 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr. Top-k: Delegate-Centric Top-k on GPUs
Sep 16, 2021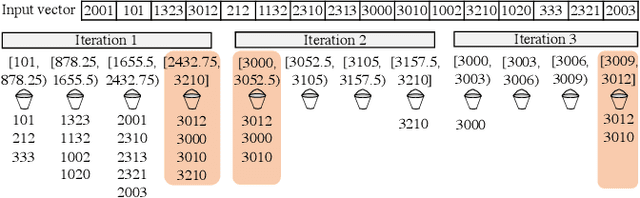


Recent top-$k$ computation efforts explore the possibility of revising various sorting algorithms to answer top-$k$ queries on GPUs. These endeavors, unfortunately, perform significantly more work than needed. This paper introduces Dr. Top-k, a Delegate-centric top-$k$ system on GPUs that can reduce the top-$k$ workloads significantly. Particularly, it contains three major contributions: First, we introduce a comprehensive design of the delegate-centric concept, including maximum delegate, delegate-based filtering, and $\beta$ delegate mechanisms to help reduce the workload for top-$k$ up to more than 99%. Second, due to the difficulty and importance of deriving a proper subrange size, we perform a rigorous theoretical analysis, coupled with thorough experimental validations to identify the desirable subrange size. Third, we introduce four key system optimizations to enable fast multi-GPU top-$k$ computation. Taken together, this work constantly outperforms the state-of-the-art.
EZLDA: Efficient and Scalable LDA on GPUs
Jul 17, 2020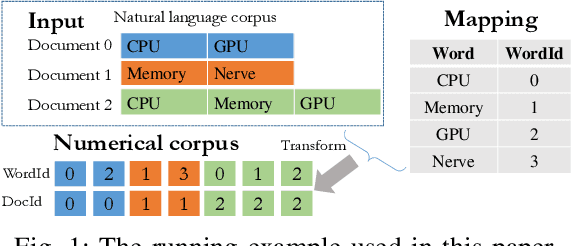
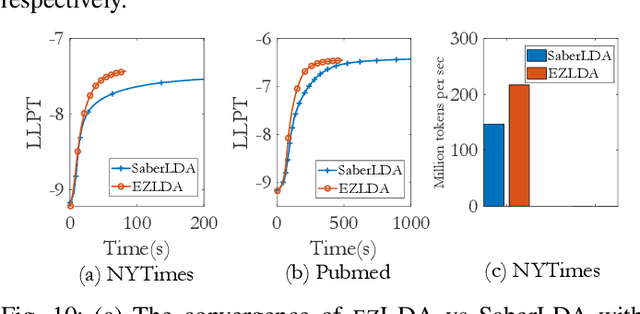
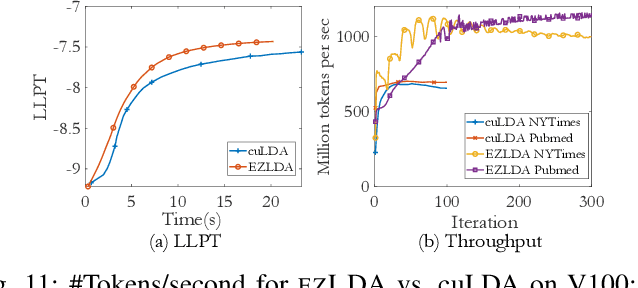
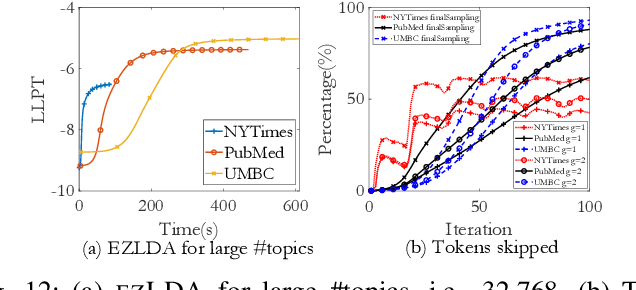
LDA is a statistical approach for topic modeling with a wide range of applications. However, there exist very few attempts to accelerate LDA on GPUs which come with exceptional computing and memory throughput capabilities. To this end, we introduce EZLDA which achieves efficient and scalable LDA training on GPUs with the following three contributions: First, EZLDA introduces three-branch sampling method which takes advantage of the convergence heterogeneity of various tokens to reduce the redundant sampling task. Second, to enable sparsity-aware format for both D and W on GPUs with fast sampling and updating, we introduce hybrid format for W along with corresponding token partition to T and inverted index designs. Third, we design a hierarchical workload balancing solution to address the extremely skewed workload imbalance problem on GPU and scaleEZLDA across multiple GPUs. Taken together, EZLDA achieves superior performance over the state-of-the-art attempts with lower memory consumption.