 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARD: Semantic Segmentation with Efficient Class-Aware Regularized Decoder
Paper and Code
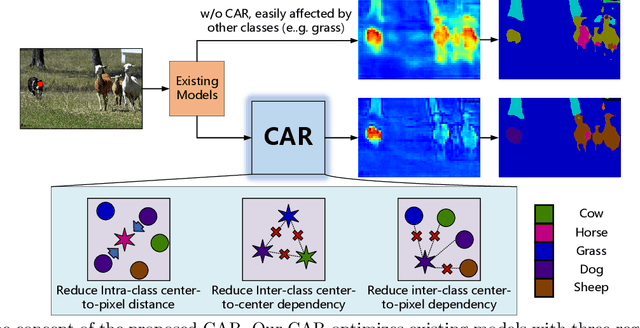
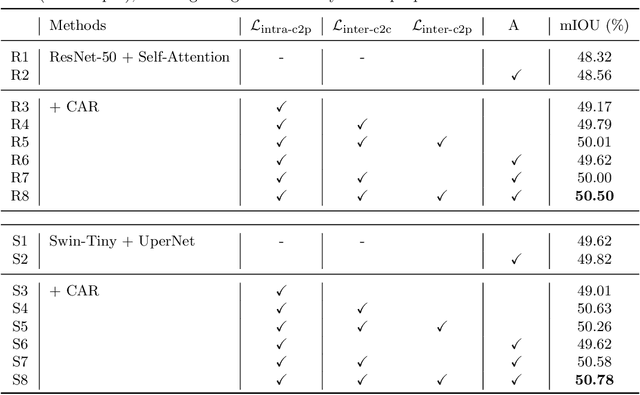
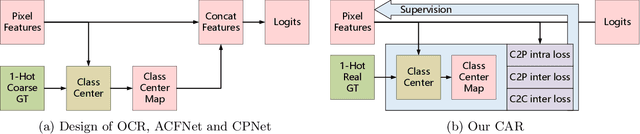
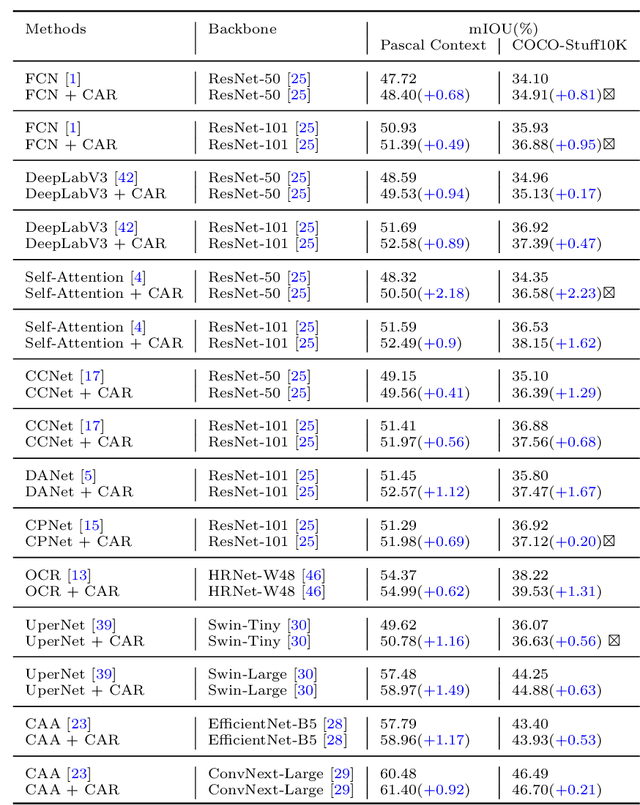
Semantic segmentation has recently achieved notable advances by exploiting "class-level" contextual information during learning. However, these approaches simply concatenate class-level information to pixel features to boost the pixel representation learning, which cannot fully utilize intra-class and inter-class contextual information. Moreover, these approaches learn soft class centers based on coarse mask prediction, which is prone to error accumulation. To better exploit class level information, we propose a universal Class-Aware Regularization (CAR) approach to optimize the intra-class variance and inter-class distance during feature learning, motivated by the fact that humans can recognize an object by itself no matter which other objects it appears with. Moreover, we design a dedicated decoder for CAR (CARD), which consists of a novel spatial token mixer and an upsampling module, to maximize its gain for existing baselines while being highly efficient in terms of computational cost. Specifically, CAR consists of three novel loss functions. The first loss function encourages more compact class representations within each class, the second directly maximizes the distance between different class centers, and the third further pushes the distance between inter-class centers and pixels. Furthermore, the class center in our approach is directly generated from ground truth instead of from the error-prone coarse prediction. CAR can be directly applied to most existing segmentation models during training, and can largely improve their accuracy at no additional inference overhead. Extensive experiments and ablation studies conducted on multiple benchmark datasets demonstrate that the proposed CAR can boost the accuracy of all baseline models by up to 2.23% mIOU with superior generalization ability. CARD outperforms SOTA approaches on multiple benchmarks with a highly efficient architecture.