 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr. Top-k: Delegate-Centric Top-k on GPUs
Sep 16, 2021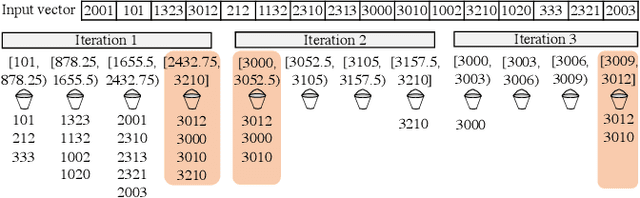


Recent top-$k$ computation efforts explore the possibility of revising various sorting algorithms to answer top-$k$ queries on GPUs. These endeavors, unfortunately, perform significantly more work than needed. This paper introduces Dr. Top-k, a Delegate-centric top-$k$ system on GPUs that can reduce the top-$k$ workloads significantly. Particularly, it contains three major contributions: First, we introduce a comprehensive design of the delegate-centric concept, including maximum delegate, delegate-based filtering, and $\beta$ delegate mechanisms to help reduce the workload for top-$k$ up to more than 99%. Second, due to the difficulty and importance of deriving a proper subrange size, we perform a rigorous theoretical analysis, coupled with thorough experimental validations to identify the desirable subrange size. Third, we introduce four key system optimizations to enable fast multi-GPU top-$k$ computation. Taken together, this work constantly outperforms the state-of-the-art.
Binary Complex Neural Network Acceleration on FPGA
Aug 10, 2021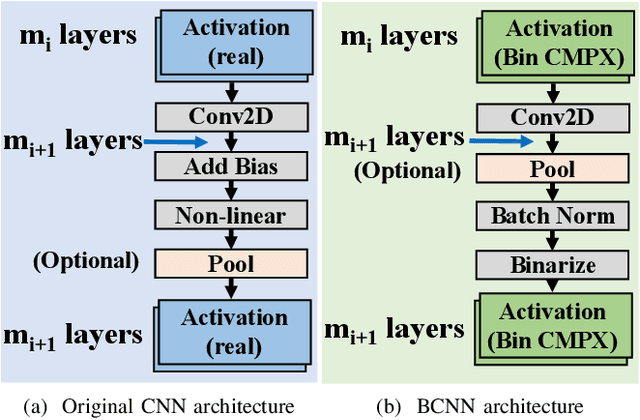
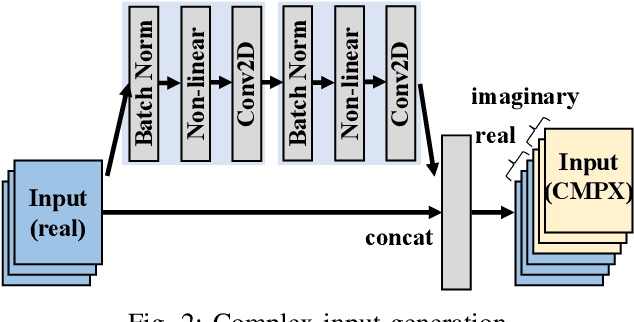

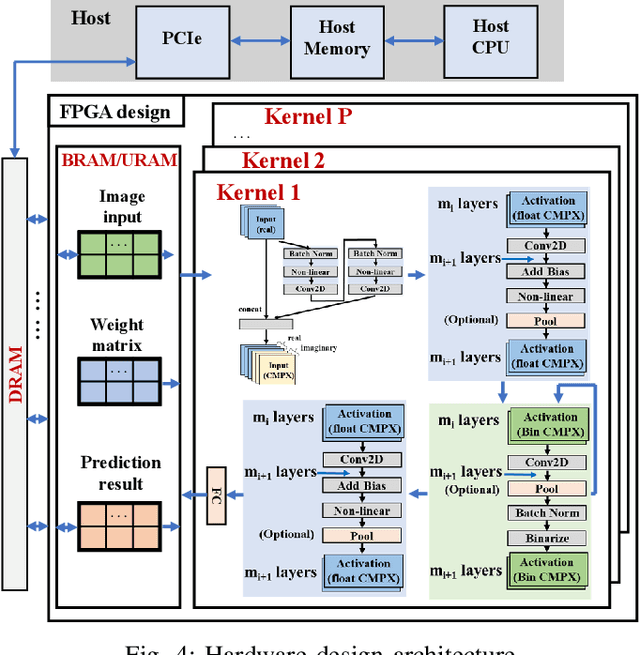
Being able to learn from complex data with phase information is imperative for many signal processing applications. Today' s real-valued deep neural networks (DNNs) have shown efficiency in latent information analysis but fall short when applied to the complex domain. Deep complex networks (DCN), in contrast, can learn from complex data, but have high computational costs; therefore, they cannot satisfy the instant decision-making requirements of many deployable systems dealing with short observations or short signal bursts. Recent, Binarized Complex Neural Network (BCNN), which integrates DCNs with binarized neural networks (BNN), shows great potential in classifying complex data in real-time. In this paper, we propose a structural pruning based accelerator of BCNN, which is able to provide more than 5000 frames/s inference throughput on edge devices. The high performance comes from both the algorithm and hardware sides. On the algorithm side, we conduct structural pruning to the original BCNN models and obtain 20 $\times$ pruning rates with negligible accuracy loss; on the hardware side, we propose a novel 2D convolution operation accelerator for the binary complex neural network. Experimental results show that the proposed design works with over 90% utilization and is able to achieve the inference throughput of 5882 frames/s and 4938 frames/s for complex NIN-Net and ResNet-18 using CIFAR-10 dataset and Alveo U280 Board.