 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Very Long Video Understanding
Jan 26, 2026The advent of always-on personal AI assistants, enabled by all-day wearable devices such as smart glasses, demands a new level of contextual understanding, one that goes beyond short, isolated events to encompass the continuous, longitudinal stream of egocentric video. Achieving this vision requires advances in long-horizon video understanding, where systems must interpret and recall visual and audio information spanning days or even weeks. Existing methods, including large language models and retrieval-augmented generation, are constrained by limited context windows and lack the ability to perform compositional, multi-hop reasoning over very long video streams. In this work, we address these challenges through EGAgent, an enhanced agentic framework centered on entity scene graphs, which represent people, places, objects, and their relationships over time. Our system equips a planning agent with tools for structured search and reasoning over these graphs, as well as hybrid visual and audio search capabilities, enabling detailed, cross-modal, and temporally coherent reasoning. Experiments on the EgoLifeQA and Video-MME (Long) datasets show that our method achieves state-of-the-art performance on EgoLifeQA (57.5%) and competitive performance on Video-MME (Long) (74.1%) for complex longitudinal video understanding tasks.
Improving Object Detection and Attribute Recognition by Feature Entanglement Reduction
Aug 25, 2021
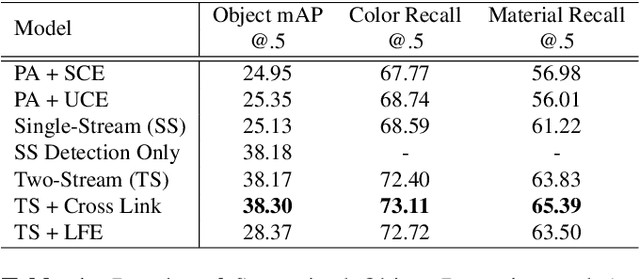
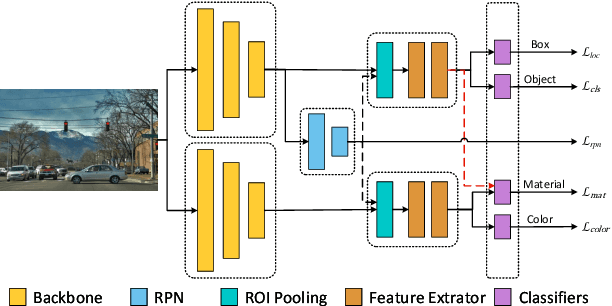
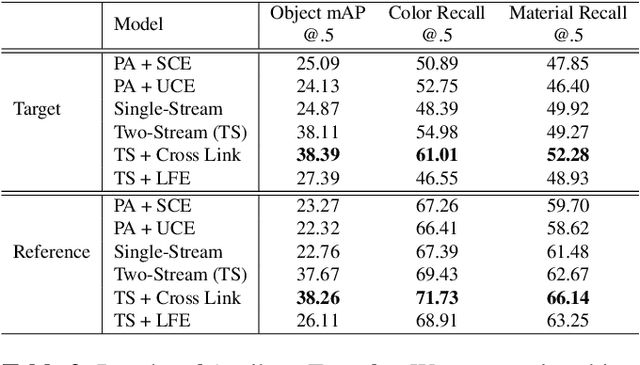
We explore object detection with two attributes: color and material. The task aims to simultaneously detect objects and infer their color and material. A straight-forward approach is to add attribute heads at the very end of a usual object detection pipeline. However, we observe that the two goals are in conflict: Object detection should be attribute-independent and attributes be largely object-independent. Features computed by a standard detection network entangle the category and attribute features; we disentangle them by the use of a two-stream model where the category and attribute features are computed independently but the classification heads share Regions of Interest (RoIs). Compared with a traditional single-stream model, our model shows significant improvements over VG-20, a subset of Visual Genome, on both supervised and attribute transfer tasks.
