 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Modality-Aware Fusion and Decoupled Temporal Propagation for Multi-Modal Object Tracking
Mar 10, 2026Most existing multimodal trackers adopt uniform fusion strategies, overlooking the inherent differences between modalities. Moreover, they propagate temporal information through mixed tokens, leading to entangled and less discriminative temporal representations. To address these limitations, we propose MDTrack, a novel framework for modality aware fusion and decoupled temporal propagation in multimodal object tracking. Specifically, for modality aware fusion, we allocate dedicated experts to each modality, including infrared, event, depth, and RGB, to process their respective representations. The gating mechanism within the Mixture of Experts dynamically selects the optimal experts based on the input features, enabling adaptive and modality specific fusion. For decoupled temporal propagation, we introduce two separate State Space Model structures to independently store and update the hidden states of the RGB and X modal streams, effectively capturing their distinct temporal information. To ensure synergy between the two temporal representations, we incorporate a set of cross attention modules between the input features of the two SSMs, facilitating implicit information exchange. The resulting temporally enriched features are then integrated into the backbone through another set of cross attention modules, enhancing MDTrack's ability to leverage temporal information. Extensive experiments demonstrate the effectiveness of our proposed method. Both MDTrack S and MDTrack U achieve state of the art performance across five multimodal tracking benchmarks.
Conditional GAN for Enhancing Diffusion Models in Efficient and Authentic Global Gesture Generation from Audios
Oct 27, 2024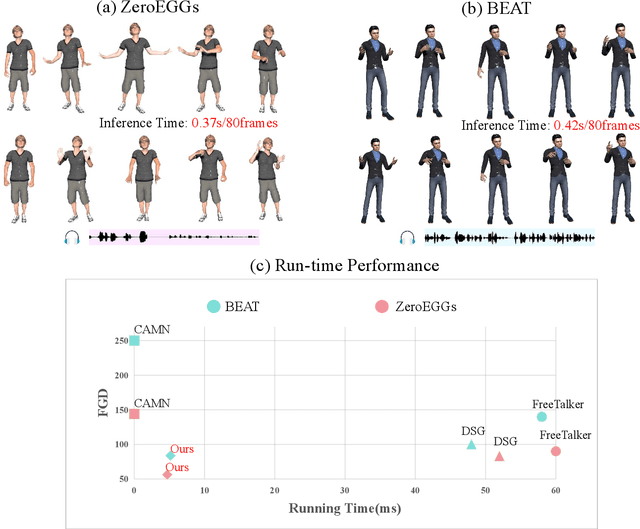

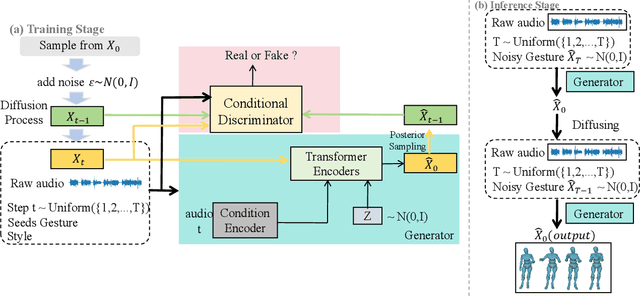

Audio-driven simultaneous gesture generation is vital for human-computer communication, AI games, and film production. While previous research has shown promise, there are still limitations. Methods based on VAEs are accompanied by issues of local jitter and global instability, whereas methods based on diffusion models are hampered by low generation efficiency. This is because the denoising process of DDPM in the latter relies on the assumption that the noise added at each step is sampled from a unimodal distribution, and the noise values are small. DDIM borrows the idea from the Euler method for solving differential equations, disrupts the Markov chain process, and increases the noise step size to reduce the number of denoising steps, thereby accelerating generation. However, simply increasing the step size during the step-by-step denoising process causes the results to gradually deviate from the original data distribution, leading to a significant drop in the quality of the generated actions and the emergence of unnatural artifacts. In this paper, we break the assumptions of DDPM and achieves breakthrough progress in denoising speed and fidelity. Specifically, we introduce a conditional GAN to capture audio control signals and implicitly match the multimodal denoising distribution between the diffusion and denoising steps within the same sampling step, aiming to sample larger noise values and apply fewer denoising steps for high-speed generation.
