 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-Fading Channel and Power Optimization of the Magnetic Inductive Cellular Network
Jun 07, 2024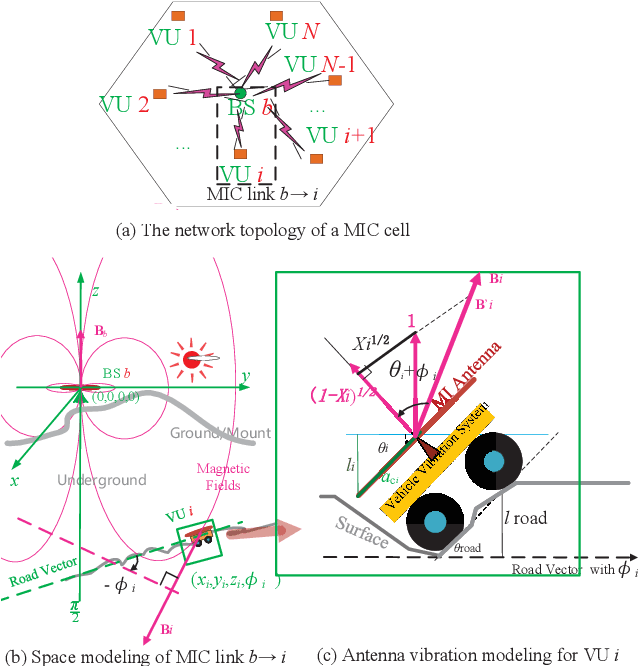
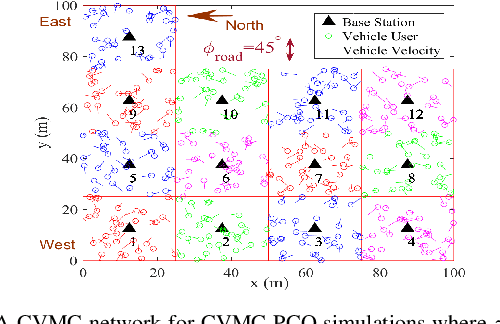
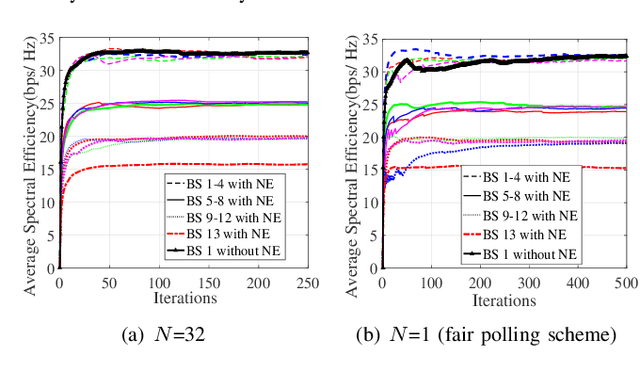
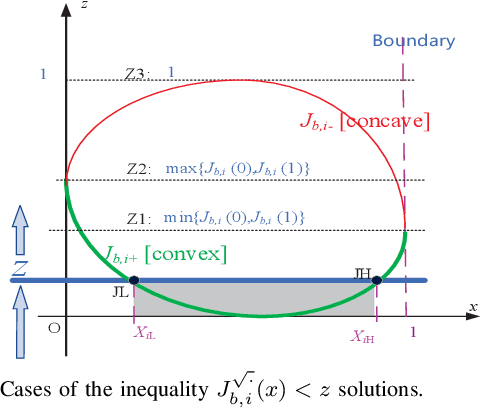
The cellular network of magnetic Induction (MI) communication holds promise in long-distance underground environments. In the traditional MI communication, there is no fast-fading channel since the MI channel is treated as a quasi-static channel. However, for the vehicle (mobile) MI (VMI) communication, the unpredictable antenna vibration brings the remarkable fast-fading. As such fast-fading cannot be modeled by the central limit theorem, it differs radically from other wireless fast-fading channels. Unfortunately, few studies focus on this phenomenon. In this paper, using a novel space modeling based on the electromagnetic field theorem, we propose a 3-dimension model of the VMI antenna vibration. By proposing ``conjugate pseudo-piecewise functions'' and boundary $p(x)$ distribution, we derive the cumulative distribution function (CDF), probability density function (PDF) and the expectation of the VMI fast-fading channel. We also theoretically analyze the effects of the VMI fast-fading on the network throughput, including the VMI outage probability which can be ignored in the traditional MI channel study. We draw several intriguing conclusions different from those in wireless fast-fading studies. For instance, the fast-fading brings more uniformly distributed channel coefficients. Finally, we propose the power control algorithm using the non-cooperative game and multiagent Q-learning methods to optimize the throughput of the cellular VMI network. Simulations validate the derivation and the proposed algorithm.
