 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptSplat: Adapting Vision Foundation Models for Feed-Forward 3D Gaussian Splatting
May 11, 2026This work explores a simple yet powerful lightweight adapter design for feed-forward 3D Gaussian Splatting (3DGS). Existing methods typically apply complex, architecture-specific designs on top of the generic pipeline of image feature extraction $\rightarrow$ multi-view interaction $\rightarrow$ feature decoding. However, constrained by the scale bottleneck of 3D training data and the low-pass filtering effect of deep networks, these methods still fall short in cross-domain generalization and high-frequency geometric fidelity. To address these problems, we propose AdaptSplat, which demonstrates that without complex component engineering, introducing a single adapter of only 1.5M parameters into the generic architecture is sufficient to achieve superior performance. Specifically, we design a lightweight Frequency-Preserving Adapter (FPA) that extracts direction-aware high-frequency structural priors from the shallow features of a powerful vision foundation model backbone, and seamlessly integrates them into the generic pipeline via high-frequency positional encodings and adaptive residual modulation. This effectively compensates for the high-frequency attenuation caused by over-smoothing in deep features, improving the fitting accuracy of Gaussian primitives on complex surfaces and sharp boundaries. Extensive experiments demonstrate that AdaptSplat achieves state-of-the-art feed-forward reconstruction performance on multiple standard benchmarks, with stable generalization across domains. Code available at: https://github.com/xmw666/AdaptSplat.
DoReMi: A Domain-Representation Mixture Framework for Generalizable 3D Understanding
Nov 14, 2025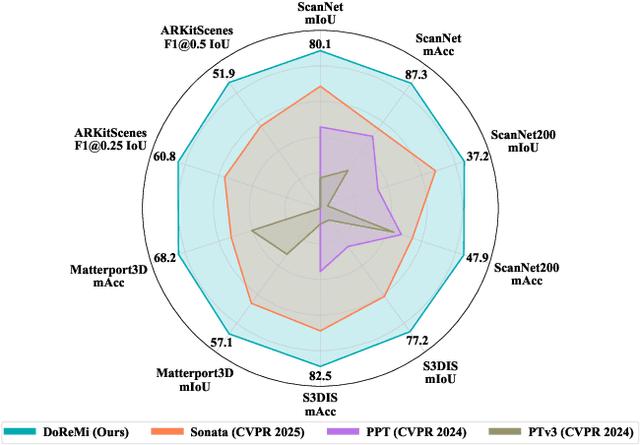
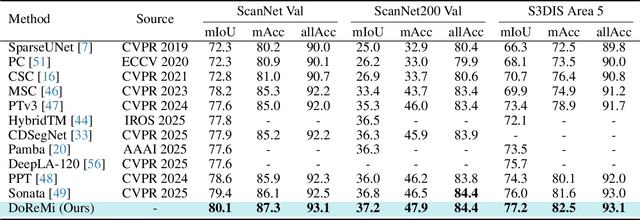
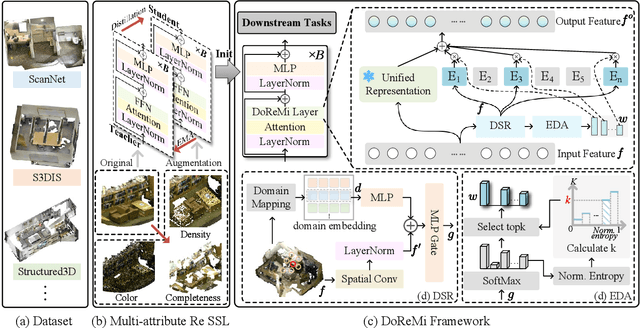

The generalization of 3D deep learning across multiple domains remains limited by the limited scale of existing datasets and the high heterogeneity of multi-source point clouds. Point clouds collected from different sensors (e.g., LiDAR scans and mesh-derived point clouds) exhibit substantial discrepancies in density and noise distribution, resulting in negative transfer during multi-domain fusion. Most existing approaches focus exclusively on either domain-aware or domain-general features, overlooking the potential synergy between them. To address this, we propose DoReMi (Domain-Representation Mixture), a Mixture-of-Experts (MoE) framework that jointly models Domain-aware Experts branch and a unified Representation branch to enable cooperative learning between specialized and generalizable knowledge. DoReMi dynamically activates domain-aware expert branch via Domain-Guided Spatial Routing (DSR) for context-aware expert selection and employs Entropy-Controlled Dynamic Allocation (EDA) for stable and efficient expert utilization, thereby adaptively modeling diverse domain distributions. Complemented by a frozen unified representation branch pretrained through robust multi-attribute self-supervised learning, DoReMi preserves cross-domain geometric and structural priors while maintaining global consistency. We evaluate DoReMi across multiple 3D understanding benchmarks. Notably, DoReMi achieves 80.1% mIoU on ScanNet Val and 77.2% mIoU on S3DIS, demonstrating competitive or superior performance compared to existing approaches, and showing strong potential as a foundation framework for future 3D understanding research. The code will be released soon.
