 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning for Compressed Video Action Recognition via Attentive Cross-modal Interaction with Motion Enhancement
Paper and Code
May 10, 2022
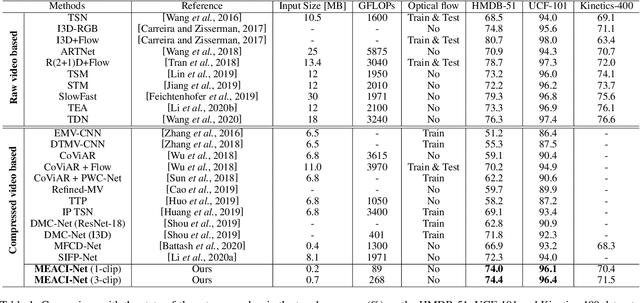

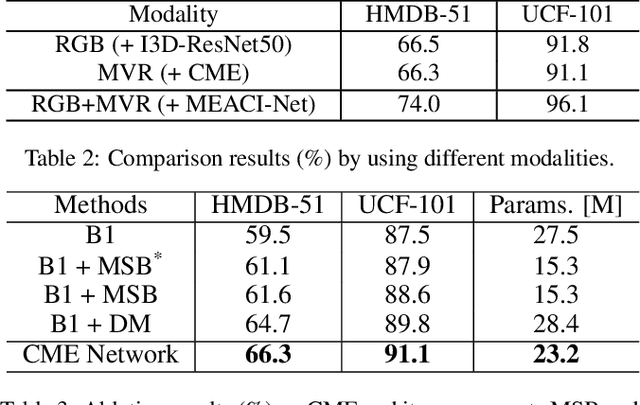
Compressed video action recognition has recently drawn growing attention, since it remarkably reduces the storage and computational cost via replacing raw videos by sparsely sampled RGB frames and compressed motion cues (e.g., motion vectors and residuals). However, this task severely suffers from the coarse and noisy dynamics and the insufficient fusion of the heterogeneous RGB and motion modalities. To address the two issues above, this paper proposes a novel framework, namely Attentive Cross-modal Interaction Network with Motion Enhancement (MEACI-Net). It follows the two-stream architecture, i.e. one for the RGB modality and the other for the motion modality. Particularly, the motion stream employs a multi-scale block embedded with a denoising module to enhance representation learning. The interaction between the two streams is then strengthened by introducing the Selective Motion Complement (SMC) and Cross-Modality Augment (CMA) modules, where SMC complements the RGB modality with spatio-temporally attentive local motion features and CMA further combines the two modalities with selective feature augmentation. Extensive experiments on the UCF-101, HMDB-51 and Kinetics-400 benchmarks demonstrate the effectiveness and efficiency of MEACI-Net.