 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndirect-Instant Attention Optimization for Crowd Counting in Dense Scenes
Paper and Code
Jun 12, 2022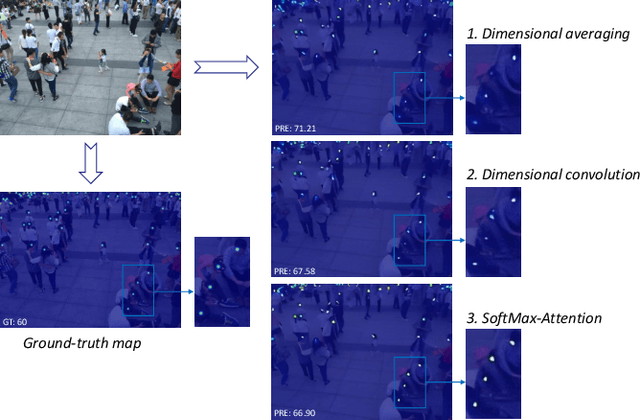

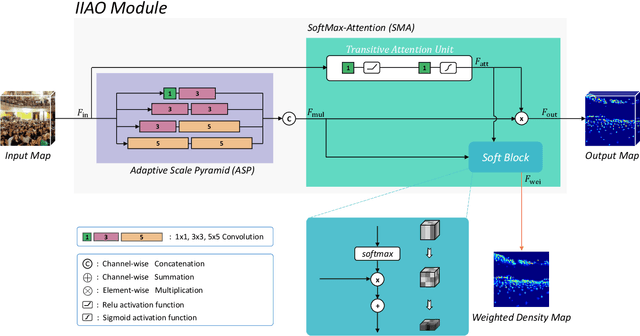

One of appealing approaches to guiding learnable parameter optimization, such as feature maps, is global attention, which enlightens network intelligence at a fraction of the cost. However, its loss calculation process still falls short: 1)We can only produce one-dimensional 'pseudo labels' for attention, since the artificial threshold involved in the procedure is not robust; 2) The attention awaiting loss calculation is necessarily high-dimensional, and decreasing it by convolution will inevitably introduce additional learnable parameters, thus confusing the source of the loss. To this end, we devise a simple but efficient Indirect-Instant Attention Optimization (IIAO) module based on SoftMax-Attention , which transforms high-dimensional attention map into a one-dimensional feature map in the mathematical sense for loss calculation midway through the network, while automatically providing adaptive multi-scale fusion to feature pyramid module. The special transformation yields relatively coarse features and, originally, the predictive fallibility of regions varies by crowd density distribution, so we tailor the Regional Correlation Loss (RCLoss) to retrieve continuous error-prone regions and smooth spatial information . Extensive experiments have proven that our approach surpasses previous SOTA methods in many benchmark datasets.