 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTN: Foreground-Guided Texture-Focused Person Re-Identification
Sep 24, 2020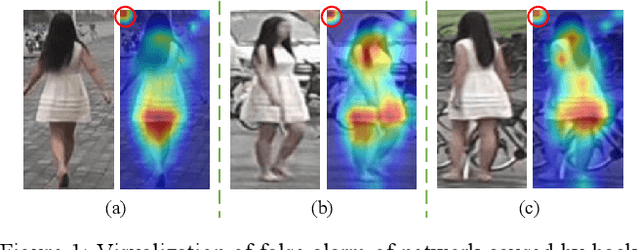
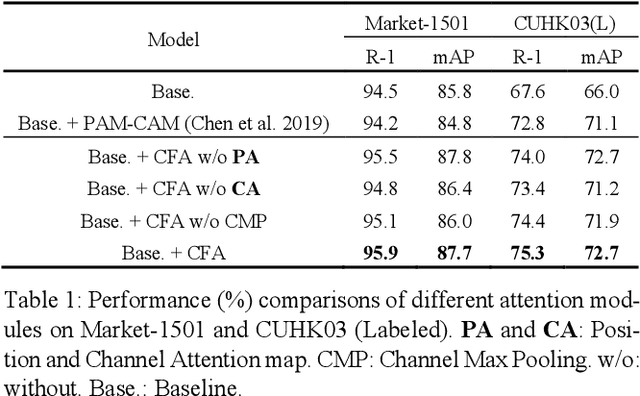
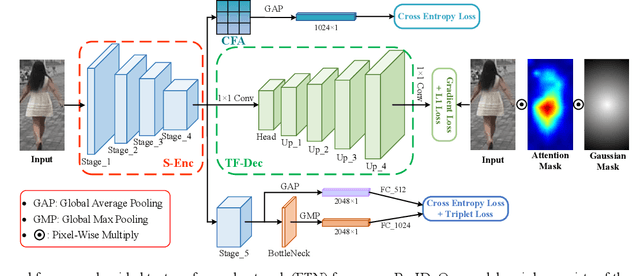
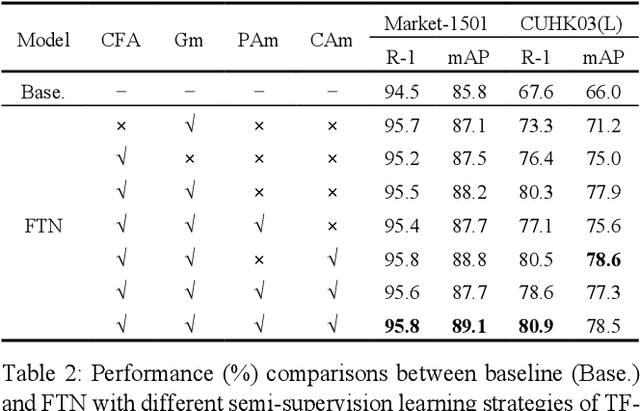
Person re-identification (Re-ID) is a challenging task as persons are often in different backgrounds. Most recent Re-ID methods treat the foreground and background information equally for person discriminative learning, but can easily lead to potential false alarm problems when different persons are in similar backgrounds or the same person is in different backgrounds. In this paper, we propose a Foreground-Guided Texture-Focused Network (FTN) for Re-ID, which can weaken the representation of unrelated background and highlight the attributes person-related in an end-to-end manner. FTN consists of a semantic encoder (S-Enc) and a compact foreground attention module (CFA) for Re-ID task, and a texture-focused decoder (TF-Dec) for reconstruction task. Particularly, we build a foreground-guided semi-supervised learning strategy for TF-Dec because the reconstructed ground-truths are only the inputs of FTN weighted by the Gaussian mask and the attention mask generated by CFA. Moreover, a new gradient loss is introduced to encourage the network to mine the texture consistency between the inputs and the reconstructed outputs. Our FTN is computationally efficient and extensive experiments on three commonly used datasets Market1501, CUHK03 and MSMT17 demonstrate that the proposed method performs favorably against the state-of-the-art methods.
