 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Introspective Dynamic Model of Globally Distributed Computing Infrastructures
Jun 24, 2025Large-scale scientific collaborations like ATLAS, Belle II, CMS, DUNE, and others involve hundreds of research institutes and thousands of researchers spread across the globe. These experiments generate petabytes of data, with volumes soon expected to reach exabytes. Consequently, there is a growing need for computation, including structured data processing from raw data to consumer-ready derived data, extensive Monte Carlo simulation campaigns, and a wide range of end-user analysis. To manage these computational and storage demands, centralized workflow and data management systems are implemented. However, decisions regarding data placement and payload allocation are often made disjointly and via heuristic means. A significant obstacle in adopting more effective heuristic or AI-driven solutions is the absence of a quick and reliable introspective dynamic model to evaluate and refine alternative approaches. In this study, we aim to develop such an interactive system using real-world data. By examining job execution records from the PanDA workflow management system, we have pinpointed key performance indicators such as queuing time, error rate, and the extent of remote data access. The dataset includes five months of activity. Additionally, we are creating a generative AI model to simulate time series of payloads, which incorporate visible features like category, event count, and submitting group, as well as hidden features like the total computational load-derived from existing PanDA records and computing site capabilities. These hidden features, which are not visible to job allocators, whether heuristic or AI-driven, influence factors such as queuing times and data movement.
Mixed Delay/Nondelay Embeddings Based Neuromorphic Computing with Patterned Nanomagnet Arrays
Dec 05, 2024Patterned nanomagnet arrays (PNAs) have been shown to exhibit a strong geometrically frustrated dipole interaction. Some PNAs have also shown emergent domain wall dynamics. Previous works have demonstrated methods to physically probe these magnetization dynamics of PNAs to realize neuromorphic reservoir systems that exhibit chaotic dynamical behavior and high-dimensional nonlinearity. These PNA reservoir systems from prior works leverage echo state properties and linear/nonlinear short-term memory of component reservoir nodes to map and preserve the dynamical information of the input time-series data into nondelay spatial embeddings. Such mappings enable these PNA reservoir systems to imitate and predict/forecast the input time series data. However, these prior PNA reservoir systems are based solely on the nondelay spatial embeddings obtained at component reservoir nodes. As a result, they require a massive number of component reservoir nodes, or a very large spatial embedding (i.e., high-dimensional spatial embedding) per reservoir node, or both, to achieve acceptable imitation and prediction accuracy. These requirements reduce the practical feasibility of such PNA reservoir systems. To address this shortcoming, we present a mixed delay/nondelay embeddings-based PNA reservoir system. Our system uses a single PNA reservoir node with the ability to obtain a mixture of delay/nondelay embeddings of the dynamical information of the time-series data applied at the input of a single PNA reservoir node. Our analysis shows that when these mixed delay/nondelay embeddings are used to train a perceptron at the output layer, our reservoir system outperforms existing PNA-based reservoir systems for the imitation of NARMA 2, NARMA 5, NARMA 7, and NARMA 10 time series data, and for the short-term and long-term prediction of the Mackey Glass time series data.
HEANA: A Hybrid Time-Amplitude Analog Optical Accelerator with Flexible Dataflows for Energy-Efficient CNN Inference
Feb 09, 2024



