 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrackSegDiff: Diffusion Probability Model-based Multi-modal Crack Segmentation
Oct 10, 2024



Integrating grayscale and depth data in road inspection robots could enhance the accuracy, reliability, and comprehensiveness of road condition assessments, leading to improved maintenance strategies and safer infrastructure. However, these data sources are often compromised by significant background noise from the pavement. Recent advancements in Diffusion Probabilistic Models (DPM) have demonstrated remarkable success in image segmentation tasks, showcasing potent denoising capabilities, as evidenced in studies like SegDiff \cite{amit2021segdiff}. Despite these advancements, current DPM-based segmentors do not fully capitalize on the potential of original image data. In this paper, we propose a novel DPM-based approach for crack segmentation, named CrackSegDiff, which uniquely fuses grayscale and range/depth images. This method enhances the reverse diffusion process by intensifying the interaction between local feature extraction via DPM and global feature extraction. Unlike traditional methods that utilize Transformers for global features, our approach employs Vm-unet \cite{ruan2024vm} to efficiently capture long-range information of the original data. The integration of features is further refined through two innovative modules: the Channel Fusion Module (CFM) and the Shallow Feature Compensation Module (SFCM). Our experimental evaluation on the three-class crack image segmentation tasks within the FIND dataset demonstrates that CrackSegDiff outperforms state-of-the-art methods, particularly excelling in the detection of shallow cracks. Code is available at https://github.com/sky-visionX/CrackSegDiff.
Fast-Fading Channel and Power Optimization of the Magnetic Inductive Cellular Network
Jun 07, 2024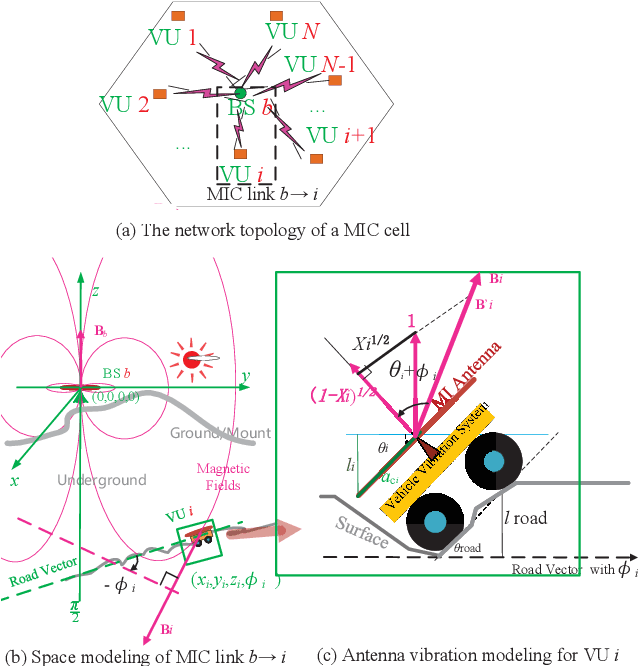
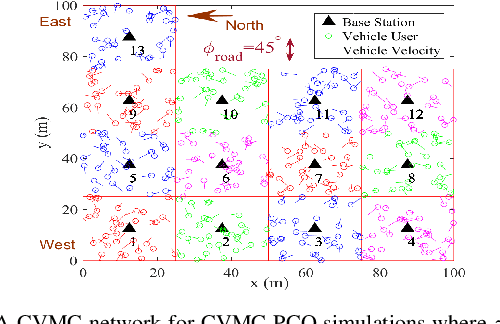
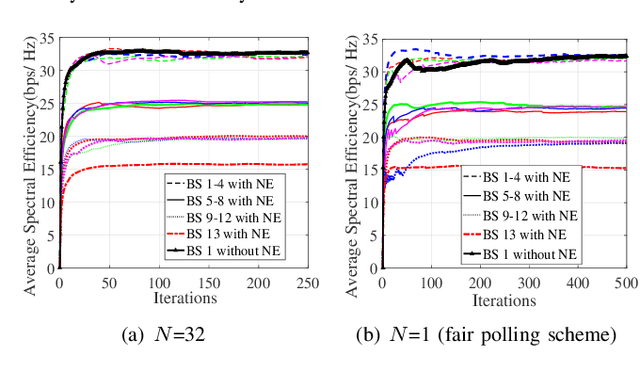
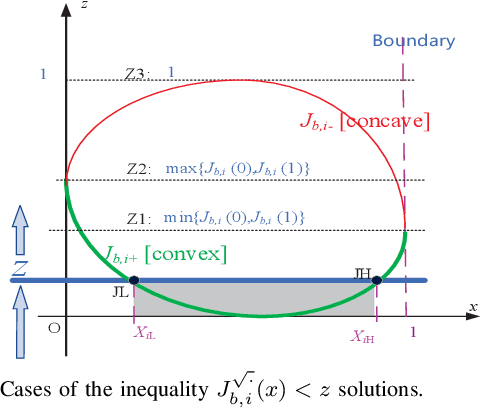
The cellular network of magnetic Induction (MI) communication holds promise in long-distance underground environments. In the traditional MI communication, there is no fast-fading channel since the MI channel is treated as a quasi-static channel. However, for the vehicle (mobile) MI (VMI) communication, the unpredictable antenna vibration brings the remarkable fast-fading. As such fast-fading cannot be modeled by the central limit theorem, it differs radically from other wireless fast-fading channels. Unfortunately, few studies focus on this phenomenon. In this paper, using a novel space modeling based on the electromagnetic field theorem, we propose a 3-dimension model of the VMI antenna vibration. By proposing ``conjugate pseudo-piecewise functions'' and boundary $p(x)$ distribution, we derive the cumulative distribution function (CDF), probability density function (PDF) and the expectation of the VMI fast-fading channel. We also theoretically analyze the effects of the VMI fast-fading on the network throughput, including the VMI outage probability which can be ignored in the traditional MI channel study. We draw several intriguing conclusions different from those in wireless fast-fading studies. For instance, the fast-fading brings more uniformly distributed channel coefficients. Finally, we propose the power control algorithm using the non-cooperative game and multiagent Q-learning methods to optimize the throughput of the cellular VMI network. Simulations validate the derivation and the proposed algorithm.
Towards Few-shot Out-of-Distribution Detection
Nov 20, 2023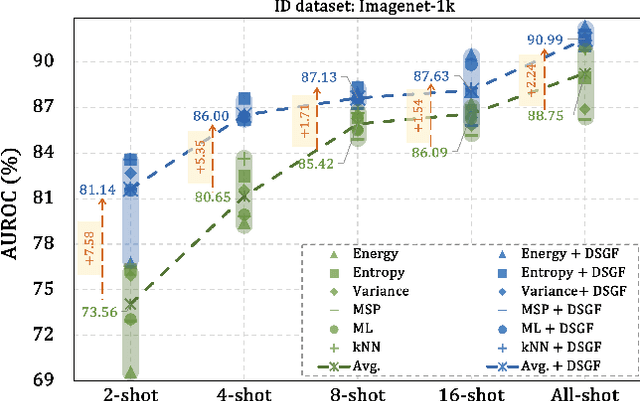