ExpGest: Expressive Speaker Generation Using Diffusion Model and Hybrid Audio-Text Guidance
Oct 12, 2024



Existing gesture generation methods primarily focus on upper body gestures based on audio features, neglecting speech content, emotion, and locomotion. These limitations result in stiff, mechanical gestures that fail to convey the true meaning of audio content. We introduce ExpGest, a novel framework leveraging synchronized text and audio information to generate expressive full-body gestures. Unlike AdaIN or one-hot encoding methods, we design a noise emotion classifier for optimizing adversarial direction noise, avoiding melody distortion and guiding results towards specified emotions. Moreover, aligning semantic and gestures in the latent space provides better generalization capabilities. ExpGest, a diffusion model-based gesture generation framework, is the first attempt to offer mixed generation modes, including audio-driven gestures and text-shaped motion. Experiments show that our framework effectively learns from combined text-driven motion and audio-induced gesture datasets, and preliminary results demonstrate that ExpGest achieves more expressive, natural, and controllable global motion in speakers compared to state-of-the-art models.
Human-to-Human Interaction Detection
Jul 02, 2023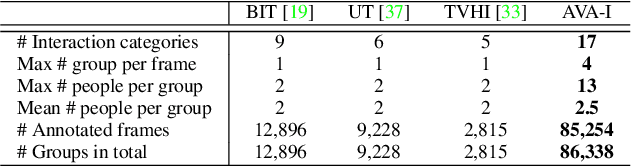
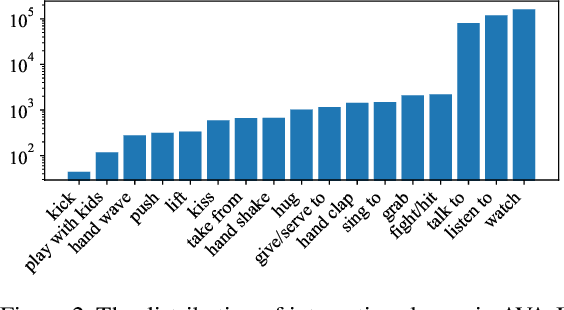


A comprehensive understanding of interested human-to-human interactions in video streams, such as queuing, handshaking, fighting and chasing, is of immense importance to the surveillance of public security in regions like campuses, squares and parks. Different from conventional human interaction recognition, which uses choreographed videos as inputs, neglects concurrent interactive groups, and performs detection and recognition in separate stages, we introduce a new task named human-to-human interaction detection (HID). HID devotes to detecting subjects, recognizing person-wise actions, and grouping people according to their interactive relations, in one model. First, based on the popular AVA dataset created for action detection, we establish a new HID benchmark, termed AVA-Interaction (AVA-I), by adding annotations on interactive relations in a frame-by-frame manner. AVA-I consists of 85,254 frames and 86,338 interactive groups, and each image includes up to 4 concurrent interactive groups. Second, we present a novel baseline approach SaMFormer for HID, containing a visual feature extractor, a split stage which leverages a Transformer-based model to decode action instances and interactive groups, and a merging stage which reconstructs the relationship between instances and groups. All SaMFormer components are jointly trained in an end-to-end manner. Extensive experiments on AVA-I validate the superiority of SaMFormer over representative methods. The dataset and code will be made public to encourage more follow-up studies.
