 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier neural operators for spatiotemporal dynamics in two-dimensional turbulence
Sep 25, 2024High-fidelity direct numerical simulation of turbulent flows for most real-world applications remains an outstanding computational challenge. Several machine learning approaches have recently been proposed to alleviate the computational cost even though they become unstable or unphysical for long time predictions. We identify that the Fourier neural operator (FNO) based models combined with a partial differential equation (PDE) solver can accelerate fluid dynamic simulations and thus address computational expense of large-scale turbulence simulations. We treat the FNO model on the same footing as a PDE solver and answer important questions about the volume and temporal resolution of data required to build pre-trained models for turbulence. We also discuss the pitfalls of purely data-driven approaches that need to be avoided by the machine learning models to become viable and competitive tools for long time simulations of turbulence.
Learning Independent Program and Architecture Representations for Generalizable Performance Modeling
Oct 25, 2023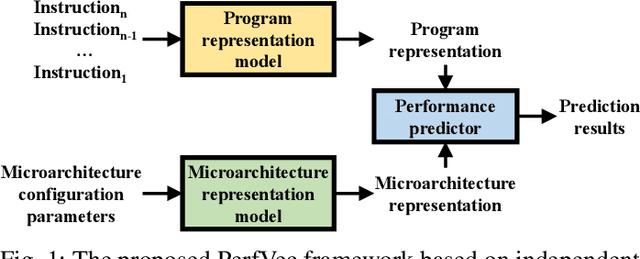
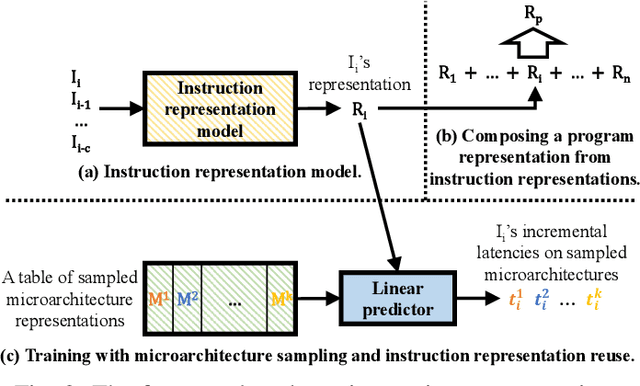
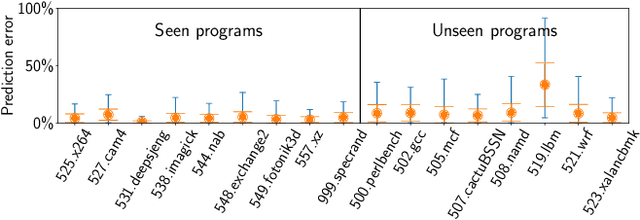
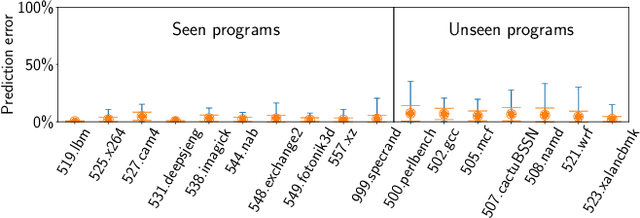
This paper proposes PerfVec, a novel deep learning-based performance modeling framework that learns high-dimensional, independent/orthogonal program and microarchitecture representations. Once learned, a program representation can be used to predict its performance on any microarchitecture, and likewise, a microarchitecture representation can be applied in the performance prediction of any program. Additionally, PerfVec yields a foundation model that captures the performance essence of instructions, which can be directly used by developers in numerous performance modeling related tasks without incurring its training cost. The evaluation demonstrates that PerfVec is more general, efficient, and accurate than previous approaches.
Dr. Top-k: Delegate-Centric Top-k on GPUs
Sep 16, 2021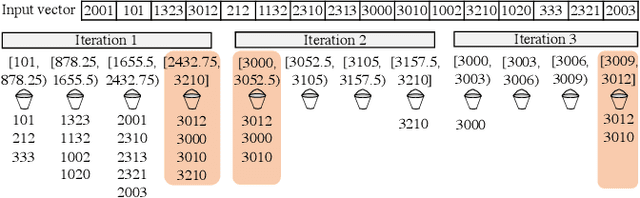


Recent top-$k$ computation efforts explore the possibility of revising various sorting algorithms to answer top-$k$ queries on GPUs. These endeavors, unfortunately, perform significantly more work than needed. This paper introduces Dr. Top-k, a Delegate-centric top-$k$ system on GPUs that can reduce the top-$k$ workloads significantly. Particularly, it contains three major contributions: First, we introduce a comprehensive design of the delegate-centric concept, including maximum delegate, delegate-based filtering, and $\beta$ delegate mechanisms to help reduce the workload for top-$k$ up to more than 99%. Second, due to the difficulty and importance of deriving a proper subrange size, we perform a rigorous theoretical analysis, coupled with thorough experimental validations to identify the desirable subrange size. Third, we introduce four key system optimizations to enable fast multi-GPU top-$k$ computation. Taken together, this work constantly outperforms the state-of-the-art.
SimNet: Computer Architecture Simulation using Machine Learning
May 12, 2021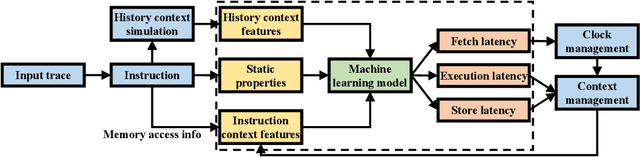

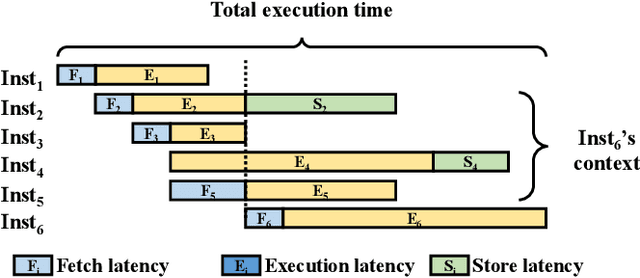
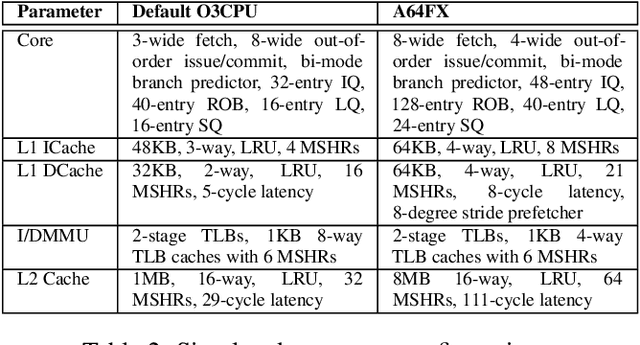
While cycle-accurate simulators are essential tools for architecture research, design, and development, their practicality is limited by an extremely long time-to-solution for realistic problems under investigation. This work describes a concerted effort, where machine learning (ML) is used to accelerate discrete-event simulation. First, an ML-based instruction latency prediction framework that accounts for both static instruction/architecture properties and dynamic execution context is constructed. Then, a GPU-accelerated parallel simulator is implemented based on the proposed instruction latency predictor, and its simulation accuracy and throughput are validated and evaluated against a state-of-the-art simulator. Leveraging modern GPUs, the ML-based simulator outperforms traditional simulators significantly.