Several photonic microring resonators (MRRs) based analog accelerators have been proposed to accelerate the inference of integer-quantized CNNs with remarkably higher throughput and energy efficiency compared to their electronic counterparts. However, the existing analog photonic accelerators suffer from three shortcomings: (i) severe hampering of wavelength parallelism due to various crosstalk effects, (ii) inflexibility of supporting various dataflows other than the weight-stationary dataflow, and (iii) failure in fully leveraging the ability of photodetectors to perform in-situ accumulations. These shortcomings collectively hamper the performance and energy efficiency of prior accelerators. To tackle these shortcomings, we present a novel Hybrid timE Amplitude aNalog optical Accelerator, called HEANA. HEANA employs hybrid time-amplitude analog optical multipliers (TAOMs) that increase the flexibility of HEANA to support multiple dataflows. A spectrally hitless arrangement of TAOMs significantly reduces the crosstalk effects, thereby increasing the wavelength parallelism in HEANA. Moreover, HEANA employs our invented balanced photo-charge accumulators (BPCAs) that enable buffer-less, in-situ, temporal accumulations to eliminate the need to use reduction networks in HEANA, relieving it from related latency and energy overheads. Our evaluation for the inference of four modern CNNs indicates that HEANA provides improvements of atleast 66x and 84x in frames-per-second (FPS) and FPS/W (energy-efficiency), respectively, for equal-area comparisons, on gmean over two MRR-based analog CNN accelerators from prior work.
A Comparative Analysis of Microrings Based Incoherent Photonic GEMM Accelerators
Feb 07, 2024



Several microring resonator (MRR) based analog photonic architectures have been proposed to accelerate general matrix-matrix multiplications (GEMMs) in deep neural networks with exceptional throughput and energy efficiency. To implement GEMM functions, these MRR-based architectures, in general, manipulate optical signals in five different ways: (i) Splitting (copying) of multiple optical signals to achieve a certain fan-out, (ii) Aggregation (multiplexing) of multiple optical signals to achieve a certain fan-in, (iii) Modulation of optical signals to imprint input values onto analog signal amplitude, (iv) Weighting of modulated optical signals to achieve analog input-weight multiplication, (v) Summation of optical signals. The MRR-based GEMM accelerators undertake the first four ways of signal manipulation in an arbitrary order ignoring the possible impact of the order of these manipulations on their performance. In this paper, we conduct a detailed analysis of accelerator organizations with three different orders of these manipulations: (1) Modulation-Aggregation-Splitting-Weighting (MASW), (2) Aggregation-Splitting-Modulation-Weighting (ASMW), and (3) Splitting-Modulation-Weighting-Aggregation (SMWA). We show that these organizations affect the crosstalk noise and optical signal losses in different magnitudes, which renders these organizations with different levels of processing parallelism at the circuit level, and different magnitudes of throughput and energy-area efficiency at the system level. Our evaluation results for four CNN models show that SMWA organization achieves up to 4.4$\times$, 5$\times$, and 5.2$\times$ better throughput, energy efficiency, and area-energy efficiency, respectively, compared to ASMW and MASW organizations on average.
High-Speed and Energy-Efficient Non-Binary Computing with Polymorphic Electro-Optic Circuits and Architectures
Apr 15, 2023



In this paper, we present microring resonator (MRR) based polymorphic E-O circuits and architectures that can be employed for high-speed and energy-efficient non-binary reconfigurable computing. Our polymorphic E-O circuits can be dynamically programmed to implement different logic and arithmetic functions at different times. They can provide compactness and polymorphism to consequently improve operand handling, reduce idle time, and increase amortization of area and static power overheads. When combined with flexible photodetectors with the innate ability to accumulate a high number of optical pulses in situ, our circuits can support energy-efficient processing of data in non-binary formats such as stochastic/unary and high-dimensional reservoir formats. Furthermore, our polymorphic E-O circuits enable configurable E-O computing accelerator architectures for processing binarized and integer quantized convolutional neural networks (CNNs). We compare our designed polymorphic E-O circuits and architectures to several circuits and architectures from prior works in terms of area, latency, and energy consumption.
SCONNA: A Stochastic Computing Based Optical Accelerator for Ultra-Fast, Energy-Efficient Inference of Integer-Quantized CNNs
Feb 14, 2023