Video Question Answering with Phrases via Semantic Roles
Apr 08, 2021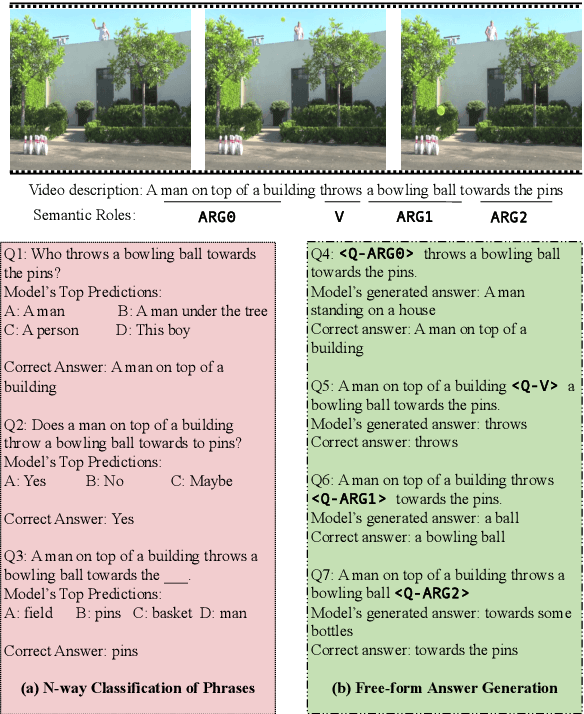


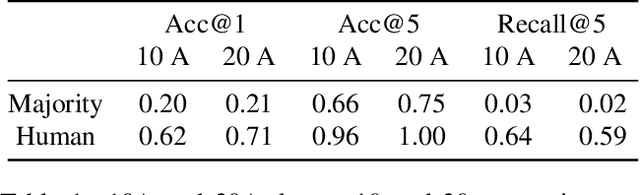
Video Question Answering (VidQA) evaluation metrics have been limited to a single-word answer or selecting a phrase from a fixed set of phrases. These metrics limit the VidQA models' application scenario. In this work, we leverage semantic roles derived from video descriptions to mask out certain phrases, to introduce VidQAP which poses VidQA as a fill-in-the-phrase task. To enable evaluation of answer phrases, we compute the relative improvement of the predicted answer compared to an empty string. To reduce the influence of language bias in VidQA datasets, we retrieve a video having a different answer for the same question. To facilitate research, we construct ActivityNet-SRL-QA and Charades-SRL-QA and benchmark them by extending three vision-language models. We further perform extensive analysis and ablative studies to guide future work.
Visual Semantic Role Labeling for Video Understanding
Apr 02, 2021
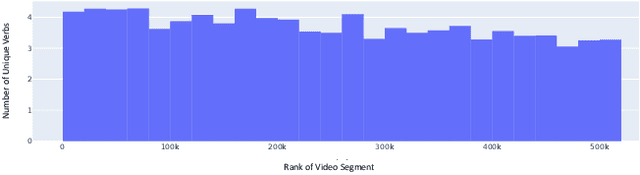

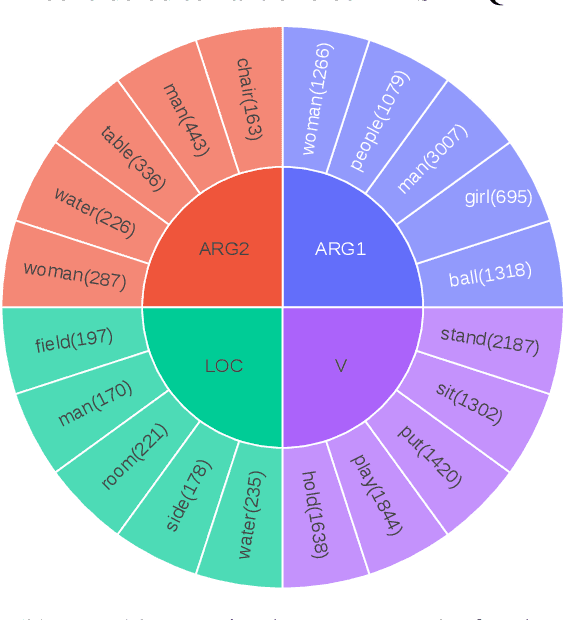
We propose a new framework for understanding and representing related salient events in a video using visual semantic role labeling. We represent videos as a set of related events, wherein each event consists of a verb and multiple entities that fulfill various roles relevant to that event. To study the challenging task of semantic role labeling in videos or VidSRL, we introduce the VidSitu benchmark, a large-scale video understanding data source with $29K$ $10$-second movie clips richly annotated with a verb and semantic-roles every $2$ seconds. Entities are co-referenced across events within a movie clip and events are connected to each other via event-event relations. Clips in VidSitu are drawn from a large collection of movies (${\sim}3K$) and have been chosen to be both complex (${\sim}4.2$ unique verbs within a video) as well as diverse (${\sim}200$ verbs have more than $100$ annotations each). We provide a comprehensive analysis of the dataset in comparison to other publicly available video understanding benchmarks, several illustrative baselines and evaluate a range of standard video recognition models. Our code and dataset is available at vidsitu.org.
