 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Delay/Nondelay Embeddings Based Neuromorphic Computing with Patterned Nanomagnet Arrays
Dec 05, 2024Patterned nanomagnet arrays (PNAs) have been shown to exhibit a strong geometrically frustrated dipole interaction. Some PNAs have also shown emergent domain wall dynamics. Previous works have demonstrated methods to physically probe these magnetization dynamics of PNAs to realize neuromorphic reservoir systems that exhibit chaotic dynamical behavior and high-dimensional nonlinearity. These PNA reservoir systems from prior works leverage echo state properties and linear/nonlinear short-term memory of component reservoir nodes to map and preserve the dynamical information of the input time-series data into nondelay spatial embeddings. Such mappings enable these PNA reservoir systems to imitate and predict/forecast the input time series data. However, these prior PNA reservoir systems are based solely on the nondelay spatial embeddings obtained at component reservoir nodes. As a result, they require a massive number of component reservoir nodes, or a very large spatial embedding (i.e., high-dimensional spatial embedding) per reservoir node, or both, to achieve acceptable imitation and prediction accuracy. These requirements reduce the practical feasibility of such PNA reservoir systems. To address this shortcoming, we present a mixed delay/nondelay embeddings-based PNA reservoir system. Our system uses a single PNA reservoir node with the ability to obtain a mixture of delay/nondelay embeddings of the dynamical information of the time-series data applied at the input of a single PNA reservoir node. Our analysis shows that when these mixed delay/nondelay embeddings are used to train a perceptron at the output layer, our reservoir system outperforms existing PNA-based reservoir systems for the imitation of NARMA 2, NARMA 5, NARMA 7, and NARMA 10 time series data, and for the short-term and long-term prediction of the Mackey Glass time series data.
Photonic Reconfigurable Accelerators for Efficient Inference of CNNs with Mixed-Sized Tensors
Jul 12, 2022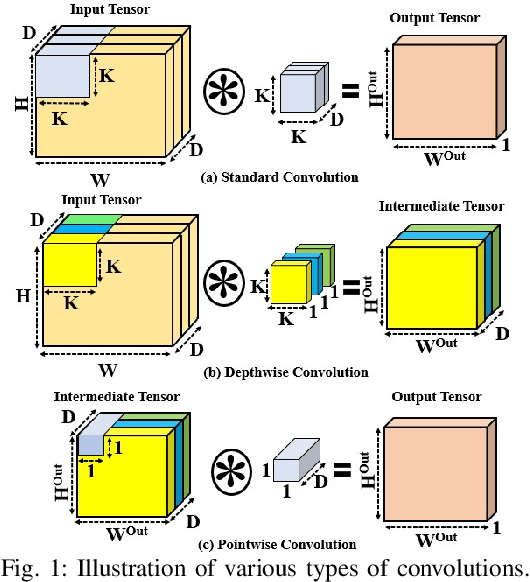
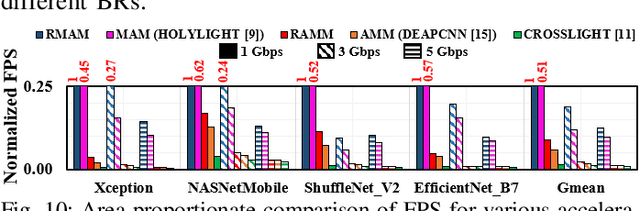
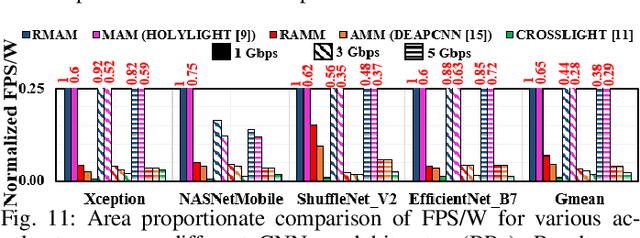

Photonic Microring Resonator (MRR) based hardware accelerators have been shown to provide disruptive speedup and energy-efficiency improvements for processing deep Convolutional Neural Networks (CNNs). However, previous MRR-based CNN accelerators fail to provide efficient adaptability for CNNs with mixed-sized tensors. One example of such CNNs is depthwise separable CNNs. Performing inferences of CNNs with mixed-sized tensors on such inflexible accelerators often leads to low hardware utilization, which diminishes the achievable performance and energy efficiency from the accelerators. In this paper, we present a novel way of introducing reconfigurability in the MRR-based CNN accelerators, to enable dynamic maximization of the size compatibility between the accelerator hardware components and the CNN tensors that are processed using the hardware components. We classify the state-of-the-art MRR-based CNN accelerators from prior works into two categories, based on the layout and relative placements of the utilized hardware components in the accelerators. We then use our method to introduce reconfigurability in accelerators from these two classes, to consequently improve their parallelism, the flexibility of efficiently mapping tensors of different sizes, speed, and overall energy efficiency. We evaluate our reconfigurable accelerators against three prior works for the area proportionate outlook (equal hardware area for all accelerators). Our evaluation for the inference of four modern CNNs indicates that our designed reconfigurable CNN accelerators provide improvements of up to 1.8x in Frames-Per-Second (FPS) and up to 1.5x in FPS/W, compared to an MRR-based accelerator from prior work.