BoPR: Body-aware Part Regressor for Human Shape and Pose Estimation
Mar 24, 2023This paper presents a novel approach for estimating human body shape and pose from monocular images that effectively addresses the challenges of occlusions and depth ambiguity. Our proposed method BoPR, the Body-aware Part Regressor, first extracts features of both the body and part regions using an attention-guided mechanism. We then utilize these features to encode extra part-body dependency for per-part regression, with part features as queries and body feature as a reference. This allows our network to infer the spatial relationship of occluded parts with the body by leveraging visible parts and body reference information. Our method outperforms existing state-of-the-art methods on two benchmark datasets, and our experiments show that it significantly surpasses existing methods in terms of depth ambiguity and occlusion handling. These results provide strong evidence of the effectiveness of our approach.The code and data are available for research purposes at https://github.com/cyk990422/BoPR.
Multi-modal and frequency-weighted tensor nuclear norm for hyperspectral image denoising
Jun 23, 2021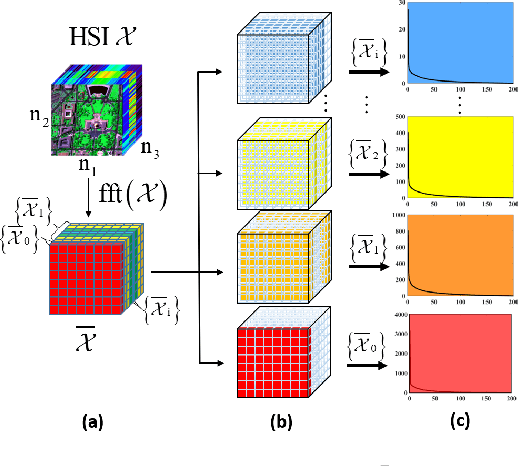



Low-rankness is important in the hyperspectral image (HSI) denoising tasks. The tensor nuclear norm (TNN), defined based on the tensor singular value decomposition, is a state-of-the-art method to describe the low-rankness of HSI. However, TNN ignores some of the physical meanings of HSI in tackling the denoising tasks, leading to suboptimal denoising performance. In this paper, we propose the multi-modal and frequency-weighted tensor nuclear norm (MFWTNN) and the non-convex MFWTNN for HSI denoising tasks. Firstly, we investigate the physical meaning of frequency components and reconsider their weights to improve the low-rank representation ability of TNN. Meanwhile, we also consider the correlation among two spatial dimensions and the spectral dimension of HSI and combine the above improvements to TNN to propose MFWTNN. Secondly, we use non-convex functions to approximate the rank function of the frequency tensor and propose the NonMFWTNN to relax the MFWTNN better. Besides, we adaptively choose bigger weights for slices mainly containing noise information and smaller weights for slices containing profile information. Finally, we develop the efficient alternating direction method of multiplier (ADMM) based algorithm to solve the proposed models, and the effectiveness of our models are substantiated in simulated and real HSI datasets.