Utilizing Every Image Object for Semi-supervised Phrase Grounding
Nov 05, 2020
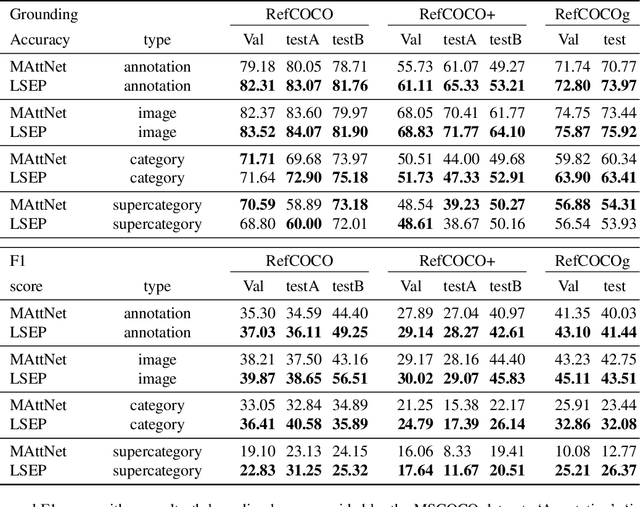


Phrase grounding models localize an object in the image given a referring expression. The annotated language queries available during training are limited, which also limits the variations of language combinations that a model can see during training. In this paper, we study the case applying objects without labeled queries for training the semi-supervised phrase grounding. We propose to use learned location and subject embedding predictors (LSEP) to generate the corresponding language embeddings for objects lacking annotated queries in the training set. With the assistance of the detector, we also apply LSEP to train a grounding model on images without any annotation. We evaluate our method based on MAttNet on three public datasets: RefCOCO, RefCOCO+, and RefCOCOg. We show that our predictors allow the grounding system to learn from the objects without labeled queries and improve accuracy by 34.9\% relatively with the detection results.
Video Object Grounding using Semantic Roles in Language Description
Mar 24, 2020



We explore the task of Video Object Grounding (VOG), which grounds objects in videos referred to in natural language descriptions. Previous methods apply image grounding based algorithms to address VOG, fail to explore the object relation information and suffer from limited generalization. Here, we investigate the role of object relations in VOG and propose a novel framework VOGNet to encode multi-modal object relations via self-attention with relative position encoding. To evaluate VOGNet, we propose novel contrasting sampling methods to generate more challenging grounding input samples, and construct a new dataset called ActivityNet-SRL (ASRL) based on existing caption and grounding datasets. Experiments on ASRL validate the need of encoding object relations in VOG, and our VOGNet outperforms competitive baselines by a significant margin.
