 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automatic and Efficient BERT Pruning for Edge AI Systems
Jun 21, 2022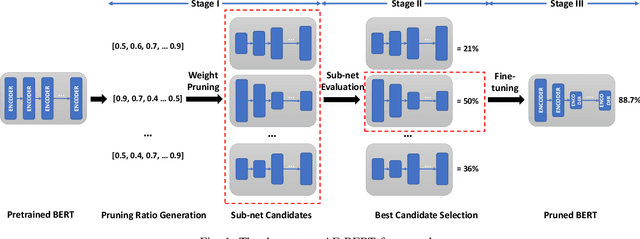
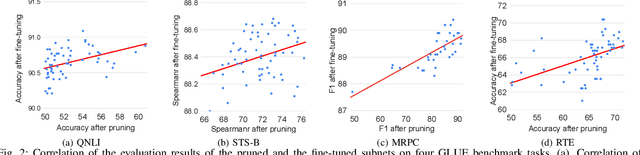
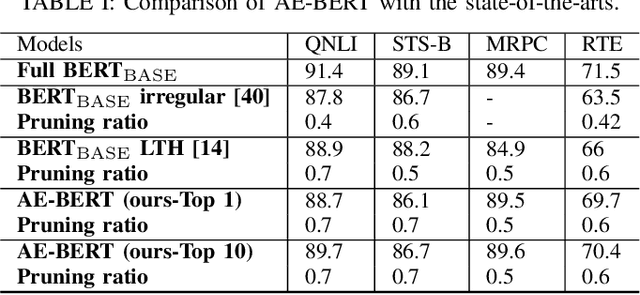
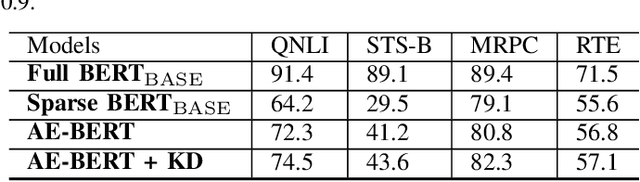
With the yearning for deep learning democratization, there are increasing demands to implement Transformer-based natural language processing (NLP) models on resource-constrained devices for low-latency and high accuracy. Existing BERT pruning methods require domain experts to heuristically handcraft hyperparameters to strike a balance among model size, latency, and accuracy. In this work, we propose AE-BERT, an automatic and efficient BERT pruning framework with efficient evaluation to select a "good" sub-network candidate (with high accuracy) given the overall pruning ratio constraints. Our proposed method requires no human experts experience and achieves a better accuracy performance on many NLP tasks. Our experimental results on General Language Understanding Evaluation (GLUE) benchmark show that AE-BERT outperforms the state-of-the-art (SOTA) hand-crafted pruning methods on BERT$_{\mathrm{BASE}}$. On QNLI and RTE, we obtain 75\% and 42.8\% more overall pruning ratio while achieving higher accuracy. On MRPC, we obtain a 4.6 higher score than the SOTA at the same overall pruning ratio of 0.5. On STS-B, we can achieve a 40\% higher pruning ratio with a very small loss in Spearman correlation compared to SOTA hand-crafted pruning methods. Experimental results also show that after model compression, the inference time of a single BERT$_{\mathrm{BASE}}$ encoder on Xilinx Alveo U200 FPGA board has a 1.83$\times$ speedup compared to Intel(R) Xeon(R) Gold 5218 (2.30GHz) CPU, which shows the reasonableness of deploying the proposed method generated subnets of BERT$_{\mathrm{BASE}}$ model on computation restricted devices.
Detecting Gender Bias in Transformer-based Models: A Case Study on BERT
Oct 15, 2021
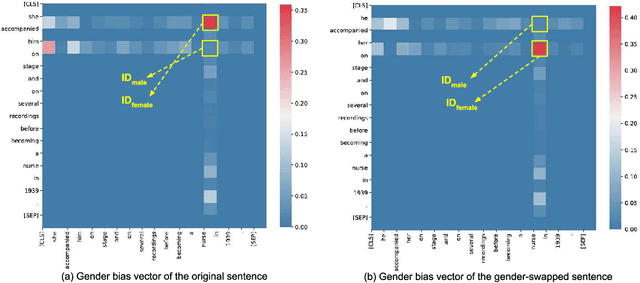
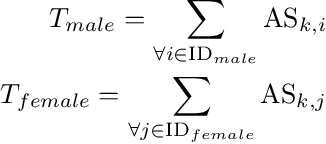
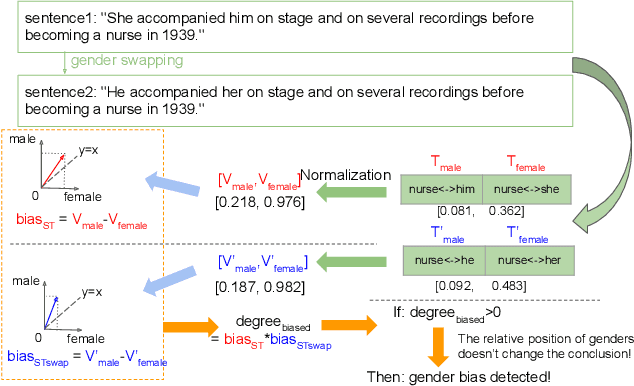
In this paper, we propose a novel gender bias detection method by utilizing attention map for transformer-based models. We 1) give an intuitive gender bias judgement method by comparing the different relation degree between the genders and the occupation according to the attention scores, 2) design a gender bias detector by modifying the attention module, 3) insert the gender bias detector into different positions of the model to present the internal gender bias flow, and 4) draw the consistent gender bias conclusion by scanning the entire Wikipedia, a BERT pretraining dataset. We observe that 1) the attention matrices, Wq and Wk introduce much more gender bias than other modules (including the embedding layer) and 2) the bias degree changes periodically inside of the model (attention matrix Q, K, V, and the remaining part of the attention layer (including the fully-connected layer, the residual connection, and the layer normalization module) enhance the gender bias while the averaged attentions reduces the bias).