 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaitSTR: Gait Recognition with Sequential Two-stream Refinement
Apr 02, 2024
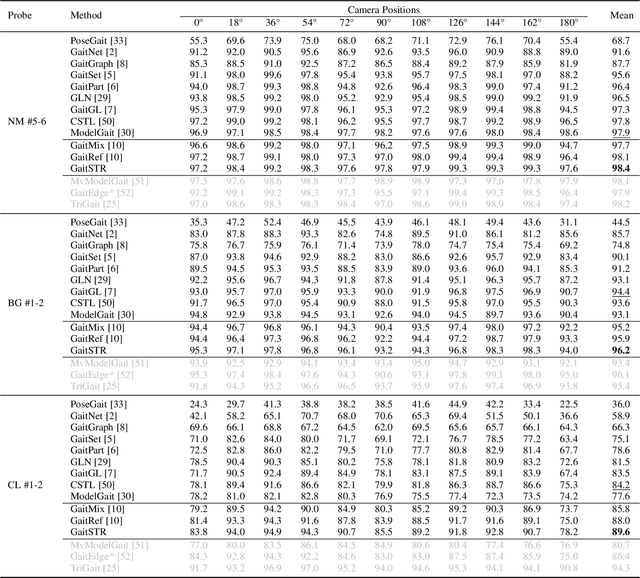

Gait recognition aims to identify a person based on their walking sequences, serving as a useful biometric modality as it can be observed from long distances without requiring cooperation from the subject. In representing a person's walking sequence, silhouettes and skeletons are the two primary modalities used. Silhouette sequences lack detailed part information when overlapping occurs between different body segments and are affected by carried objects and clothing. Skeletons, comprising joints and bones connecting the joints, provide more accurate part information for different segments; however, they are sensitive to occlusions and low-quality images, causing inconsistencies in frame-wise results within a sequence. In this paper, we explore the use of a two-stream representation of skeletons for gait recognition, alongside silhouettes. By fusing the combined data of silhouettes and skeletons, we refine the two-stream skeletons, joints, and bones through self-correction in graph convolution, along with cross-modal correction with temporal consistency from silhouettes. We demonstrate that with refined skeletons, the performance of the gait recognition model can achieve further improvement on public gait recognition datasets compared with state-of-the-art methods without extra annotations.
ShARc: Shape and Appearance Recognition for Person Identification In-the-wild
Oct 24, 2023
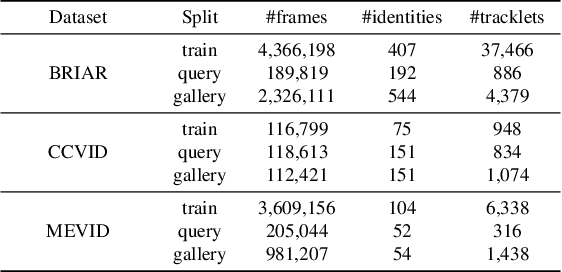
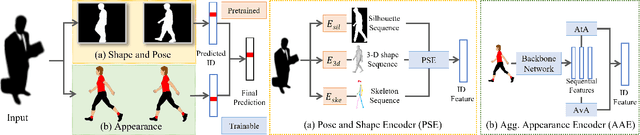
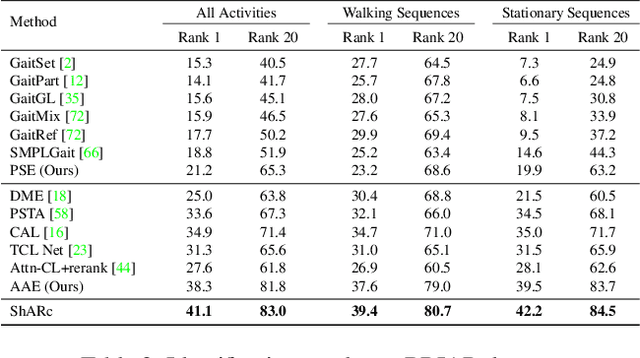
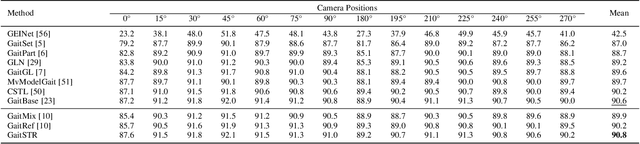
Identifying individuals in unconstrained video settings is a valuable yet challenging task in biometric analysis due to variations in appearances, environments, degradations, and occlusions. In this paper, we present ShARc, a multimodal approach for video-based person identification in uncontrolled environments that emphasizes 3-D body shape, pose, and appearance. We introduce two encoders: a Pose and Shape Encoder (PSE) and an Aggregated Appearance Encoder (AAE). PSE encodes the body shape via binarized silhouettes, skeleton motions, and 3-D body shape, while AAE provides two levels of temporal appearance feature aggregation: attention-based feature aggregation and averaging aggregation. For attention-based feature aggregation, we employ spatial and temporal attention to focus on key areas for person distinction. For averaging aggregation, we introduce a novel flattening layer after averaging to extract more distinguishable information and reduce overfitting of attention. We utilize centroid feature averaging for gallery registration. We demonstrate significant improvements over existing state-of-the-art methods on public datasets, including CCVID, MEVID, and BRIAR.
