 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Support Vector Machines Using Parallel Adaptive Shrinking on Distributed Systems
Jun 19, 2014
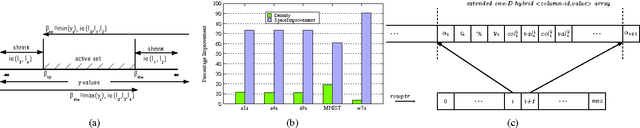
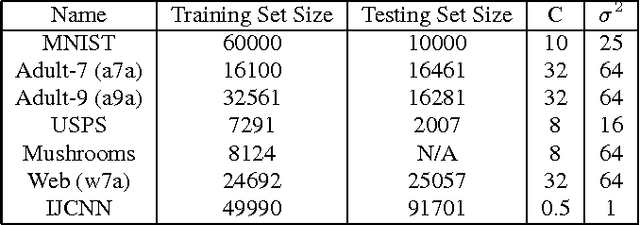
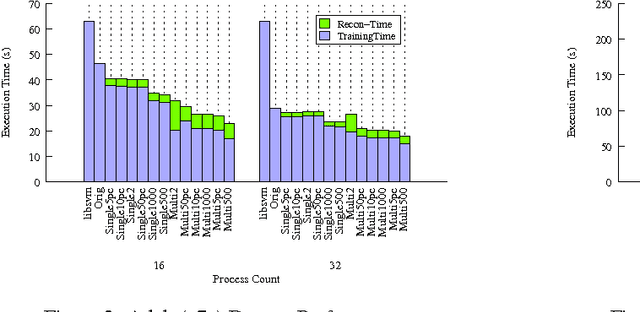
Support Vector Machines (SVM), a popular machine learning technique, has been applied to a wide range of domains such as science, finance, and social networks for supervised learning. Whether it is identifying high-risk patients by health-care professionals, or potential high-school students to enroll in college by school districts, SVMs can play a major role for social good. This paper undertakes the challenge of designing a scalable parallel SVM training algorithm for large scale systems, which includes commodity multi-core machines, tightly connected supercomputers and cloud computing systems. Intuitive techniques for improving the time-space complexity including adaptive elimination of samples for faster convergence and sparse format representation are proposed. Under sample elimination, several heuristics for {\em earliest possible} to {\em lazy} elimination of non-contributing samples are proposed. In several cases, where an early sample elimination might result in a false positive, low overhead mechanisms for reconstruction of key data structures are proposed. The algorithm and heuristics are implemented and evaluated on various publicly available datasets. Empirical evaluation shows up to 26x speed improvement on some datasets against the sequential baseline, when evaluated on multiple compute nodes, and an improvement in execution time up to 30-60\% is readily observed on a number of other datasets against our parallel baseline.