Zero-Shot Grounding of Objects from Natural Language Queries
Aug 20, 2019
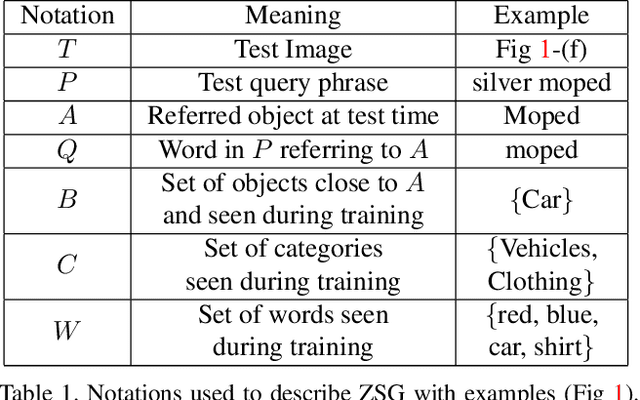
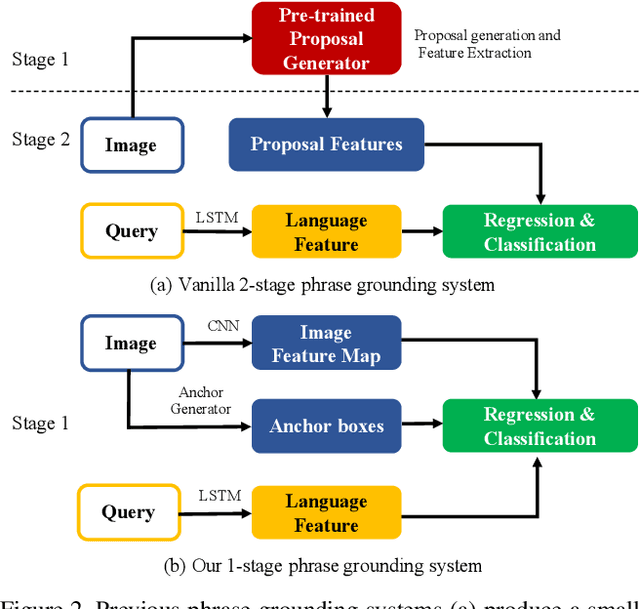
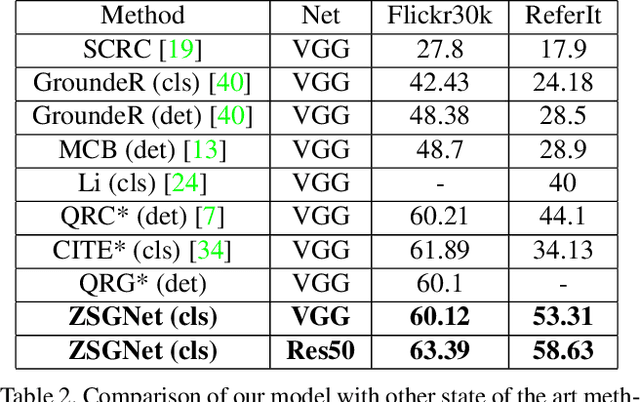
A phrase grounding system localizes a particular object in an image referred to by a natural language query. In previous work, the phrases were restricted to have nouns that were encountered in training, we extend the task to Zero-Shot Grounding(ZSG) which can include novel, "unseen" nouns. Current phrase grounding systems use an explicit object detection network in a 2-stage framework where one stage generates sparse proposals and the other stage evaluates them. In the ZSG setting, generating appropriate proposals itself becomes an obstacle as the proposal generator is trained on the entities common in the detection and grounding datasets. We propose a new single-stage model called ZSGNet which combines the detector network and the grounding system and predicts classification scores and regression parameters. Evaluation of ZSG system brings additional subtleties due to the influence of the relationship between the query and learned categories; we define four distinct conditions that incorporate different levels of difficulty. We also introduce new datasets, sub-sampled from Flickr30k Entities and Visual Genome, that enable evaluations for the four conditions. Our experiments show that ZSGNet achieves state-of-the-art performance on Flickr30k and ReferIt under the usual "seen" settings and performs significantly better than baseline in the zero-shot setting.