GaitRef: Gait Recognition with Refined Sequential Skeletons
Apr 16, 2023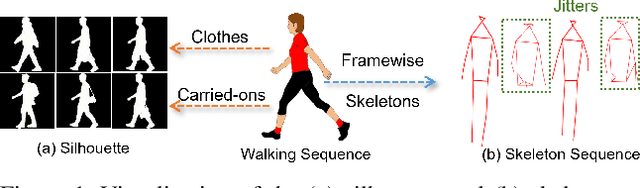


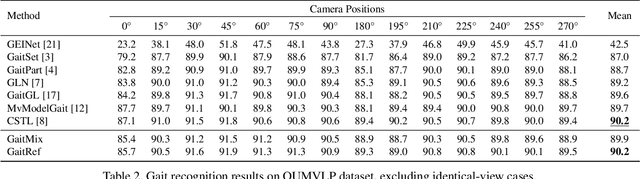
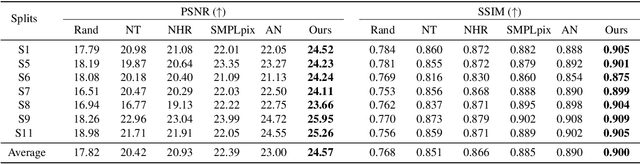
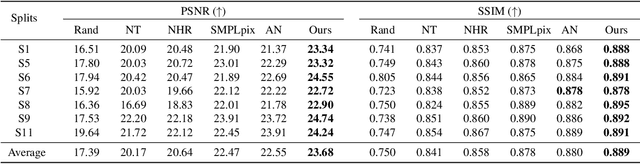
Identifying humans with their walking sequences, known as gait recognition, is a useful biometric understanding task as it can be observed from a long distance and does not require cooperation from the subject. Two common modalities used for representing the walking sequence of a person are silhouettes and joint skeletons. Silhouette sequences, which record the boundary of the walking person in each frame, may suffer from the variant appearances from carried-on objects and clothes of the person. Framewise joint detections are noisy and introduce some jitters that are not consistent with sequential detections. In this paper, we combine the silhouettes and skeletons and refine the framewise joint predictions for gait recognition. With temporal information from the silhouette sequences. We show that the refined skeletons can improve gait recognition performance without extra annotations. We compare our methods on four public datasets, CASIA-B, OUMVLP, Gait3D and GREW, and show state-of-the-art performance.
