integrated motion localization module. Meanwhile, we introduce the dynamic reconnection context module, which aims to balance the robustness of long-range motion-based reconnection, and includes the cyclic pseudo-observation updating strategy to smoothly fill in the tracking fragments caused by occlusion or blur. Additionally, the 3D integral image module is presented to efficiently cut useless track-detection association connections with temporal-spatial constraints. Extensive experiments on MOT16 and MOT17 challenging benchmarks demonstrate that our MAT approach can achieve the superior performance by a large margin with high efficiency, in contrast to other state-of-the-art trackers.
Refinements in Motion and Appearance for Online Multi-Object Tracking
Mar 17, 2020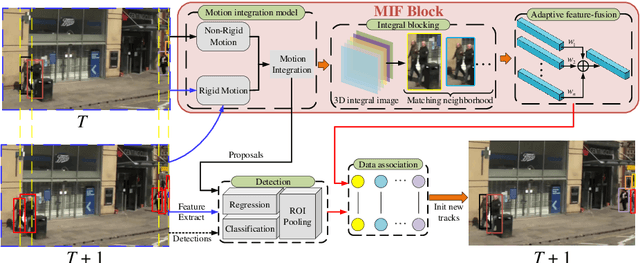
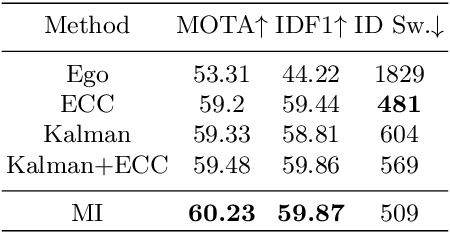
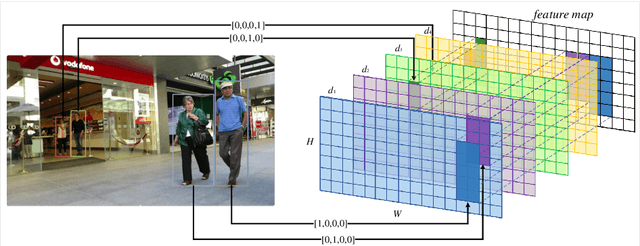
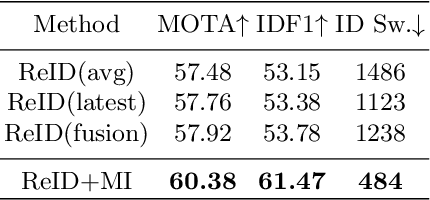
Modern multi-object tracking (MOT) system usually involves separated modules, such as motion model for location and appearance model for data association. However, the compatible problems within both motion and appearance models are always ignored. In this paper, a general architecture named as MIF is presented by seamlessly blending the Motion integration, three-dimensional(3D) Integral image and adaptive appearance feature Fusion. Since the uncertain pedestrian and camera motions are usually handled separately, the integrated motion model is designed using our defined intension of camera motion. Specifically, a 3D integral image based spatial blocking method is presented to efficiently cut useless connections between trajectories and candidates with spatial constraints. Then the appearance model and visibility prediction are jointly built. Considering scale, pose and visibility, the appearance features are adaptively fused to overcome the feature misalignment problem. Our MIF based tracker (MIFT) achieves the state-of-the-art accuracy with 60.1 MOTA on both MOT16&17 challenges.