 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaitSTR: Gait Recognition with Sequential Two-stream Refinement
Apr 02, 2024
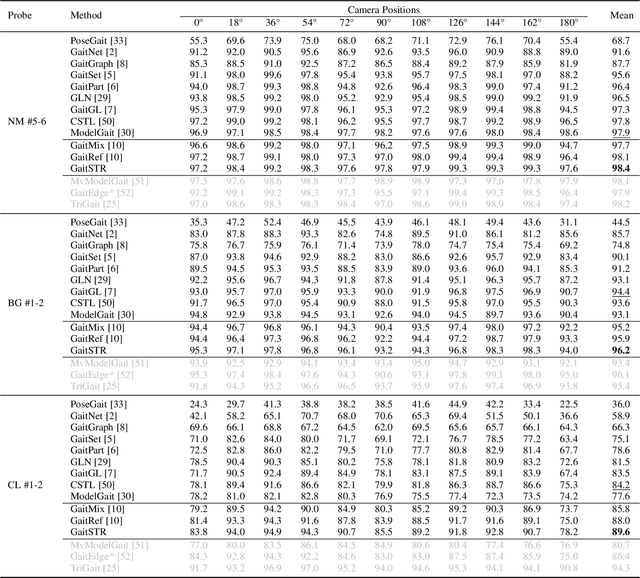

Gait recognition aims to identify a person based on their walking sequences, serving as a useful biometric modality as it can be observed from long distances without requiring cooperation from the subject. In representing a person's walking sequence, silhouettes and skeletons are the two primary modalities used. Silhouette sequences lack detailed part information when overlapping occurs between different body segments and are affected by carried objects and clothing. Skeletons, comprising joints and bones connecting the joints, provide more accurate part information for different segments; however, they are sensitive to occlusions and low-quality images, causing inconsistencies in frame-wise results within a sequence. In this paper, we explore the use of a two-stream representation of skeletons for gait recognition, alongside silhouettes. By fusing the combined data of silhouettes and skeletons, we refine the two-stream skeletons, joints, and bones through self-correction in graph convolution, along with cross-modal correction with temporal consistency from silhouettes. We demonstrate that with refined skeletons, the performance of the gait recognition model can achieve further improvement on public gait recognition datasets compared with state-of-the-art methods without extra annotations.
Large Language Models are Good Prompt Learners for Low-Shot Image Classification
Dec 07, 2023



Low-shot image classification, where training images are limited or inaccessible, has benefited from recent progress on pre-trained vision-language (VL) models with strong generalizability, e.g. CLIP. Prompt learning methods built with VL models generate text features from the class names that only have confined class-specific information. Large Language Models (LLMs), with their vast encyclopedic knowledge, emerge as the complement. Thus, in this paper, we discuss the integration of LLMs to enhance pre-trained VL models, specifically on low-shot classification. However, the domain gap between language and vision blocks the direct application of LLMs. Thus, we propose LLaMP, Large Language Models as Prompt learners, that produces adaptive prompts for the CLIP text encoder, establishing it as the connecting bridge. Experiments show that, compared with other state-of-the-art prompt learning methods, LLaMP yields better performance on both zero-shot generalization and few-shot image classification, over a spectrum of 11 datasets.
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Dec 01, 2023
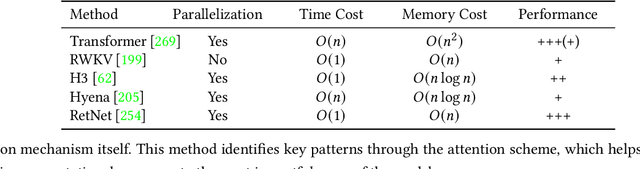
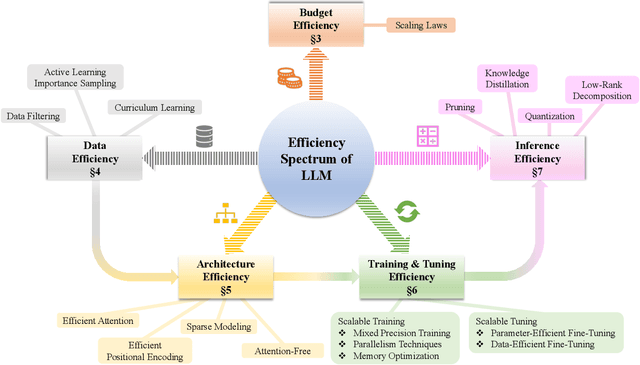
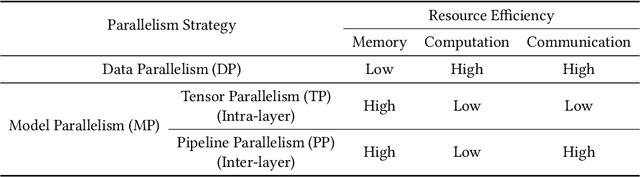
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.