CAT-NeRF: Constancy-Aware Tx$^2$Former for Dynamic Body Modeling
Apr 16, 2023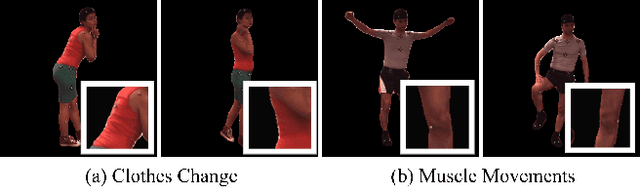
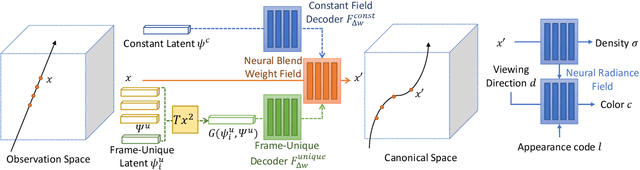
This paper addresses the problem of human rendering in the video with temporal appearance constancy. Reconstructing dynamic body shapes with volumetric neural rendering methods, such as NeRF, requires finding the correspondence of the points in the canonical and observation space, which demands understanding human body shape and motion. Some methods use rigid transformation, such as SE(3), which cannot precisely model each frame's unique motion and muscle movements. Others generate the transformation for each frame with a trainable network, such as neural blend weight field or translation vector field, which does not consider the appearance constancy of general body shape. In this paper, we propose CAT-NeRF for self-awareness of appearance constancy with Tx$^2$Former, a novel way to combine two Transformer layers, to separate appearance constancy and uniqueness. Appearance constancy models the general shape across the video, and uniqueness models the unique patterns for each frame. We further introduce a novel Covariance Loss to limit the correlation between each pair of appearance uniquenesses to ensure the frame-unique pattern is maximally captured in appearance uniqueness. We assess our method on H36M and ZJU-MoCap and show state-of-the-art performance.
ESAN: Efficient Sentiment Analysis Network of A-Shares Research Reports for Stock Price Prediction
Dec 03, 2021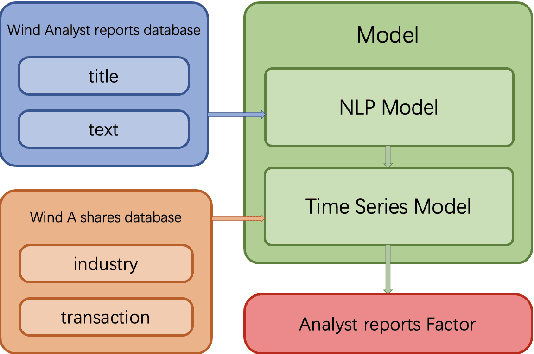
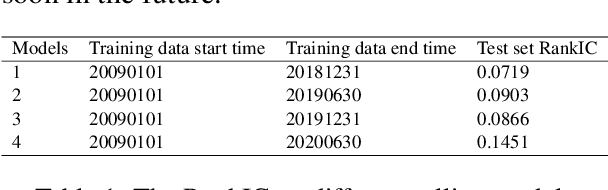
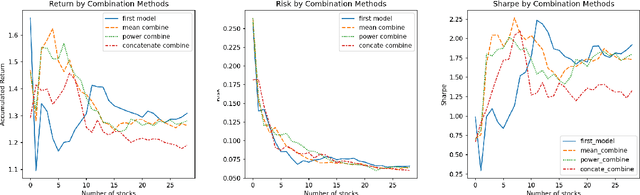
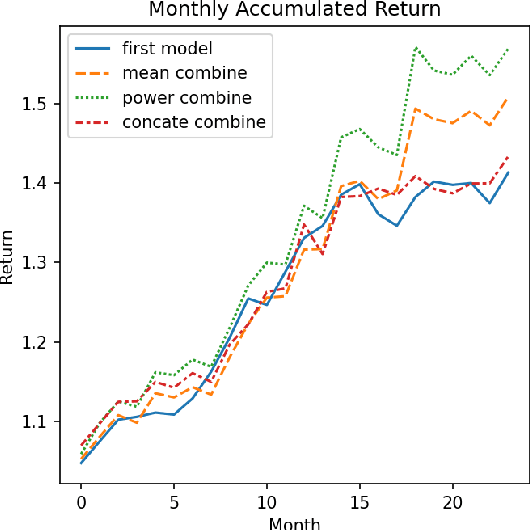
In this paper, we are going to develop a natural language processing model to help us to predict stocks in the long term. The whole network includes two modules. The first module is a natural language processing model which seeks out reliable factors from input reports. While the other is a time-series forecasting model which takes the factors as input and aims to predict stocks earnings yield. To indicate the efficiency of our model to combine the sentiment analysis module and the time-series forecasting module, we name our method ESAN.