Unilaterally Aggregated Contrastive Learning with Hierarchical Augmentation for Anomaly Detection
Aug 20, 2023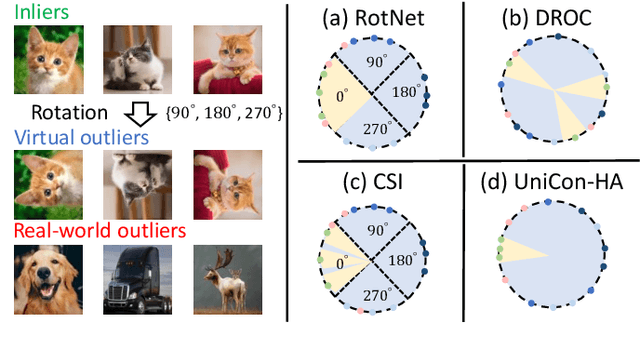



Anomaly detection (AD), aiming to find samples that deviate from the training distribution, is essential in safety-critical applications. Though recent self-supervised learning based attempts achieve promising results by creating virtual outliers, their training objectives are less faithful to AD which requires a concentrated inlier distribution as well as a dispersive outlier distribution. In this paper, we propose Unilaterally Aggregated Contrastive Learning with Hierarchical Augmentation (UniCon-HA), taking into account both the requirements above. Specifically, we explicitly encourage the concentration of inliers and the dispersion of virtual outliers via supervised and unsupervised contrastive losses, respectively. Considering that standard contrastive data augmentation for generating positive views may induce outliers, we additionally introduce a soft mechanism to re-weight each augmented inlier according to its deviation from the inlier distribution, to ensure a purified concentration. Moreover, to prompt a higher concentration, inspired by curriculum learning, we adopt an easy-to-hard hierarchical augmentation strategy and perform contrastive aggregation at different depths of the network based on the strengths of data augmentation. Our method is evaluated under three AD settings including unlabeled one-class, unlabeled multi-class, and labeled multi-class, demonstrating its consistent superiority over other competitors.
Video Anomaly Detection by Solving Decoupled Spatio-Temporal Jigsaw Puzzles
Jul 22, 2022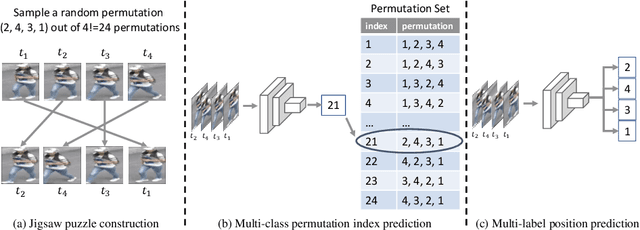
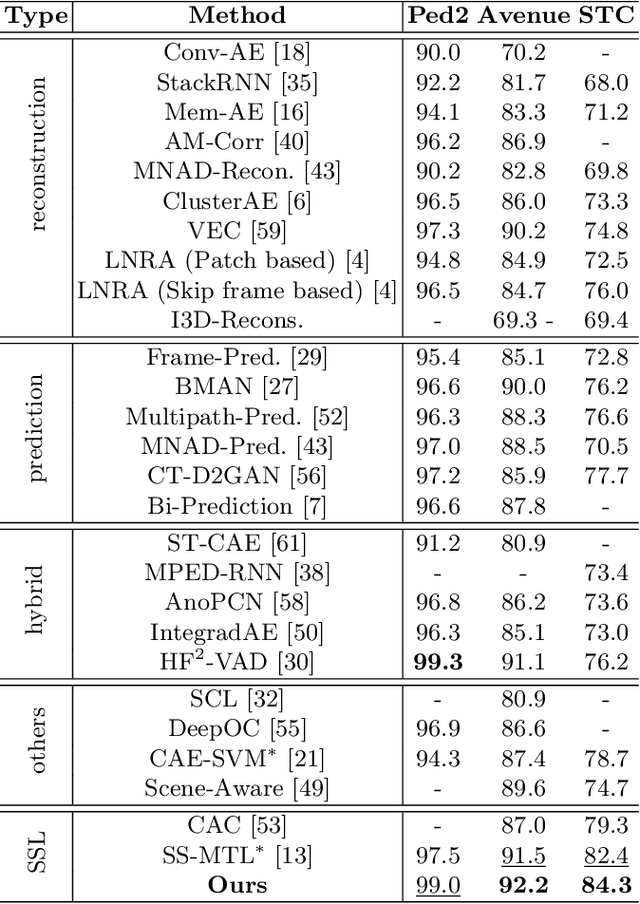
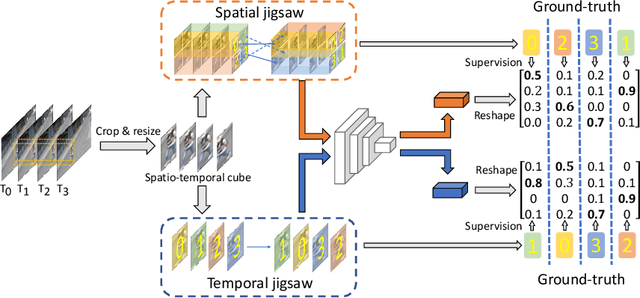
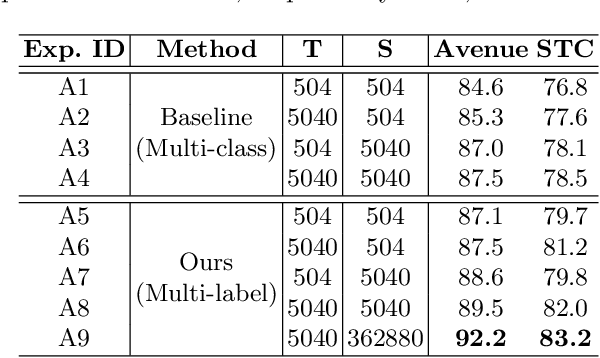
Video Anomaly Detection (VAD) is an important topic in computer vision. Motivated by the recent advances in self-supervised learning, this paper addresses VAD by solving an intuitive yet challenging pretext task, i.e., spatio-temporal jigsaw puzzles, which is cast as a multi-label fine-grained classification problem. Our method exhibits several advantages