 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Experiments Meet Large Language Model Based Agents: A Survey and Perspective
Feb 01, 2024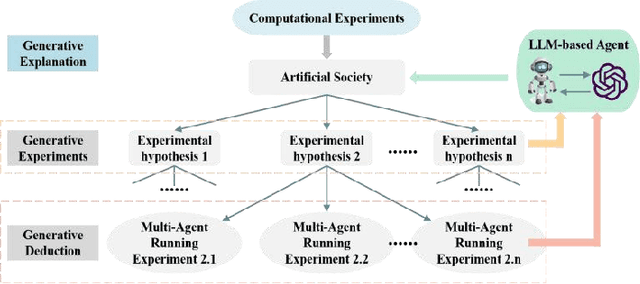
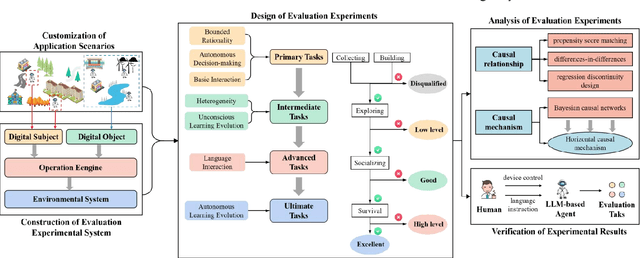
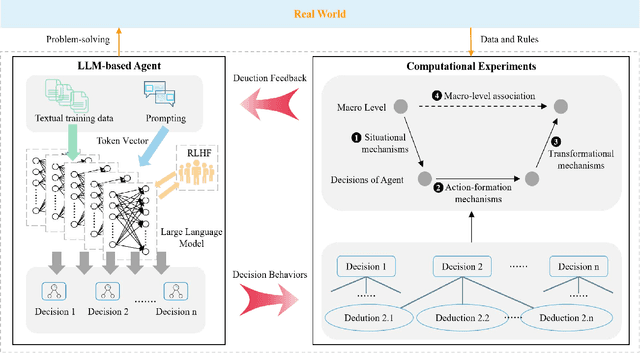
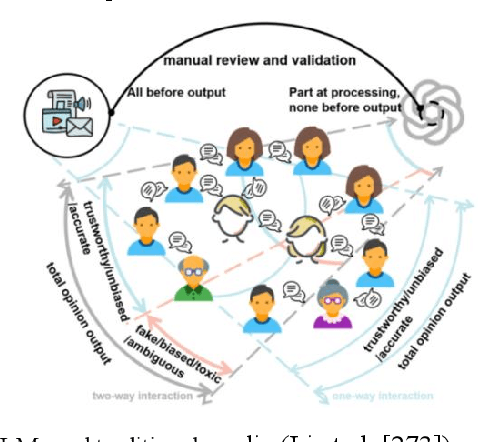
Computational experiments have emerged as a valuable method for studying complex systems, involving the algorithmization of counterfactuals. However, accurately representing real social systems in Agent-based Modeling (ABM) is challenging due to the diverse and intricate characteristics of humans, including bounded rationality and heterogeneity. To address this limitation, the integration of Large Language Models (LLMs) has been proposed, enabling agents to possess anthropomorphic abilities such as complex reasoning and autonomous learning. These agents, known as LLM-based Agent, offer the potential to enhance the anthropomorphism lacking in ABM. Nonetheless, the absence of explicit explainability in LLMs significantly hinders their application in the social sciences. Conversely, computational experiments excel in providing causal analysis of individual behaviors and complex phenomena. Thus, combining computational experiments with LLM-based Agent holds substantial research potential. This paper aims to present a comprehensive exploration of this fusion. Primarily, it outlines the historical development of agent structures and their evolution into artificial societies, emphasizing their importance in computational experiments. Then it elucidates the advantages that computational experiments and LLM-based Agents offer each other, considering the perspectives of LLM-based Agent for computational experiments and vice versa. Finally, this paper addresses the challenges and future trends in this research domain, offering guidance for subsequent related studies.
Indirect-Instant Attention Optimization for Crowd Counting in Dense Scenes
Jun 12, 2022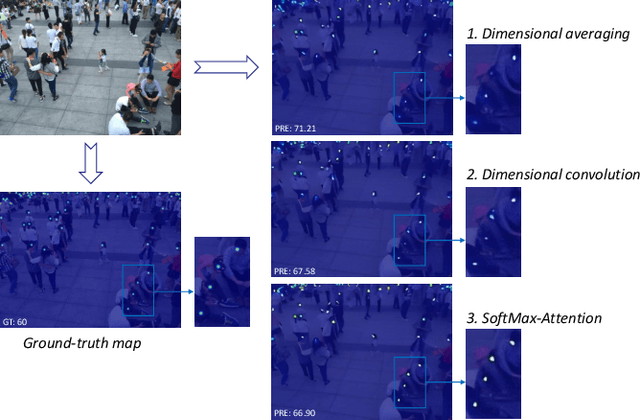

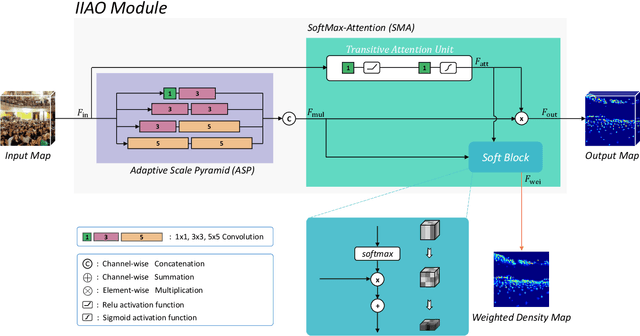

One of appealing approaches to guiding learnable parameter optimization, such as feature maps, is global attention, which enlightens network intelligence at a fraction of the cost. However, its loss calculation process still falls short: 1)We can only produce one-dimensional 'pseudo labels' for attention, since the artificial threshold involved in the procedure is not robust; 2) The attention awaiting loss calculation is necessarily high-dimensional, and decreasing it by convolution will inevitably introduce additional learnable parameters, thus confusing the source of the loss. To this end, we devise a simple but efficient Indirect-Instant Attention Optimization (IIAO) module based on SoftMax-Attention , which transforms high-dimensional attention map into a one-dimensional feature map in the mathematical sense for loss calculation midway through the network, while automatically providing adaptive multi-scale fusion to feature pyramid module. The special transformation yields relatively coarse features and, originally, the predictive fallibility of regions varies by crowd density distribution, so we tailor the Regional Correlation Loss (RCLoss) to retrieve continuous error-prone regions and smooth spatial information . Extensive experiments have proven that our approach surpasses previous SOTA methods in many benchmark datasets.