 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRopeTP: Global Human Motion Recovery via Integrating Robust Pose Estimation with Diffusion Trajectory Prior
Oct 27, 2024



We present RopeTP, a novel framework that combines Robust pose estimation with a diffusion Trajectory Prior to reconstruct global human motion from videos. At the heart of RopeTP is a hierarchical attention mechanism that significantly improves context awareness, which is essential for accurately inferring the posture of occluded body parts. This is achieved by exploiting the relationships with visible anatomical structures, enhancing the accuracy of local pose estimations. The improved robustness of these local estimations allows for the reconstruction of precise and stable global trajectories. Additionally, RopeTP incorporates a diffusion trajectory model that predicts realistic human motion from local pose sequences. This model ensures that the generated trajectories are not only consistent with observed local actions but also unfold naturally over time, thereby improving the realism and stability of 3D human motion reconstruction. Extensive experimental validation shows that RopeTP surpasses current methods on two benchmark datasets, particularly excelling in scenarios with occlusions. It also outperforms methods that rely on SLAM for initial camera estimates and extensive optimization, delivering more accurate and realistic trajectories.
Generating Holistic 3D Human Motion from Speech
Dec 08, 2022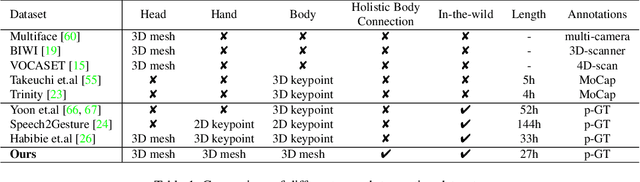

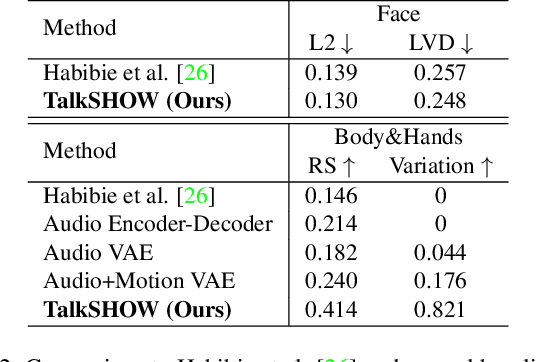
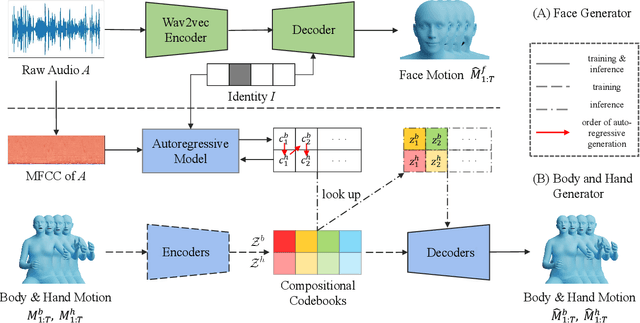
This work addresses the problem of generating 3D holistic body motions from human speech. Given a speech recording, we synthesize sequences of 3D body poses, hand gestures, and facial expressions that are realistic and diverse. To achieve this, we first build a high-quality dataset of 3D holistic body meshes with synchronous speech. We then define a novel speech-to-motion generation framework in which the face, body, and hands are modeled separately. The separated modeling stems from the fact that face articulation strongly correlates with human speech, while body poses and hand gestures are less correlated. Specifically, we employ an autoencoder for face motions, and a compositional vector-quantized variational autoencoder (VQ-VAE) for the body and hand motions. The compositional VQ-VAE is key to generating diverse results. Additionally, we propose a cross-conditional autoregressive model that generates body poses and hand gestures, leading to coherent and realistic motions. Extensive experiments and user studies demonstrate that our proposed approach achieves state-of-the-art performance both qualitatively and quantitatively. Our novel dataset and code will be released for research purposes at https://talkshow.is.tue.mpg.de.