over existing works: 1) the spatio-temporal jigsaw puzzles are decoupled in terms of spatial and temporal dimensions, responsible for capturing highly discriminative appearance and motion features, respectively; 2) full permutations are used to provide abundant jigsaw puzzles covering various difficulty levels, allowing the network to distinguish subtle spatio-temporal differences between normal and abnormal events; and 3) the pretext task is tackled in an end-to-end manner without relying on any pre-trained models. Our method outperforms state-of-the-art counterparts on three public benchmarks. Especially on ShanghaiTech Campus, the result is superior to reconstruction and prediction-based methods by a large margin.
Representation Learning for Compressed Video Action Recognition via Attentive Cross-modal Interaction with Motion Enhancement
May 10, 2022
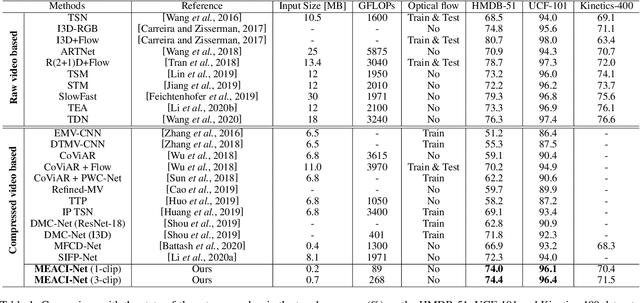

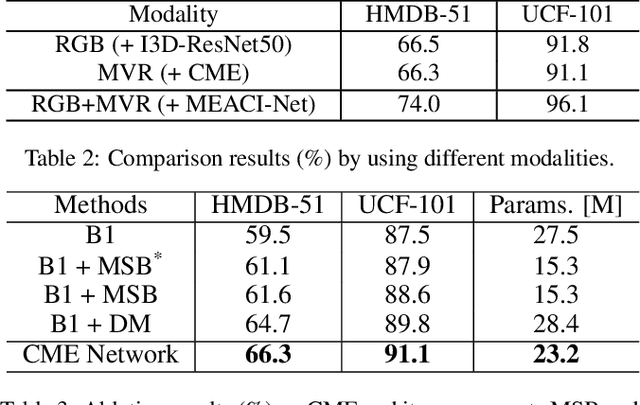
Compressed video action recognition has recently drawn growing attention, since it remarkably reduces the storage and computational cost via replacing raw videos by sparsely sampled RGB frames and compressed motion cues (e.g., motion vectors and residuals). However, this task severely suffers from the coarse and noisy dynamics and the insufficient fusion of the heterogeneous RGB and motion modalities. To address the two issues above, this paper proposes a novel framework, namely Attentive Cross-modal Interaction Network with Motion Enhancement (MEACI-Net). It follows the two-stream architecture, i.e. one for the RGB modality and the other for the motion modality. Particularly, the motion stream employs a multi-scale block embedded with a denoising module to enhance representation learning. The interaction between the two streams is then strengthened by introducing the Selective Motion Complement (SMC) and Cross-Modality Augment (CMA) modules, where SMC complements the RGB modality with spatio-temporally attentive local motion features and CMA further combines the two modalities with selective feature augmentation. Extensive experiments on the UCF-101, HMDB-51 and Kinetics-400 benchmarks demonstrate the effectiveness and efficiency of MEACI-Net.
