 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Progressive Distillation: Resolving Overfitting under Pretrain-and-Finetune Paradigm
Oct 18, 2021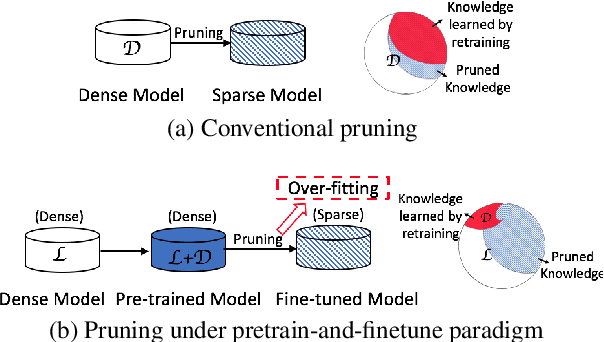
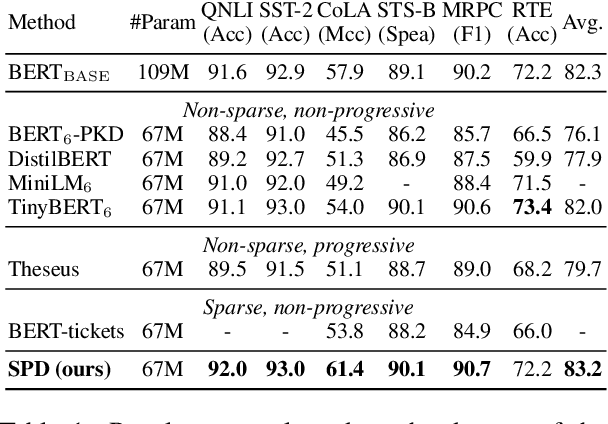
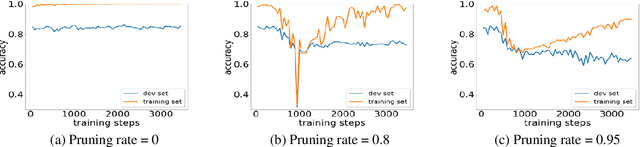
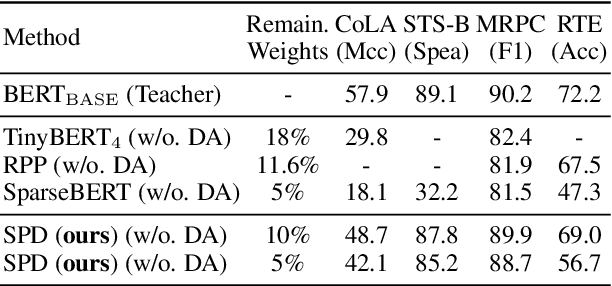
Various pruning approaches have been proposed to reduce the footprint requirements of Transformer-based language models. Conventional wisdom is that pruning reduces the model expressiveness and thus is more likely to underfit than overfit compared to the original model. However, under the trending pretrain-and-finetune paradigm, we argue that pruning increases the risk of overfitting if pruning was performed at the fine-tuning phase, as it increases the amount of information a model needs to learn from the downstream task, resulting in relative data deficiency. In this paper, we aim to address the overfitting issue under the pretrain-and-finetune paradigm to improve pruning performance via progressive knowledge distillation (KD) and sparse pruning. Furthermore, to mitigate the interference between different strategies of learning rate, pruning and distillation, we propose a three-stage learning framework. We show for the first time that reducing the risk of overfitting can help the effectiveness of pruning under the pretrain-and-finetune paradigm. Experiments on multiple datasets of GLUE benchmark show that our method achieves highly competitive pruning performance over the state-of-the-art competitors across different pruning ratio constraints.