Multi-mode Core Tensor Factorization based Low-Rankness and Its Applications to Tensor Completion
Dec 03, 2020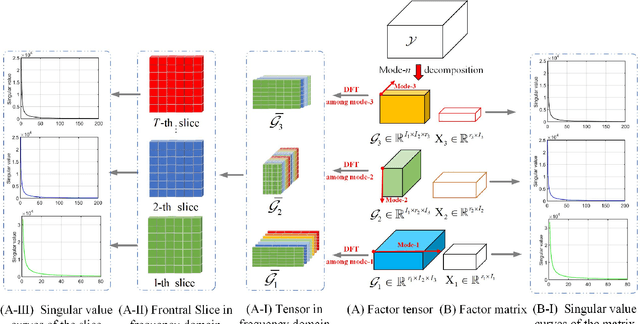

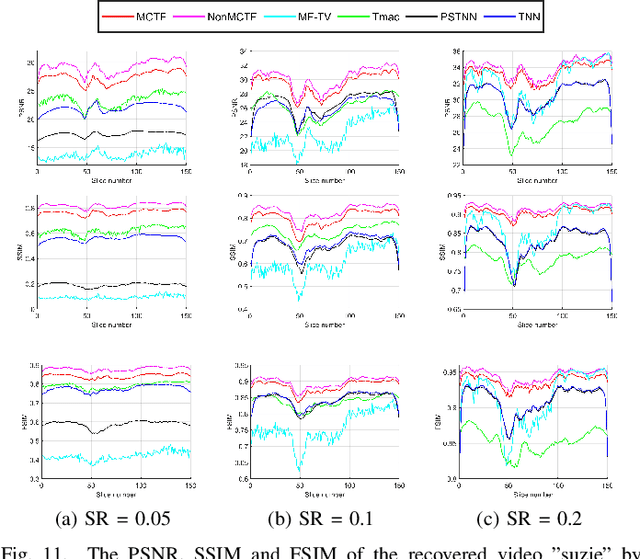
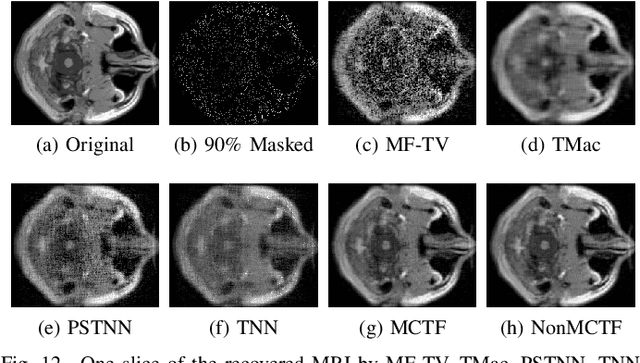
Low-rank tensor completion has been widely used in computer vision and machine learning. This paper develops a tensor low-rank decomposition method together with a tensor low-rankness measure (MCTF) and a better nonconvex relaxation form of it (NonMCTF). This is the first method that can accurately restore the clean data of intrinsic low-rank structure based on few known inputs. This metric encodes low-rank insights for general tensors provided by Tucker and T-SVD. Furthermore, we studied the MCTF and NonMCTF regularization minimization problem, and designed an effective BSUM algorithm to solve the problem. This efficient solver can extend MCTF to various tasks, such as tensor completion and tensor robust principal component analysis. A series of experiments, including hyperspectral image (HSI) denoising, video completion and MRI restoration, confirmed the superior performance of the proposed method
Enhanced nonconvex low-rank approximation of tensor multi-modes for tensor completion
Jun 22, 2020
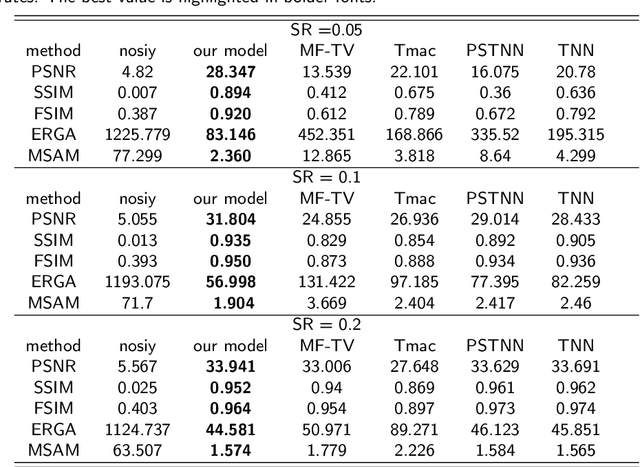
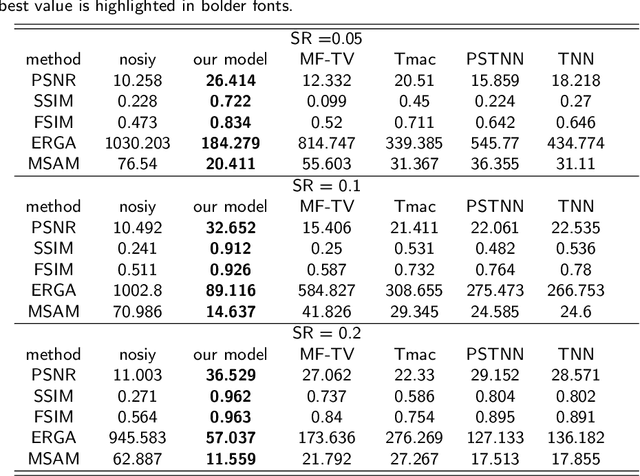
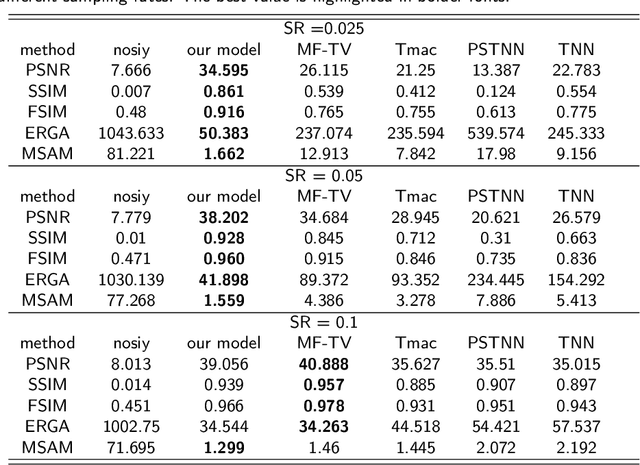
Higher-order low-rank tensor arises in many data processing applications and has attracted great interests. Inspired by low-rank approximation theory, researchers have proposed a series of effective tensor completion methods. However, most of these methods directly consider the global low-rankness of underlying tensors, which is not sufficient for a low sampling rate; in addition, the single nuclear norm or its relaxation is usually adopted to approximate the rank function, which would lead to suboptimal solution deviated from