DR2-Net: Deep Residual Reconstruction Network for Image Compressive Sensing
Nov 16, 2017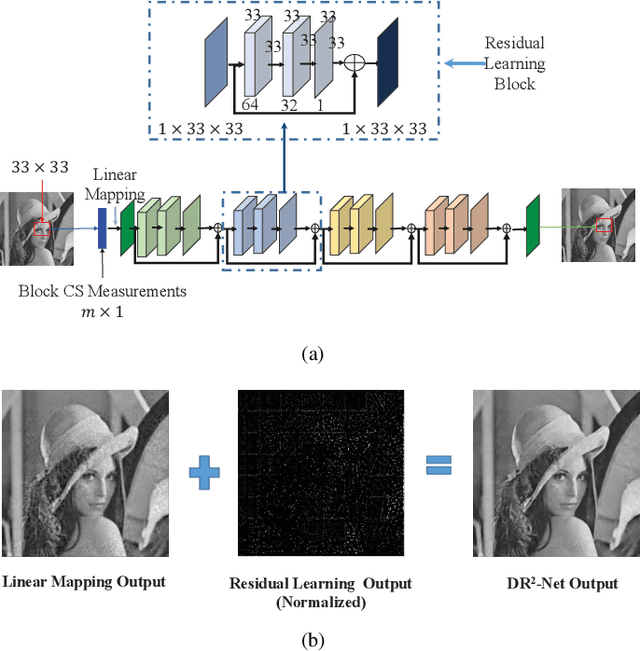

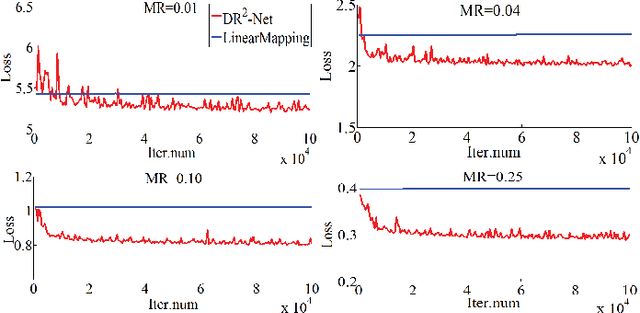

Most traditional algorithms for compressive sensing image reconstruction suffer from the intensive computation. Recently, deep learning-based reconstruction algorithms have been reported, which dramatically reduce the time complexity than iterative reconstruction algorithms. In this paper, we propose a novel \textbf{D}eep \textbf{R}esidual \textbf{R}econstruction Network (DR$^{2}$-Net) to reconstruct the image from its Compressively Sensed (CS) measurement. The DR$^{2}$-Net is proposed based on two observations: 1) linear mapping could reconstruct a high-quality preliminary image, and 2) residual learning could further improve the reconstruction quality. Accordingly, DR$^{2}$-Net consists of two components, \emph{i.e.,} linear mapping network and residual network, respectively. Specifically, the fully-connected layer in neural network implements the linear mapping network. We then expand the linear mapping network to DR$^{2}$-Net by adding several residual learning blocks to enhance the preliminary image. Extensive experiments demonstrate that the DR$^{2}$-Net outperforms traditional iterative methods and recent deep learning-based methods by large margins at measurement rates 0.01, 0.04, 0.1, and 0.25, respectively. The code of DR$^{2}$-Net has been released on: https://github.com/coldrainyht/caffe\_dr2