 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Correcting Sequential Recommender
Paper and Code



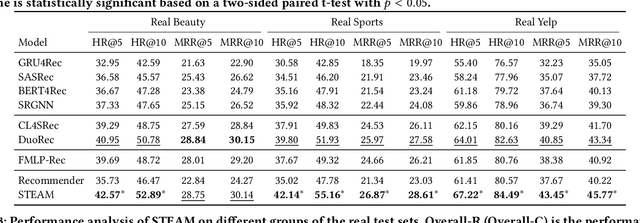
Sequential recommendations aim to capture users' preferences from their historical interactions so as to predict the next item that they will interact with. Sequential recommendation methods usually assume that all items in a user's historical interactions reflect her/his preferences and transition patterns between items. However, real-world interaction data is imperfect in that (i) users might erroneously click on items, i.e., so-called misclicks on irrelevant items, and (ii) users might miss items, i.e., unexposed relevant items due to inaccurate recommendations. To tackle the two issues listed above, we propose STEAM, a Self-correcTing sEquentiAl recoMmender. STEAM first corrects an input item sequence by adjusting the misclicked and/or missed items. It then uses the corrected item sequence to train a recommender and make the next item prediction.We design an item-wise corrector that can adaptively select one type of operation for each item in the sequence. The operation types are 'keep', 'delete' and 'insert.' In order to train the item-wise corrector without requiring additional labeling, we design two self-supervised learning mechanisms: (i) deletion correction (i.e., deleting randomly inserted items), and (ii) insertion correction (i.e., predicting randomly deleted items). We integrate the corrector with the recommender by sharing the encoder and by training them jointly. We conduct extensive experiments on three real-world datasets and the experimental results demonstrate that STEAM outperforms state-of-the-art sequential recommendation baselines. Our in-depth analyses confirm that STEAM benefits from learning to correct the raw item sequences.