The acceleration of a CNN inference task uses convolution operations that are typically transformed into vector-dot-product (VDP) operations. Several photonic microring resonators (MRRs) based hardware architectures have been proposed to accelerate integer-quantized CNNs with remarkably higher throughput and energy efficiency compared to their electronic counterparts. However, the existing photonic MRR-based analog accelerators exhibit a very strong trade-off between the achievable input/weight precision and VDP operation size, which severely restricts their achievable VDP operation size for the quantized input/weight precision of 4 bits and higher. The restricted VDP operation size ultimately suppresses computing throughput to severely diminish the achievable performance benefits. To address this shortcoming, we for the first time present a merger of stochastic computing and MRR-based CNN accelerators. To leverage the innate precision flexibility of stochastic computing, we invent an MRR-based optical stochastic multiplier (OSM). We employ multiple OSMs in a cascaded manner using dense wavelength division multiplexing, to forge a novel Stochastic Computing based Optical Neural Network Accelerator (SCONNA). SCONNA achieves significantly high throughput and energy efficiency for accelerating inferences of high-precision quantized CNNs. Our evaluation for the inference of four modern CNNs at 8-bit input/weight precision indicates that SCONNA provides improvements of up to 66.5x, 90x, and 91x in frames-per-second (FPS), FPS/W and FPS/W/mm2, respectively, on average over two photonic MRR-based analog CNN accelerators from prior work, with Top-1 accuracy drop of only up to 0.4% for large CNNs and up to 1.5% for small CNNs. We developed a transaction-level, event-driven python-based simulator for the evaluation of SCONNA and other accelerators (https://github.com/uky-UCAT/SC_ONN_SIM.git).
A Bit-Parallel Deterministic Stochastic Multiplier
Feb 14, 2023
This paper presents a novel bit-parallel deterministic stochastic multiplier, which improves the area-energy-latency product by up to 10.6$\times$10$^4$, while improving the computational error by 32.2\%, compared to three prior stochastic multipliers.
An Optical XNOR-Bitcount Based Accelerator for Efficient Inference of Binary Neural Networks
Feb 03, 2023



Binary Neural Networks (BNNs) are increasingly preferred over full-precision Convolutional Neural Networks(CNNs) to reduce the memory and computational requirements of inference processing with minimal accuracy drop. BNNs convert CNN model parameters to 1-bit precision, allowing inference of BNNs to be processed with simple XNOR and bitcount operations. This makes BNNs amenable to hardware acceleration. Several photonic integrated circuits (PICs) based BNN accelerators have been proposed. Although these accelerators provide remarkably higher throughput and energy efficiency than their electronic counterparts, the utilized XNOR and bitcount circuits in these accelerators need to be further enhanced to improve their area, energy efficiency, and throughput. This paper aims to fulfill this need. For that, we invent a single-MRR-based optical XNOR gate (OXG). Moreover, we present a novel design of bitcount circuit which we refer to as Photo-Charge Accumulator (PCA). We employ multiple OXGs in a cascaded manner using dense wavelength division multiplexing (DWDM) and connect them to the PCA, to forge a novel Optical XNOR-Bitcount based Binary Neural Network Accelerator (OXBNN). Our evaluation for the inference of four modern BNNs indicates that OXBNN provides improvements of up to 62x and 7.6x in frames-per-second (FPS) and FPS/W (energy efficiency), respectively, on geometric mean over two PIC-based BNN accelerators from prior work. We developed a transaction-level, event-driven python-based simulator for evaluation of accelerators (https://github.com/uky-UCAT/B_ONN_SIM).
Photonic Reconfigurable Accelerators for Efficient Inference of CNNs with Mixed-Sized Tensors
Jul 12, 2022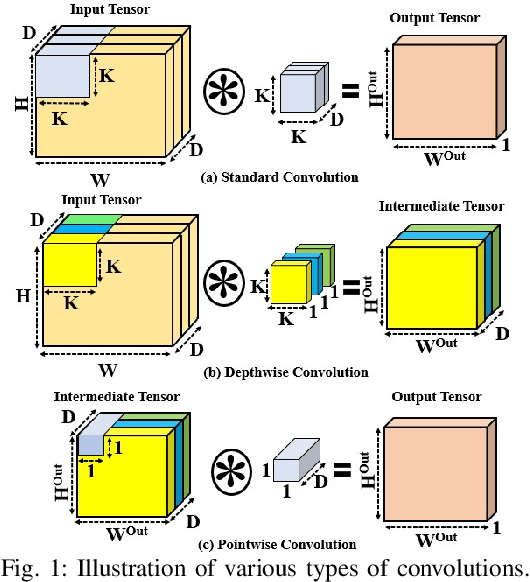
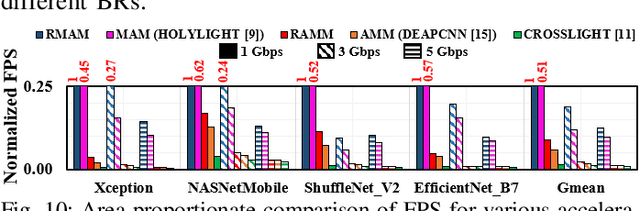
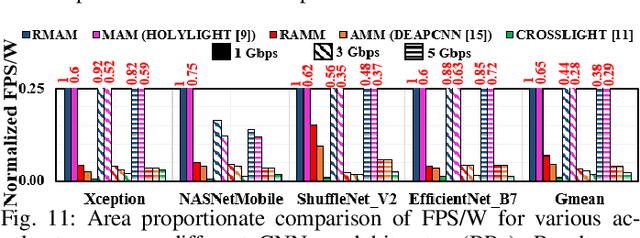