the original one. To alleviate the above problems, in this paper, we propose a novel low-rank approximation of tensor multi-modes (LRATM), in which a double nonconvex $L_{\gamma}$ norm is designed to represent the underlying joint-manifold drawn from the modal factorization factors of the underlying tensor. A block successive upper-bound minimization method-based algorithm is designed to efficiently solve the proposed model, and it can be demonstrated that our numerical scheme converges to the coordinatewise minimizers. Numerical results on three types of public multi-dimensional datasets have tested and shown that our algorithm can recover a variety of low-rank tensors with significantly fewer samples than the compared methods.
Hyperspectral Image Denoising via Global Spatial-Spectral Total Variation Regularized Nonconvex Local Low-Rank Tensor Approximation
May 30, 2020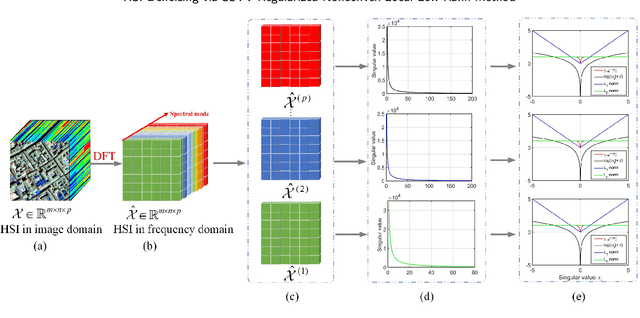
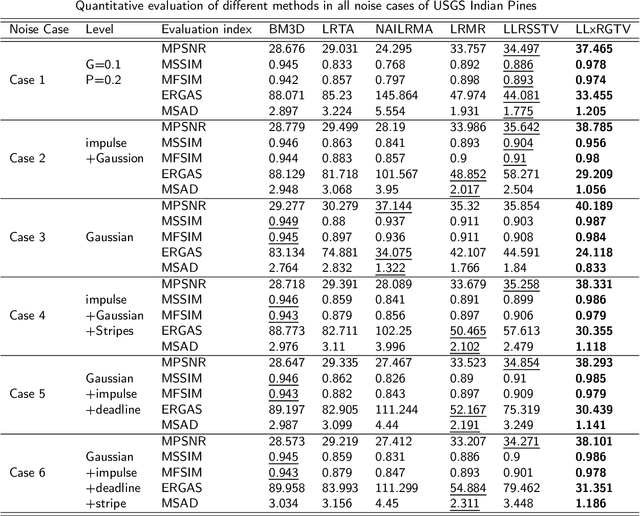
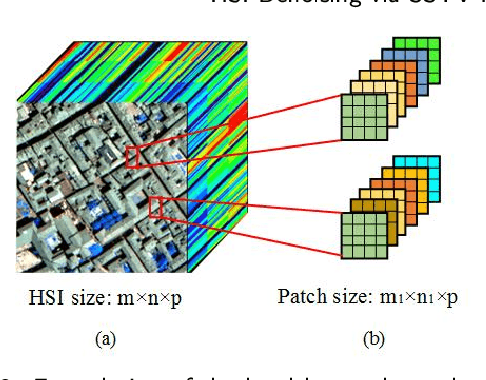
Hyperspectral image (HSI) denoising aims to restore clean HSI from the noise-contaminated one. Noise contamination can often be caused during data acquisition and conversion. In this paper, we propose a novel spatial-spectral total variation (SSTV) regularized nonconvex local low-rank (LR) tensor approximation method to remove mixed noise in HSIs. From one aspect, the clean HSI data have its underlying local LR tensor property, even though the real HSI data may not be globally low-rank due to out-liers and non-Gaussian noise. According to this fact, we propose a novel tensor $L_{\gamma}$-norm to formulate the local LR prior. From another aspect, HSIs are assumed to be piecewisely smooth in the global spatial and spectral domains. Instead of traditional bandwise total variation, we use the SSTV regularization to simultaneously consider global spatial structure and spectral correlation of neighboring bands. Results on simulated and real HSI datasets indicate that the use of local LR tensor penalty and global SSTV can boost the preserving of local details and overall structural information in HSIs.