Fusion-then-Distillation: Toward Cross-modal Positive Distillation for Domain Adaptive 3D Semantic Segmentation
Oct 25, 2024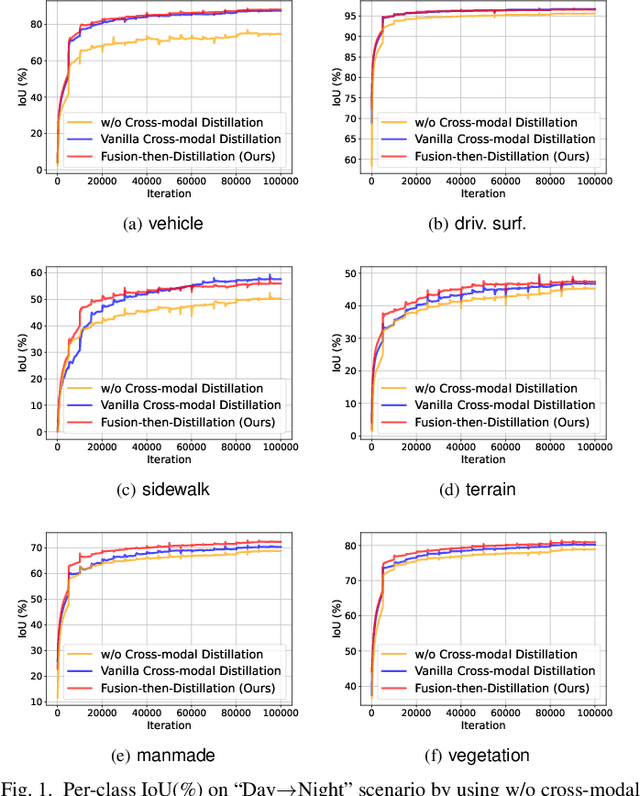
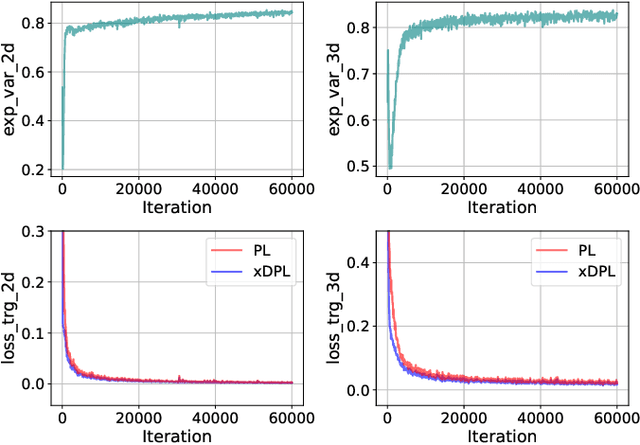
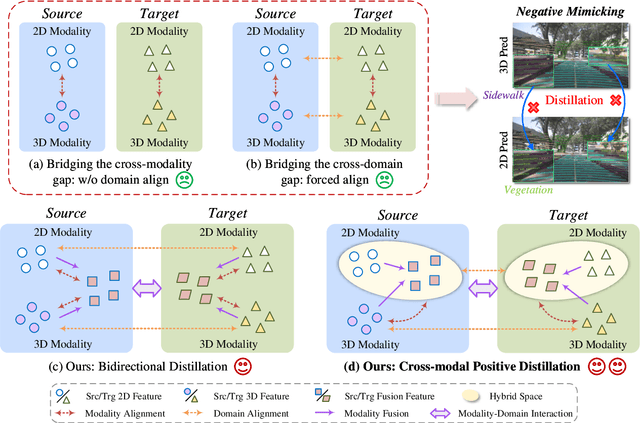
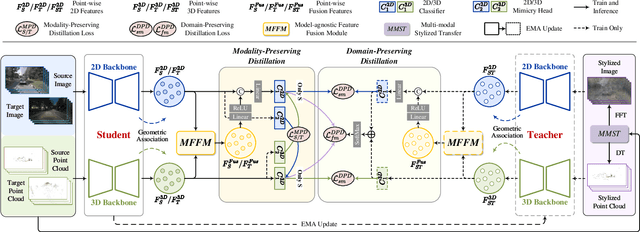
In cross-modal unsupervised domain adaptation, a model trained on source-domain data (e.g., synthetic) is adapted to target-domain data (e.g., real-world) without access to target annotation. Previous methods seek to mutually mimic cross-modal outputs in each domain, which enforces a class probability distribution that is agreeable in different domains. However, they overlook the complementarity brought by the heterogeneous fusion in cross-modal learning. In light of this, we propose a novel fusion-then-distillation (FtD++) method to explore cross-modal positive distillation of the source and target domains for 3D semantic segmentation. FtD++ realizes distribution consistency between outputs not only for 2D images and 3D point clouds but also for source-domain and augment-domain. Specially, our method contains three key ingredients. First, we present a model-agnostic feature fusion module to generate the cross-modal fusion representation for establishing a latent space. In this space, two modalities are enforced maximum correlation and complementarity. Second, the proposed cross-modal positive distillation preserves the complete information of multi-modal input and combines the semantic content of the source domain with the style of the target domain, thereby achieving domain-modality alignment. Finally, cross-modal debiased pseudo-labeling is devised to model the uncertainty of pseudo-labels via a self-training manner. Extensive experiments report state-of-the-art results on several domain adaptive scenarios under unsupervised and semi-supervised settings. Code is available at https://github.com/Barcaaaa/FtD-PlusPlus.