 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for Best Practices in Medical Transcription with Large Language Model
Oct 04, 2024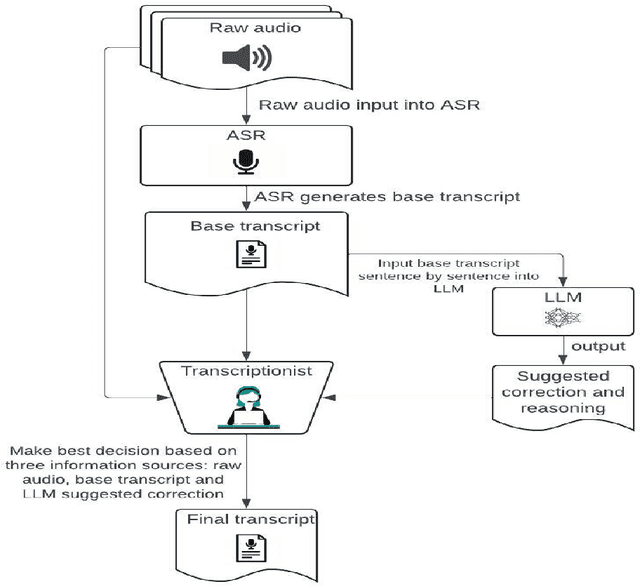
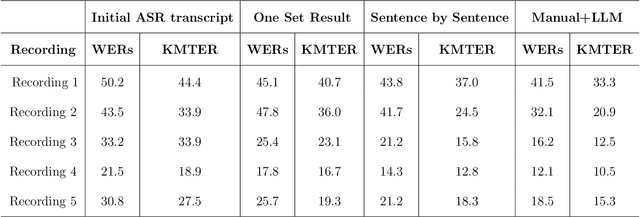
The transcription of medical monologues, especially those containing a high density of specialized terminology and delivered with a distinct accent, presents a significant challenge for existing automated systems. This paper introduces a novel approach leveraging a Large Language Model (LLM) to generate highly accurate medical transcripts from audio recordings of doctors' monologues, specifically focusing on Indian accents. Our methodology integrates advanced language modeling techniques to lower the Word Error Rate (WER) and ensure the precise recognition of critical medical terms. Through rigorous testing on a comprehensive dataset of medical recordings, our approach demonstrates substantial improvements in both overall transcription accuracy and the fidelity of key medical terminologies. These results suggest that our proposed system could significantly aid in clinical documentation processes, offering a reliable tool for healthcare providers to streamline their transcription needs while maintaining high standards of accuracy.
RGDA-DDI: Residual graph attention network and dual-attention based framework for drug-drug interaction prediction
Aug 27, 2024Recent studies suggest that drug-drug interaction (DDI) prediction via computational approaches has significant importance for understanding the functions and co-prescriptions of multiple drugs. However, the existing silico DDI prediction methods either ignore the potential interactions among drug-drug pairs (DDPs), or fail to explicitly model and fuse the multi-scale drug feature representations for better prediction. In this study, we propose RGDA-DDI, a residual graph attention network (residual-GAT) and dual-attention based framework for drug-drug interaction prediction. A residual-GAT module is introduced to simultaneously learn multi-scale feature representations from drugs and DDPs. In addition, a dual-attention based feature fusion block is constructed to learn local joint interaction representations. A series of evaluation metrics demonstrate that the RGDA-DDI significantly improved DDI prediction performance on two public benchmark datasets, which provides a new insight into drug development.
Using machine learning on new feature sets extracted from 3D models of broken animal bones to classify fragments according to break agent
May 20, 2022
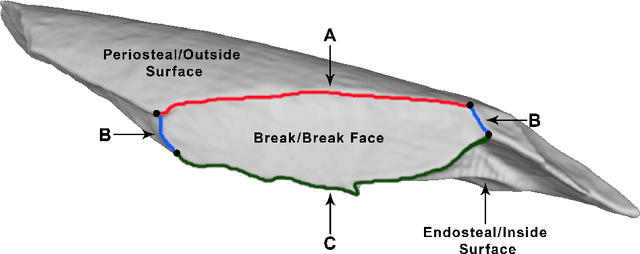
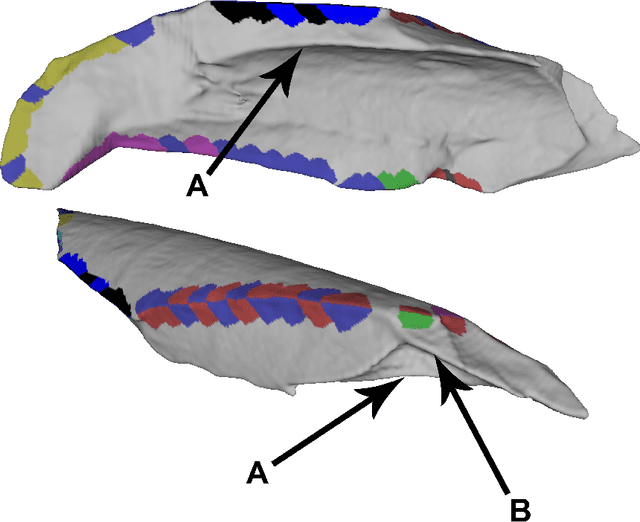
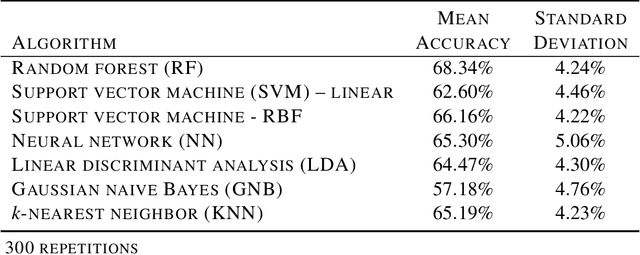
Distinguishing agents of bone modification at paleoanthropological sites is at the root of much of the research directed at understanding early hominin exploitation of large animal resources and the effects those subsistence behaviors had on early hominin evolution. However, current methods, particularly in the area of fracture pattern analysis as a signal of marrow exploitation, have failed to overcome equifinality. Furthermore, researchers debate the replicability and validity of current and emerging methods for analyzing bone modifications. Here we present a new approach to fracture pattern analysis aimed at distinguishing bone fragments resulting from hominin bone breakage and those produced by carnivores. This new method uses 3D models of fragmentary bone to extract a much richer dataset that is more transparent and replicable than feature sets previously used in fracture pattern analysis. Supervised machine learning algorithms are properly used to classify bone fragments according to agent of breakage with average mean accuracy of 77% across tests.
