 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Every Image Object for Semi-supervised Phrase Grounding
Paper and Code
Nov 05, 2020
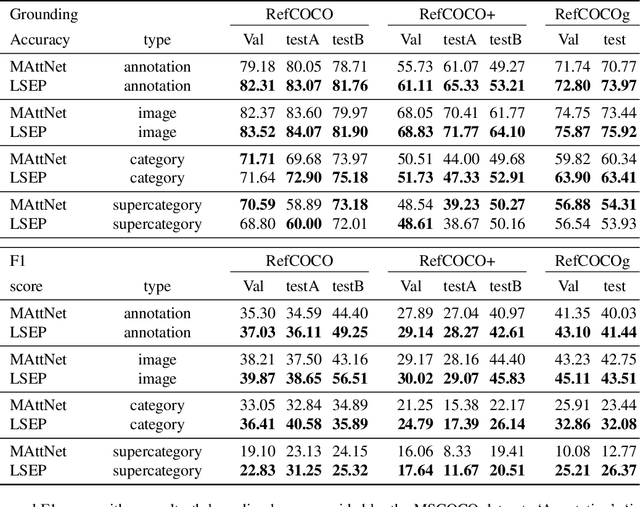


Phrase grounding models localize an object in the image given a referring expression. The annotated language queries available during training are limited, which also limits the variations of language combinations that a model can see during training. In this paper, we study the case applying objects without labeled queries for training the semi-supervised phrase grounding. We propose to use learned location and subject embedding predictors (LSEP) to generate the corresponding language embeddings for objects lacking annotated queries in the training set. With the assistance of the detector, we also apply LSEP to train a grounding model on images without any annotation. We evaluate our method based on MAttNet on three public datasets: RefCOCO, RefCOCO+, and RefCOCOg. We show that our predictors allow the grounding system to learn from the objects without labeled queries and improve accuracy by 34.9\% relatively with the detection results.