 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Decoding of Stabilizer Codes under Radiation-Induced Correlated Noise
Mar 18, 2026Fault-tolerant quantum computation demands extremely low logical error rates, yet superconducting qubit arrays are subject to radiation-induced correlated noise arising from cosmic-ray muon-generated quasiparticles. The quasiparticle density is unknown and time-varying, resulting in a mismatch between the true noise statistics and the priors assumed by standard decoders, and consequently, degraded logical performance. We formalize joint noise sensing and decoding using syndrome measurements by modeling the QP density as a latent variable, which governs correlation in physical errors and syndrome measurements. Starting from a variational expectation--maximization approach, we derive an iterative algorithm that alternates between QP density estimation and syndrome-based decoding under the updated noise model. Simulations of surface-code and bivariate bicycle quantum memory under radiation-induced correlated noise demonstrate a measurable reduction in logical error probability relative to baseline decoding with a uniform prior. Beyond improved decoding performance, the inferred QP density provides diagnostic information relevant to device characterization, shielding, and chip design. These results indicate that integrating physical noise estimation into decoding can mitigate correlated noise effects and relax effective error-rate requirements for fault-tolerant quantum computation.
Towards an Introspective Dynamic Model of Globally Distributed Computing Infrastructures
Jun 24, 2025Large-scale scientific collaborations like ATLAS, Belle II, CMS, DUNE, and others involve hundreds of research institutes and thousands of researchers spread across the globe. These experiments generate petabytes of data, with volumes soon expected to reach exabytes. Consequently, there is a growing need for computation, including structured data processing from raw data to consumer-ready derived data, extensive Monte Carlo simulation campaigns, and a wide range of end-user analysis. To manage these computational and storage demands, centralized workflow and data management systems are implemented. However, decisions regarding data placement and payload allocation are often made disjointly and via heuristic means. A significant obstacle in adopting more effective heuristic or AI-driven solutions is the absence of a quick and reliable introspective dynamic model to evaluate and refine alternative approaches. In this study, we aim to develop such an interactive system using real-world data. By examining job execution records from the PanDA workflow management system, we have pinpointed key performance indicators such as queuing time, error rate, and the extent of remote data access. The dataset includes five months of activity. Additionally, we are creating a generative AI model to simulate time series of payloads, which incorporate visible features like category, event count, and submitting group, as well as hidden features like the total computational load-derived from existing PanDA records and computing site capabilities. These hidden features, which are not visible to job allocators, whether heuristic or AI-driven, influence factors such as queuing times and data movement.
Enhancing Future Link Prediction in Quantum Computing Semantic Networks through LLM-Initiated Node Features
Oct 05, 2024



Quantum computing is rapidly evolving in both physics and computer science, offering the potential to solve complex problems and accelerate computational processes. The development of quantum chips necessitates understanding the correlations among diverse experimental conditions. Semantic networks built on scientific literature, representing meaningful relationships between concepts, have been used across various domains to identify knowledge gaps and novel concept combinations. Neural network-based approaches have shown promise in link prediction within these networks. This study proposes initializing node features using LLMs to enhance node representations for link prediction tasks in graph neural networks. LLMs can provide rich descriptions, reducing the need for manual feature creation and lowering costs. Our method, evaluated using various link prediction models on a quantum computing semantic network, demonstrated efficacy compared to traditional node embedding techniques.