MAT: Motion-Aware Multi-Object Tracking
Sep 18, 2020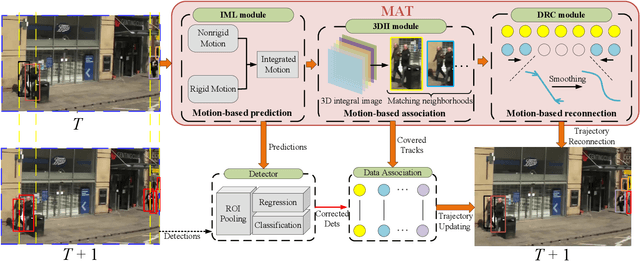
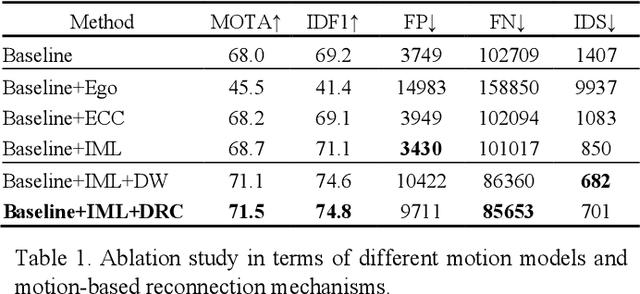
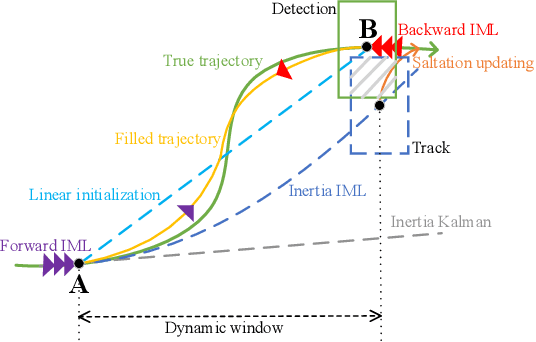
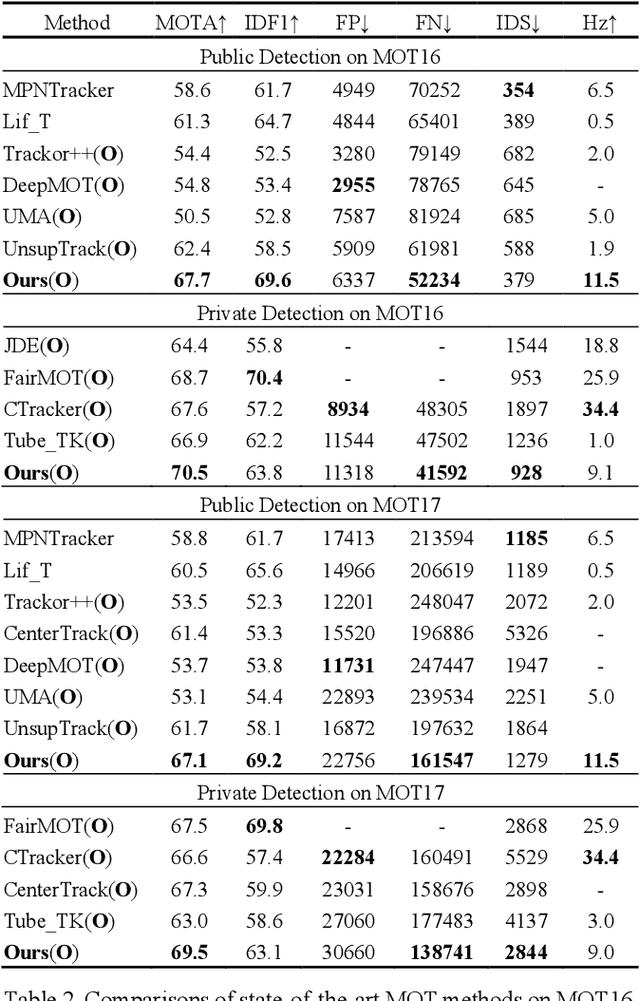
Modern multi-object tracking (MOT) systems usually model the trajectories by associating per-frame detections. However, when camera motion, fast motion, and occlusion challenges occur, it is difficult to ensure long-range tracking or even the tracklet purity, especially for small objects. Although re-identification is often employed, due to noisy partial-detections, similar appearance, and lack of temporal-spatial constraints, it is not only unreliable and time-consuming, but still cannot address the false negatives for occluded and blurred objects. In this paper, we propose an enhanced MOT paradigm, namely Motion-Aware Tracker (MAT), focusing more on various motion patterns of different objects. The rigid camera motion and nonrigid pedestrian motion are blended compatibly to form the integrated motion localization module. Meanwhile, we introduce the dynamic reconnection context module, which aims to balance the robustness of long-range motion-based reconnection, and includes the cyclic pseudo-observation updating strategy to smoothly fill in the tracking fragments caused by occlusion or blur. Additionally, the 3D integral image module is presented to efficiently cut useless track-detection association connections with temporal-spatial constraints. Extensive experiments on MOT16 and MOT17 challenging benchmarks demonstrate that our MAT approach can achieve the superior performance by a large margin with high efficiency, in contrast to other state-of-the-art trackers.