Photonic Microring Resonator (MRR) based hardware accelerators have been shown to provide disruptive speedup and energy-efficiency improvements for processing deep Convolutional Neural Networks (CNNs). However, previous MRR-based CNN accelerators fail to provide efficient adaptability for CNNs with mixed-sized tensors. One example of such CNNs is depthwise separable CNNs. Performing inferences of CNNs with mixed-sized tensors on such inflexible accelerators often leads to low hardware utilization, which diminishes the achievable performance and energy efficiency from the accelerators. In this paper, we present a novel way of introducing reconfigurability in the MRR-based CNN accelerators, to enable dynamic maximization of the size compatibility between the accelerator hardware components and the CNN tensors that are processed using the hardware components. We classify the state-of-the-art MRR-based CNN accelerators from prior works into two categories, based on the layout and relative placements of the utilized hardware components in the accelerators. We then use our method to introduce reconfigurability in accelerators from these two classes, to consequently improve their parallelism, the flexibility of efficiently mapping tensors of different sizes, speed, and overall energy efficiency. We evaluate our reconfigurable accelerators against three prior works for the area proportionate outlook (equal hardware area for all accelerators). Our evaluation for the inference of four modern CNNs indicates that our designed reconfigurable CNN accelerators provide improvements of up to 1.8x in Frames-Per-Second (FPS) and up to 1.5x in FPS/W, compared to an MRR-based accelerator from prior work.
Silicon Photonic Microring Based Chip-Scale Accelerator for Delayed Feedback Reservoir Computing
Jan 03, 2021



To perform temporal and sequential machine learning tasks, the use of conventional Recurrent Neural Networks (RNNs) has been dwindling due to the training complexities of RNNs. To this end, accelerators for delayed feedback reservoir computing (DFRC) have attracted attention in lieu of RNNs, due to their simple hardware implementations. A typical implementation of a DFRC accelerator consists of a delay loop and a single nonlinear neuron, together acting as multiple virtual nodes for computing. In prior work, photonic DFRC accelerators have shown an undisputed advantage of fast computation over their electronic counterparts. In this paper, we propose a more energy-efficient chip-scale DFRC accelerator that employs a silicon photonic microring (MR) based nonlinear neuron along with on-chip photonic waveguides-based delayed feedback loop. Our evaluations show that, compared to a well-known photonic DFRC accelerator from prior work, our proposed MR-based DFRC accelerator achieves 35% and 98.7% lower normalized root mean square error (NRMSE), respectively, for the prediction tasks of NARMA10 and Santa Fe time series. In addition, our MR-based DFRC accelerator achieves 58.8% lower symbol error rate (SER) for the Non-Linear Channel Equalization task. Moreover, our MR-based DFRC accelerator has 98% and 93% faster training time, respectively, compared to an electronic and a photonic DFRC accelerators from prior work.