Out-of-distribution (OOD) detection is critical for ensuring the reliability of open-world intelligent systems. Despite the notable advancements in existing OOD detection methodologies, our study identifies a significant performance drop under the scarcity of training samples. In this context, we introduce a novel few-shot OOD detection benchmark, carefully constructed to address this gap. Our empirical analysis reveals the superiority of ParameterEfficient Fine-Tuning (PEFT) strategies, such as visual prompt tuning and visual adapter tuning, over conventional techniques, including fully fine-tuning and linear probing tuning in the few-shot OOD detection task. Recognizing some crucial information from the pre-trained model, which is pivotal for OOD detection, may be lost during the fine-tuning process, we propose a method termed DomainSpecific and General Knowledge Fusion (DSGF). This approach is designed to be compatible with diverse fine-tuning frameworks. Our experiments show that the integration of DSGF significantly enhances the few-shot OOD detection capabilities across various methods and fine-tuning methodologies, including fully fine-tuning, visual adapter tuning, and visual prompt tuning. The code will be released.
A Wasserstein GAN model with the total variational regularization
Dec 03, 2018



It is well known that the generative adversarial nets (GANs) are remarkably difficult to train. The recently proposed Wasserstein GAN (WGAN) creates principled research directions towards addressing these issues. But we found in practice that gradient penalty WGANs (GP-WGANs) still suffer from training instability. In this paper, we combine a Total Variational (TV) regularizing term into the WGAN formulation instead of weight clipping or gradient penalty, which implies that the Lipschitz constraint is enforced on the critic network. Our proposed method is more stable at training than GP-WGANs and works well across varied GAN architectures. We also present a method to control the trade-off between image diversity and visual quality. It does not bring any computation burden.
An Image dehazing approach based on the airlight field estimation
May 06, 2018



This paper proposes a scheme for single image haze removal based on the airlight field (ALF) estimation. Conventional image dehazing methods which are based on a physical model generally take the global atmospheric light as a constant. However, the constant-airlight assumption may be unsuitable for images with large sky regions, which causes unacceptable brightness imbalance and color distortion in recovery images. This paper models the atmospheric light as a field function, and presents a maximum a-priori (MAP) method for jointly estimating the airlight field, the transmission rate and the haze free image. We also introduce a valid haze-level prior for effective estimate of transmission. Evaluation on real world images shows that the proposed approach outperforms existing methods in single image dehazing, especially when the large sky region is included.