Refinements in Motion and Appearance for Online Multi-Object Tracking
Mar 17, 2020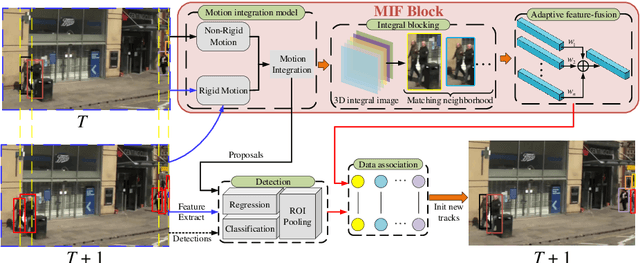
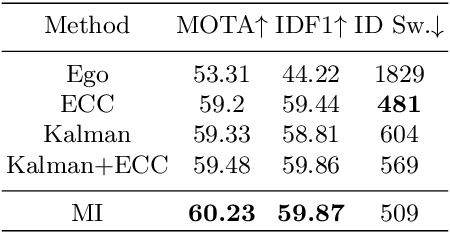
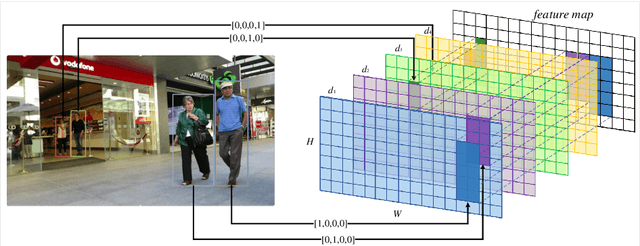
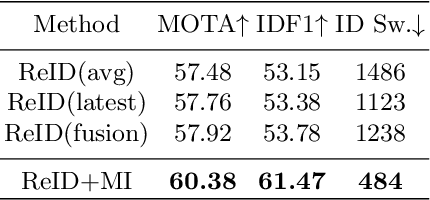
Modern multi-object tracking (MOT) system usually involves separated modules, such as motion model for location and appearance model for data association. However, the compatible problems within both motion and appearance models are always ignored. In this paper, a general architecture named as MIF is presented by seamlessly blending the Motion integration, three-dimensional(3D) Integral image and adaptive appearance feature Fusion. Since the uncertain pedestrian and camera motions are usually handled separately, the integrated motion model is designed using our defined intension of camera motion. Specifically, a 3D integral image based spatial blocking method is presented to efficiently cut useless connections between trajectories and candidates with spatial constraints. Then the appearance model and visibility prediction are jointly built. Considering scale, pose and visibility, the appearance features are adaptively fused to overcome the feature misalignment problem. Our MIF based tracker (MIFT) achieves the state-of-the-art accuracy with 60.1 MOTA on both MOT16&17 challenges.