Hyperspectral Image Restoration via Global Total Variation Regularized Local nonconvex Low-Rank matrix Approximation
May 08, 2020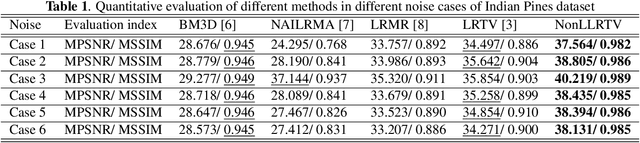


Several bandwise total variation (TV) regularized low-rank (LR)-based models have been proposed to remove mixed noise in hyperspectral images (HSIs). Conventionally, the rank of LR matrix is approximated using nuclear norm (NN). The NN is defined by adding all singular values together, which is essentially a $L_1$-norm of the singular values. It results in non-negligible approximation errors and thus the resulting matrix estimator can be significantly biased. Moreover, these bandwise TV-based methods exploit the spatial information in a separate manner. To cope with these problems, we propose a spatial-spectral TV (SSTV) regularized non-convex local LR matrix approximation (NonLLRTV) method to remove mixed noise in HSIs. From one aspect, local LR of HSIs is formulated using a non-convex $L_{\gamma}$-norm, which provides a closer approximation to the matrix rank than the traditional NN. From another aspect, HSIs are assumed to be piecewisely smooth in the global spatial domain. The TV regularization is effective in preserving the smoothness and removing Gaussian noise. These facts inspire the integration of the NonLLR with TV regularization. To address the limitations of bandwise TV, we use the SSTV regularization to simultaneously consider global spatial structure and spectral correlation of neighboring bands. Experiment results indicate that the use of local non-convex penalty and global SSTV can boost the preserving of spatial piecewise smoothness and overall structural information.