Blur-Attention: A boosting mechanism for non-uniform blurred image restoration
Aug 19, 2020
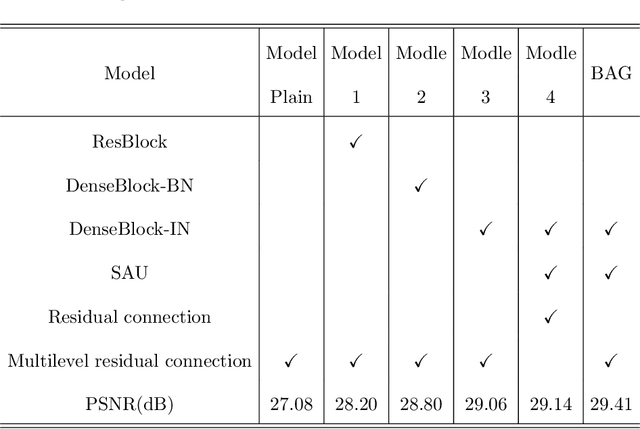
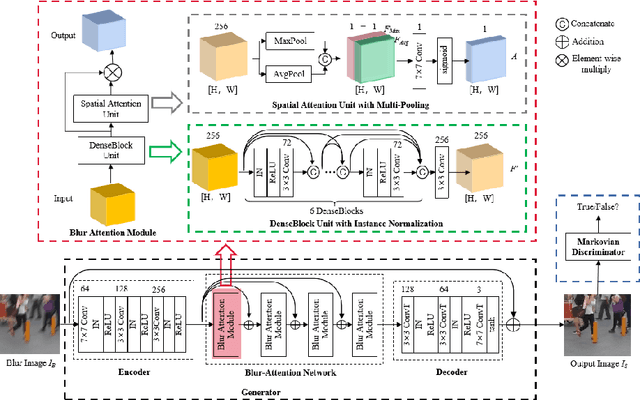
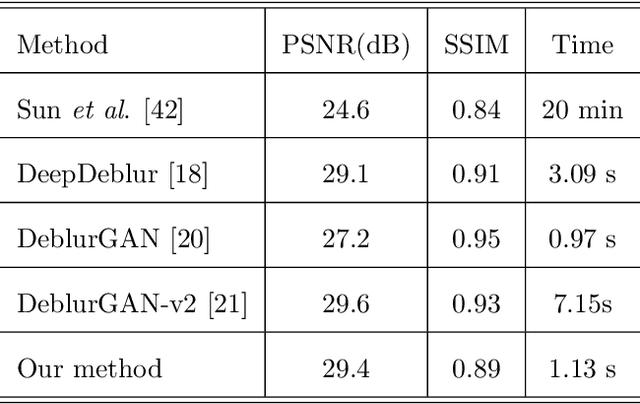
Dynamic scene deblurring is a challenging problem in computer vision. It is difficult to accurately estimate the spatially varying blur kernel by traditional methods. Data-driven-based methods usually employ kernel-free end-to-end mapping schemes, which are apt to overlook the kernel estimation. To address this issue, we propose a blur-attention module to dynamically capture the spatially varying features of non-uniform blurred images. The module consists of a DenseBlock unit and a spatial attention unit with multi-pooling feature fusion, which can effectively extract complex spatially varying blur features. We design a multi-level residual connection structure to connect multiple blur-attention modules to form a blur-attention network. By introducing the blur-attention network into a conditional generation adversarial framework, we propose an end-to-end blind motion deblurring method, namely Blur-Attention-GAN (BAG), for a single image. Our method can adaptively select the weights of the extracted features according to the spatially varying blur features, and dynamically restore the images. Experimental results show that the deblurring capability of our method achieved outstanding objective performance in terms of PSNR, SSIM, and subjective visual quality. Furthermore, by visualizing the features extracted by the blur-attention module, comprehensive discussions are provided on its effectiveness.