 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC-OR-Net: A Unified Framework for LTV Prediction through Structural Decoupling
Jan 15, 2026Customer Lifetime Value (LTV) prediction, a central problem in modern marketing, is characterized by a unique zero-inflated and long-tail data distribution. This distribution presents two fundamental challenges: (1) the vast majority of low-to-medium value users numerically overwhelm the small but critically important segment of high-value "whale" users, and (2) significant value heterogeneity exists even within the low-to-medium value user base. Common approaches either rely on rigid statistical assumptions or attempt to decouple ranking and regression using ordered buckets; however, they often enforce ordinality through loss-based constraints rather than inherent architectural design, failing to balance global accuracy with high-value precision. To address this gap, we propose \textbf{C}onditional \textbf{C}ascaded \textbf{O}rdinal-\textbf{R}esidual Networks \textbf{(CC-OR-Net)}, a novel unified framework that achieves a more robust decoupling through \textbf{structural decomposition}, where ranking is architecturally guaranteed. CC-OR-Net integrates three specialized components: a \textit{structural ordinal decomposition module} for robust ranking, an \textit{intra-bucket residual module} for fine-grained regression, and a \textit{targeted high-value augmentation module} for precision on top-tier users. Evaluated on real-world datasets with over 300M users, CC-OR-Net achieves a superior trade-off across all key business metrics, outperforming state-of-the-art methods in creating a holistic and commercially valuable LTV prediction solution.
Vivid-VR: Distilling Concepts from Text-to-Video Diffusion Transformer for Photorealistic Video Restoration
Aug 20, 2025



We present Vivid-VR, a DiT-based generative video restoration method built upon an advanced T2V foundation model, where ControlNet is leveraged to control the generation process, ensuring content consistency. However, conventional fine-tuning of such controllable pipelines frequently suffers from distribution drift due to limitations in imperfect multimodal alignment, resulting in compromised texture realism and temporal coherence. To tackle this challenge, we propose a concept distillation training strategy that utilizes the pretrained T2V model to synthesize training samples with embedded textual concepts, thereby distilling its conceptual understanding to preserve texture and temporal quality. To enhance generation controllability, we redesign the control architecture with two key components: 1) a control feature projector that filters degradation artifacts from input video latents to minimize their propagation through the generation pipeline, and 2) a new ControlNet connector employing a dual-branch design. This connector synergistically combines MLP-based feature mapping with cross-attention mechanism for dynamic control feature retrieval, enabling both content preservation and adaptive control signal modulation. Extensive experiments show that Vivid-VR performs favorably against existing approaches on both synthetic and real-world benchmarks, as well as AIGC videos, achieving impressive texture realism, visual vividness, and temporal consistency. The codes and checkpoints are publicly available at https://github.com/csbhr/Vivid-VR.
FFHQ-UV: Normalized Facial UV-Texture Dataset for 3D Face Reconstruction
Nov 25, 2022



We present a large-scale facial UV-texture dataset that contains over 50,000 high-quality texture UV-maps with even illuminations, neutral expressions, and cleaned facial regions, which are desired characteristics for rendering realistic 3D face models under different lighting conditions. The dataset is derived from a large-scale face image dataset namely FFHQ, with the help of our fully automatic and robust UV-texture production pipeline. Our pipeline utilizes the recent advances in StyleGAN-based facial image editing approaches to generate multi-view normalized face images from single-image inputs. An elaborated UV-texture extraction, correction, and completion procedure is then applied to produce high-quality UV-maps from the normalized face images. Compared with existing UV-texture datasets, our dataset has more diverse and higher-quality texture maps. We further train a GAN-based texture decoder as the nonlinear texture basis for parametric fitting based 3D face reconstruction. Experiments show that our method improves the reconstruction accuracy over state-of-the-art approaches, and more importantly, produces high-quality texture maps that are ready for realistic renderings. The dataset, code, and pre-trained texture decoder are publicly available at https://github.com/csbhr/FFHQ-UV.
Self-Supervised Deep Blind Video Super-Resolution
Jan 19, 2022Existing deep learning-based video super-resolution (SR) methods usually depend on the supervised learning approach, where the training data is usually generated by the blurring operation with known or predefined kernels (e.g., Bicubic kernel) followed by a decimation operation. However, this does not hold for real applications as the degradation process is complex and cannot be approximated by these idea cases well. Moreover, obtaining high-resolution (HR) videos and the corresponding low-resolution (LR) ones in real-world scenarios is difficult. To overcome these problems, we propose a self-supervised learning method to solve the blind video SR problem, which simultaneously estimates blur kernels and HR videos from the LR videos. As directly using LR videos as supervision usually leads to trivial solutions, we develop a simple and effective method to generate auxiliary paired data from original LR videos according to the image formation of video SR, so that the networks can be better constrained by the generated paired data for both blur kernel estimation and latent HR video restoration. In addition, we introduce an optical flow estimation module to exploit the information from adjacent frames for HR video restoration. Experiments show that our method performs favorably against state-of-the-art ones on benchmarks and real-world videos.
Cascaded Deep Video Deblurring Using Temporal Sharpness Prior
Apr 06, 2020
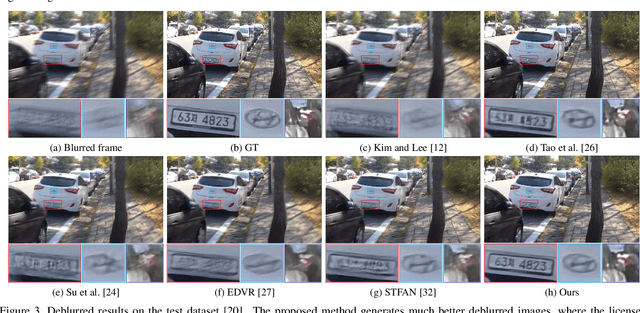


We present a simple and effective deep convolutional neural network (CNN) model for video deblurring. The proposed algorithm mainly consists of optical flow estimation from intermediate latent frames and latent frame restoration steps. It first develops a deep CNN model to estimate optical flow from intermediate latent frames and then restores the latent frames based on the estimated optical flow. To better explore the temporal information from videos, we develop a temporal sharpness prior to constrain the deep CNN model to help the latent frame restoration. We develop an effective cascaded training approach and jointly train the proposed CNN model in an end-to-end manner. We show that exploring the domain knowledge of video deblurring is able to make the deep CNN model more compact and efficient. Extensive experimental results show that the proposed algorithm performs favorably against state-of-the-art methods on the benchmark datasets as well as real-world videos.