 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaitRef: Gait Recognition with Refined Sequential Skeletons
Paper and Code
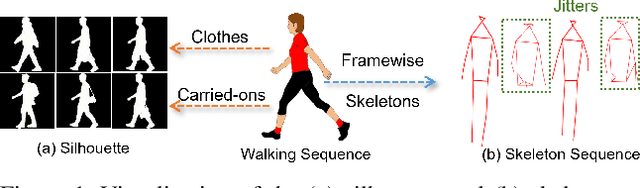


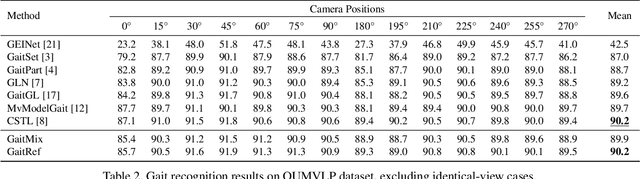
Identifying humans with their walking sequences, known as gait recognition, is a useful biometric understanding task as it can be observed from a long distance and does not require cooperation from the subject. Two common modalities used for representing the walking sequence of a person are silhouettes and joint skeletons. Silhouette sequences, which record the boundary of the walking person in each frame, may suffer from the variant appearances from carried-on objects and clothes of the person. Framewise joint detections are noisy and introduce some jitters that are not consistent with sequential detections. In this paper, we combine the silhouettes and skeletons and refine the framewise joint predictions for gait recognition. With temporal information from the silhouette sequences. We show that the refined skeletons can improve gait recognition performance without extra annotations. We compare our methods on four public datasets, CASIA-B, OUMVLP, Gait3D and GREW, and show state-of-the-art performance.