CaesarNeRF: Calibrated Semantic Representation for Few-shot Generalizable Neural Rendering
Nov 27, 2023



Generalizability and few-shot learning are key challenges in Neural Radiance Fields (NeRF), often due to the lack of a holistic understanding in pixel-level rendering. We introduce CaesarNeRF, an end-to-end approach that leverages scene-level CAlibratEd SemAntic Representation along with pixel-level representations to advance few-shot, generalizable neural rendering, facilitating a holistic understanding without compromising high-quality details. CaesarNeRF explicitly models pose differences of reference views to combine scene-level semantic representations, providing a calibrated holistic understanding. This calibration process aligns various viewpoints with precise location and is further enhanced by sequential refinement to capture varying details. Extensive experiments on public datasets, including LLFF, Shiny, mip-NeRF 360, and MVImgNet, show that CaesarNeRF delivers state-of-the-art performance across varying numbers of reference views, proving effective even with a single reference image. The project page of this work can be found at https://haidongz-usc.github.io/project/caesarnerf.
ShARc: Shape and Appearance Recognition for Person Identification In-the-wild
Oct 24, 2023
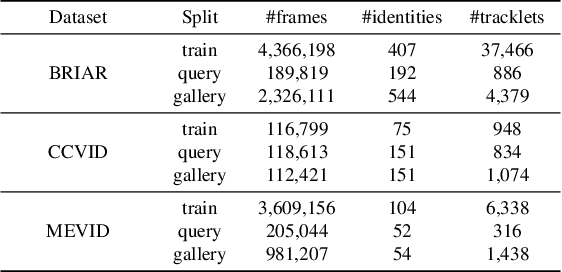
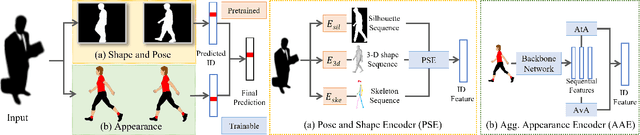
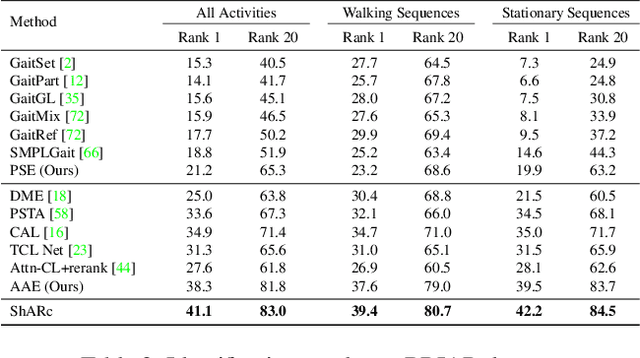
Identifying individuals in unconstrained video settings is a valuable yet challenging task in biometric analysis due to variations in appearances, environments, degradations, and occlusions. In this paper, we present ShARc, a multimodal approach for video-based person identification in uncontrolled environments that emphasizes 3-D body shape, pose, and appearance. We introduce two encoders: a Pose and Shape Encoder (PSE) and an Aggregated Appearance Encoder (AAE). PSE encodes the body shape via binarized silhouettes, skeleton motions, and 3-D body shape, while AAE provides two levels of temporal appearance feature aggregation: attention-based feature aggregation and averaging aggregation. For attention-based feature aggregation, we employ spatial and temporal attention to focus on key areas for person distinction. For averaging aggregation, we introduce a novel flattening layer after averaging to extract more distinguishable information and reduce overfitting of attention. We utilize centroid feature averaging for gallery registration. We demonstrate significant improvements over existing state-of-the-art methods on public datasets, including CCVID, MEVID, and BRIAR.