Learning Independent Program and Architecture Representations for Generalizable Performance Modeling
Oct 25, 2023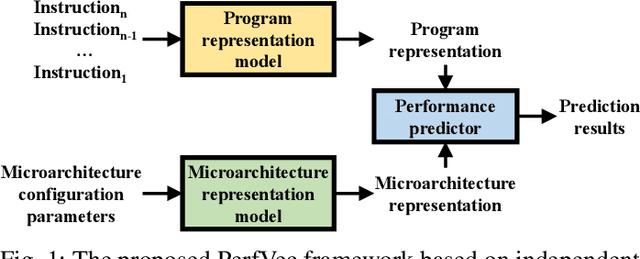
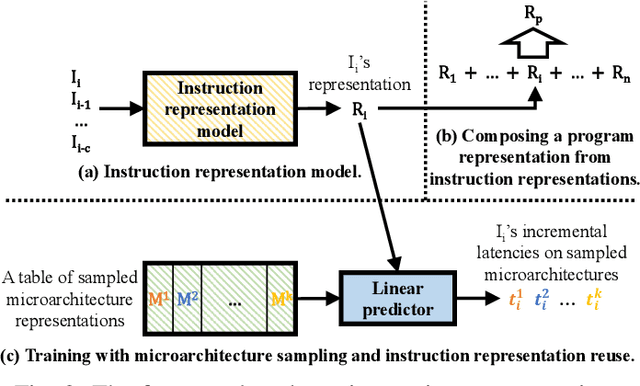
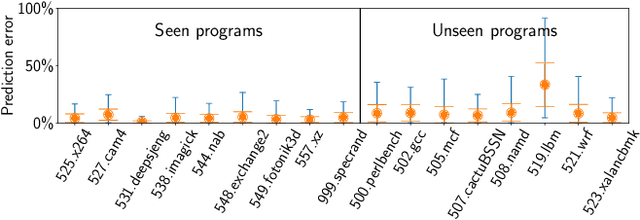
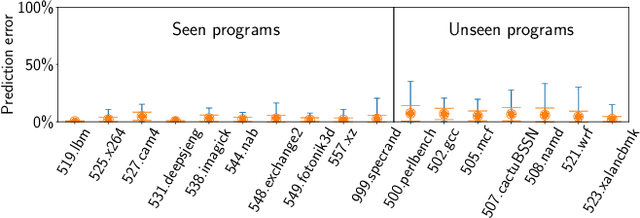
This paper proposes PerfVec, a novel deep learning-based performance modeling framework that learns high-dimensional, independent/orthogonal program and microarchitecture representations. Once learned, a program representation can be used to predict its performance on any microarchitecture, and likewise, a microarchitecture representation can be applied in the performance prediction of any program. Additionally, PerfVec yields a foundation model that captures the performance essence of instructions, which can be directly used by developers in numerous performance modeling related tasks without incurring its training cost. The evaluation demonstrates that PerfVec is more general, efficient, and accurate than previous approaches.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
SimNet: Computer Architecture Simulation using Machine Learning
May 12, 2021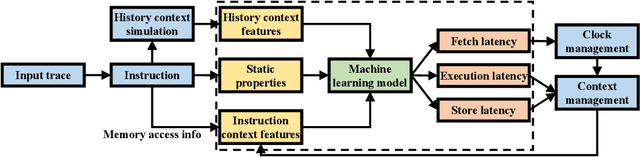

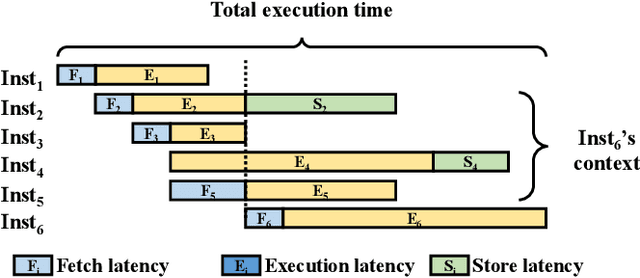
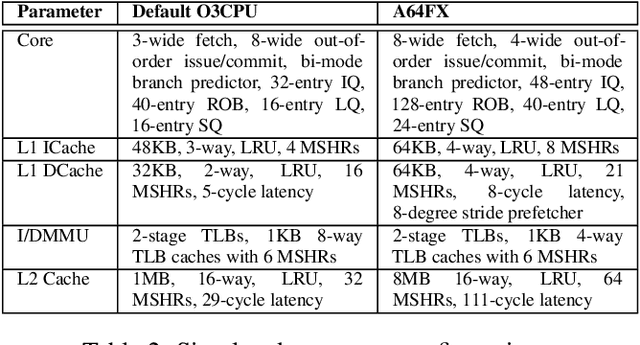
While cycle-accurate simulators are essential tools for architecture research, design, and development, their practicality is limited by an extremely long time-to-solution for realistic problems under investigation. This work describes a concerted effort, where machine learning (ML) is used to accelerate discrete-event simulation. First, an ML-based instruction latency prediction framework that accounts for both static instruction/architecture properties and dynamic execution context is constructed. Then, a GPU-accelerated parallel simulator is implemented based on the proposed instruction latency predictor, and its simulation accuracy and throughput are validated and evaluated against a state-of-the-art simulator. Leveraging modern GPUs, the ML-based simulator outperforms traditional simulators significantly.