CAILA: Concept-Aware Intra-Layer Adapters for Compositional Zero-Shot Learning
May 26, 2023



Compositionality, the ability to combine existing concepts and generalize towards novel compositions, is a key functionality for intelligent entities. Here, we study the problem of Compositional Zero-Shot Learning (CZSL), which aims at recognizing novel attribute-object compositions. Recent approaches build their systems on top of large-scale Vision-Language Pre-trained (VLP) models, e.g. CLIP, and observe significant improvements. However, these methods treat CLIP as a black box and focus on pre- and post-CLIP operations. Here, we propose to dive deep into the architecture and insert adapters, a parameter-efficient technique proven to be effective among large language models, to each CLIP encoder layer. We further equip adapters with concept awareness so that concept-specific features of "object", "attribute" and "composition" can be extracted. We name our method CAILA, Concept-Aware Intra-Layer Adapters. Quantitative evaluations performed on three popular CZSL datasets, MIT-States, C-GQA, and UT-Zappos, reveal that CAILA achieves double-digit relative improvements against the current state-of-the-art on all benchmarks.
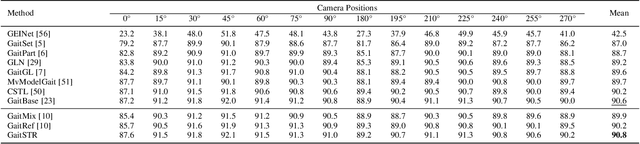
GaitRef: Gait Recognition with Refined Sequential Skeletons
Apr 16, 2023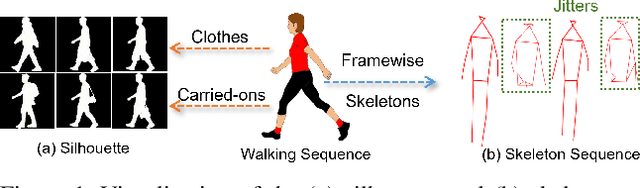


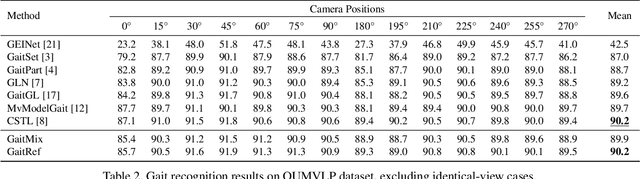
Identifying humans with their walking sequences, known as gait recognition, is a useful biometric understanding task as it can be observed from a long distance and does not require cooperation from the subject. Two common modalities used for representing the walking sequence of a person are silhouettes and joint skeletons. Silhouette sequences, which record the boundary of the walking person in each frame, may suffer from the variant appearances from carried-on objects and clothes of the person. Framewise joint detections are noisy and introduce some jitters that are not consistent with sequential detections. In this paper, we combine the silhouettes and skeletons and refine the framewise joint predictions for gait recognition. With temporal information from the silhouette sequences. We show that the refined skeletons can improve gait recognition performance without extra annotations. We compare our methods on four public datasets, CASIA-B, OUMVLP, Gait3D and GREW, and show state-of-the-art performance.
CAT-NeRF: Constancy-Aware Tx$^2$Former for Dynamic Body Modeling
Apr 16, 2023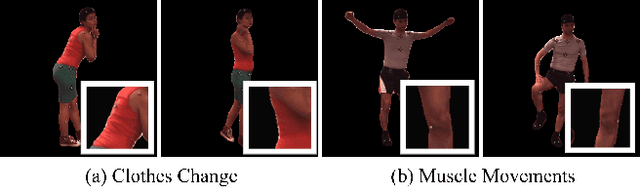
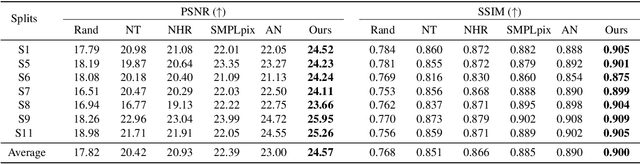
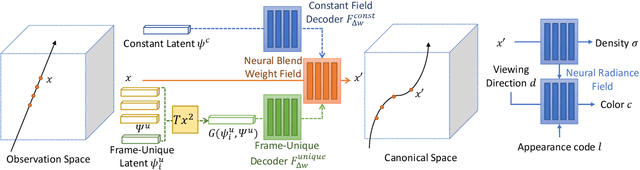
This paper addresses the problem of human rendering in the video with temporal appearance constancy. Reconstructing dynamic body shapes with volumetric neural rendering methods, such as NeRF, requires finding the correspondence of the points in the canonical and observation space, which demands understanding human body shape and motion. Some methods use rigid transformation, such as SE(3), which cannot precisely model each frame's unique motion and muscle movements. Others generate the transformation for each frame with a trainable network, such as neural blend weight field or translation vector field, which does not consider the appearance constancy of general body shape. In this paper, we propose CAT-NeRF for self-awareness of appearance constancy with Tx$^2$Former, a novel way to combine two Transformer layers, to separate appearance constancy and uniqueness. Appearance constancy models the general shape across the video, and uniqueness models the unique patterns for each frame. We further introduce a novel Covariance Loss to limit the correlation between each pair of appearance uniquenesses to ensure the frame-unique pattern is maximally captured in appearance uniqueness. We assess our method on H36M and ZJU-MoCap and show state-of-the-art performance.
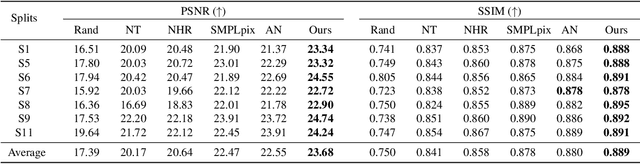
Gait Recognition Using 3-D Human Body Shape Inference
Dec 18, 2022Gait recognition, which identifies individuals based on their walking patterns, is an important biometric technique since it can be observed from a distance and does not require the subject's cooperation. Recognizing a person's gait is difficult because of the appearance variants in human silhouette sequences produced by varying viewing angles, carrying objects, and clothing. Recent research has produced a number of ways for coping with these variants. In this paper, we present the usage of inferring 3-D body shapes distilled from limited images, which are, in principle, invariant to the specified variants. Inference of 3-D shape is a difficult task, especially when only silhouettes are provided in a dataset. We provide a method for learning 3-D body inference from silhouettes by transferring knowledge from 3-D shape prior from RGB photos. We use our method on multiple existing state-of-the-art gait baselines and obtain consistent improvements for gait identification on two public datasets, CASIA-B and OUMVLP, on several variants and settings, including a new setting of novel views not seen during training.
Utilizing Every Image Object for Semi-supervised Phrase Grounding
Nov 05, 2020
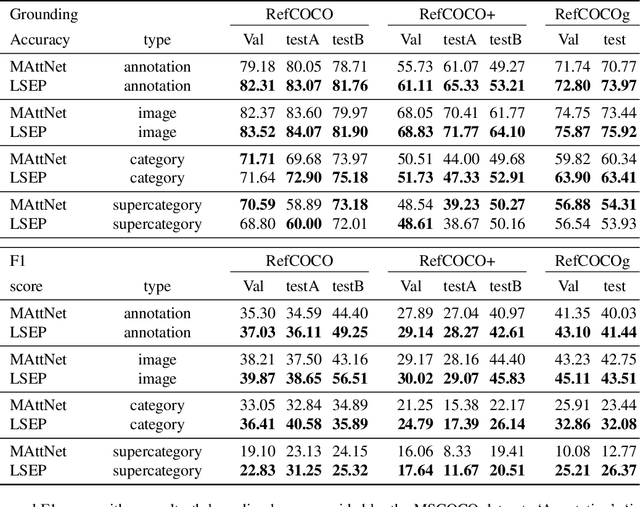


Phrase grounding models localize an object in the image given a referring expression. The annotated language queries available during training are limited, which also limits the variations of language combinations that a model can see during training. In this paper, we study the case applying objects without labeled queries for training the semi-supervised phrase grounding. We propose to use learned location and subject embedding predictors (LSEP) to generate the corresponding language embeddings for objects lacking annotated queries in the training set. With the assistance of the detector, we also apply LSEP to train a grounding model on images without any annotation. We evaluate our method based on MAttNet on three public datasets: RefCOCO, RefCOCO+, and RefCOCOg. We show that our predictors allow the grounding system to learn from the objects without labeled queries and improve accuracy by 34.9\% relatively with the detection results.