Performance Analysis of Deep Learning Workloads on Leading-edge Systems
May 21, 2019



This work examines the performance of leading-edge systems designed for machine learning computing, including the NVIDIA DGX-2, Amazon Web Services (AWS) P3, IBM Power System Accelerated Compute Server AC922, and a consumer-grade Exxact TensorEX TS4 GPU server. Representative deep learning workloads from the fields of computer vision and natural language processing are the focus of the analysis. Performance analysis is performed along with a number of important dimensions. Performance of the communication interconnects and large and high-throughput deep learning models are considered. Different potential use models for the systems as standalone and in the cloud also are examined. The effect of various optimization of the deep learning models and system configurations is included in the analysis.
Fast Support Vector Machines Using Parallel Adaptive Shrinking on Distributed Systems
Jun 19, 2014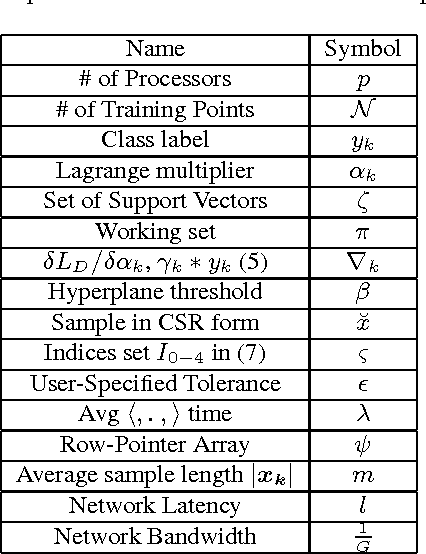
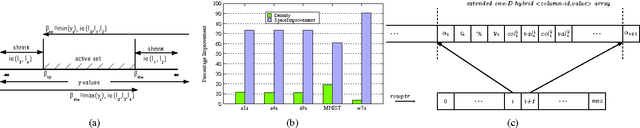
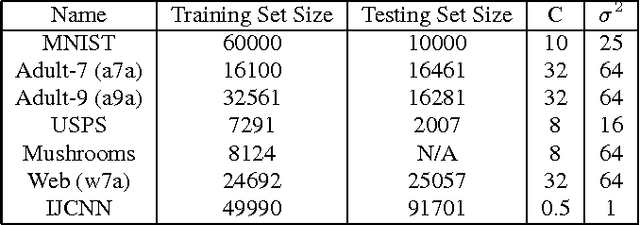
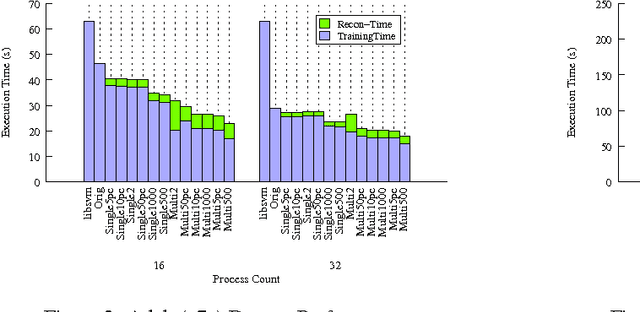
Support Vector Machines (SVM), a popular machine learning technique, has been applied to a wide range of domains such as science, finance, and social networks for supervised learning. Whether it is identifying high-risk patients by health-care professionals, or potential high-school students to enroll in college by school districts, SVMs can play a major role for social good. This paper undertakes the challenge of designing a scalable parallel SVM training algorithm for large scale systems, which includes commodity multi-core machines, tightly connected supercomputers and cloud computing systems. Intuitive techniques for improving the time-space complexity including adaptive elimination of samples for faster convergence and sparse format representation are proposed. Under sample elimination, several heuristics for {\em earliest possible} to {\em lazy} elimination of non-contributing samples are proposed. In several cases, where an early sample elimination might result in a false positive, low overhead mechanisms for reconstruction of key data structures are proposed. The algorithm and heuristics are implemented and evaluated on various publicly available datasets. Empirical evaluation shows up to 26x speed improvement on some datasets against the sequential baseline, when evaluated on multiple compute nodes, and an improvement in execution time up to 30-60\% is readily observed on a number of other datasets against our parallel baseline.